By reimagining optical character recognition as inverse rendering, this new diffusion-based framework shatters the limitations of left-to-right text generation, delivering lightning-fast, hallucination-free document parsing.
- The Autoregressive Bottleneck: Current Vision-Language Models treat OCR like language generation, reading left-to-right. This causes slow processing times and compounding errors, as the models often guess text based on language patterns rather than actual visual evidence.
- A Paradigm Shift to Inverse Rendering: MinerU-Diffusion discards sequential decoding. By utilizing parallel diffusion denoising, it extracts text from documents as a holistic visual task, drastically reducing the system’s reliance on linguistic guesswork.
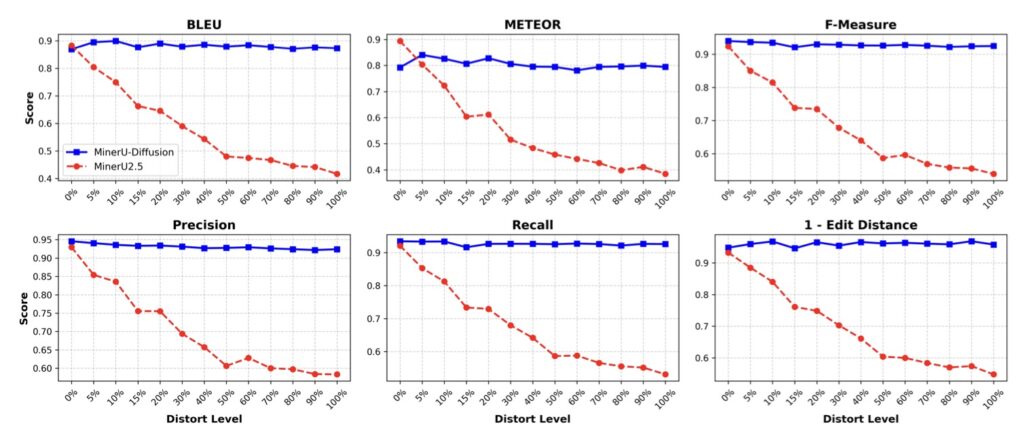
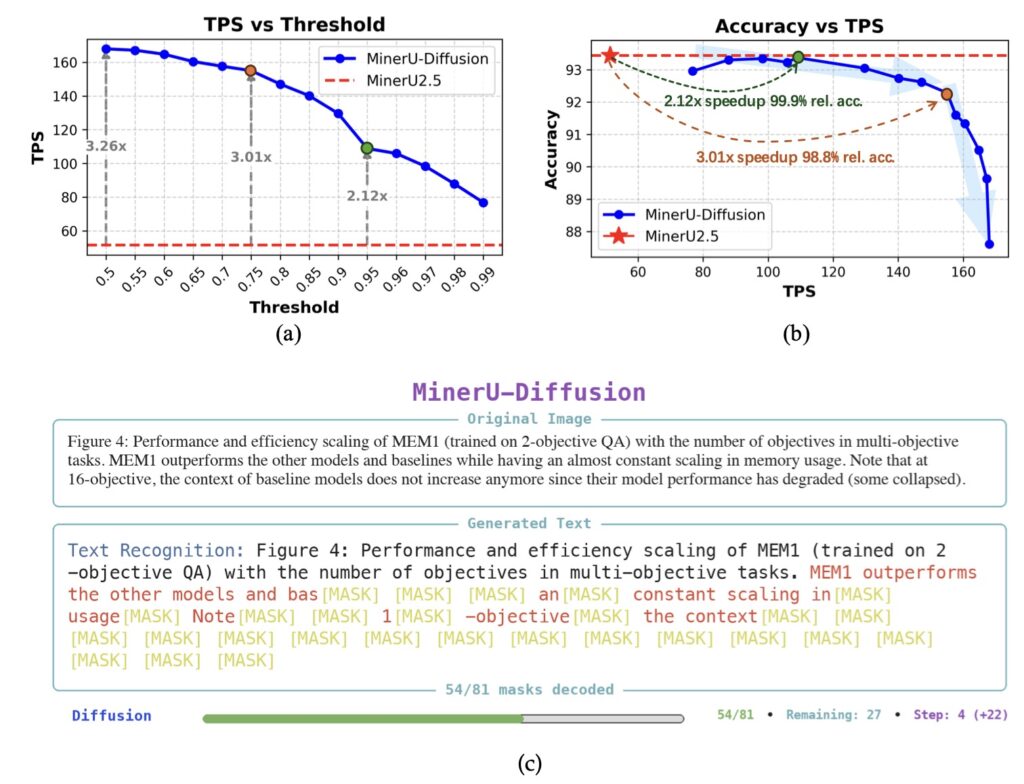
- Faster and Highly Robust: Powered by a 2.5-billion-parameter architecture, MinerU-Diffusion decodes complex documents up to 3.2 times faster than traditional baselines and maintains strict accuracy even when document semantics are intentionally scrambled.
The way machines read documents has undergone a massive transformation. Optical Character Recognition (OCR) is no longer just about transcribing simple, isolated lines of text; it has evolved into a complex demand for structured document parsing. Today, we expect AI to flawlessly digest long-form sequences laden with intricate layouts, dense data tables, and complex mathematical formulas. In recent years, Vision-Language Models (VLMs) have emerged as the dominant paradigm to meet this challenge. These systems encode document images into visual representations and generate structured text to make sense of the page. Yet, despite incredible scaling and architectural unifications, a fundamental flaw remains at the heart of how these models operate: they read strictly from left to right.
This left-to-right reading style, known as autoregressive (AR) decoding, introduces severe efficiency and reliability bottlenecks, especially when tackling long documents or highly structured scenarios like tables and formulas. The core issue lies in task formulation. A high-quality OCR system should, by definition, rely on authentic visual evidence—looking at the actual shapes of characters on a page. Autoregressive models, however, implicitly cast OCR as a language-conditioned reconstruction task. They act somewhat like an overeager autocomplete on your smartphone, generating textual outputs based heavily on linguistic priors. When the visual signals on a scanned document are weak, or when the semantic constraints are unusual, these models default to their language training. They begin to guess, over-relying on prior knowledge rather than what is actually printed, leading to semantic hallucinations and cumulative errors that cascade through the rest of the document.
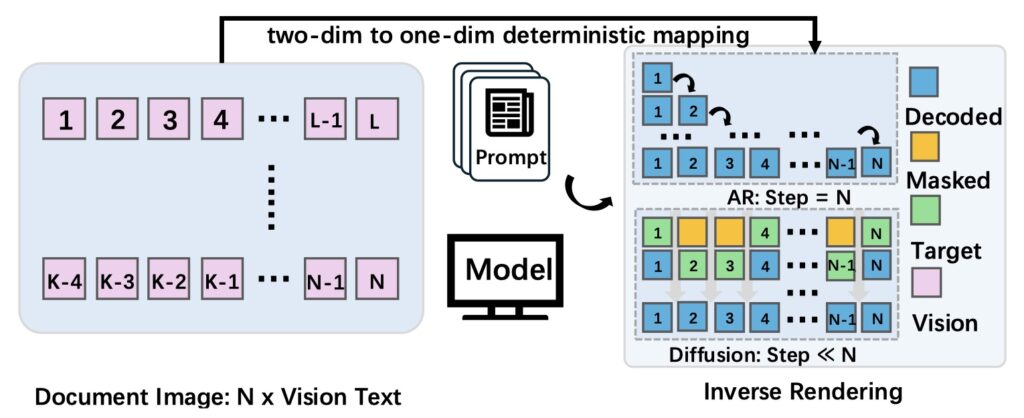
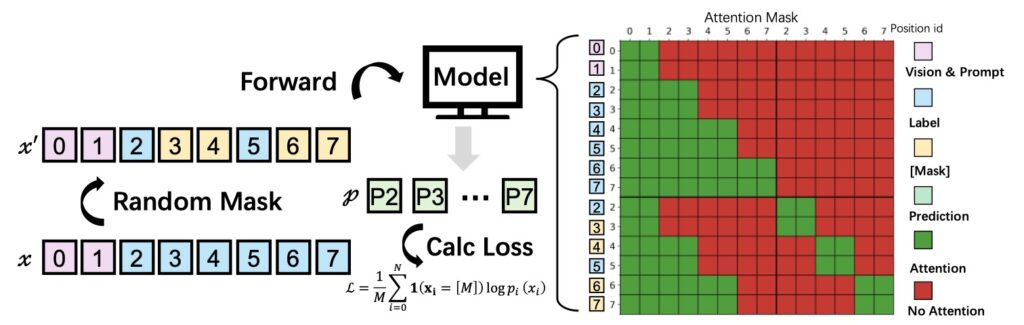
The researchers behind MinerU-Diffusion realized that this left-to-right causal generation is merely an artifact of serialization, not an intrinsic property of reading a document. To fix the problem, they proposed a radical shift in perspective: rethinking document OCR as an inverse rendering process. Instead of guessing the next word in a sequence, an OCR system should decode the visual information all at once. Motivated by this insight, they developed MinerU-Diffusion, a massive 2.5-billion-parameter framework that completely replaces traditional autoregressive sequential decoding with block-level parallel diffusion denoising under visual conditioning.

Beneath the hood, MinerU-Diffusion employs a block-wise diffusion decoder alongside a sophisticated, uncertainty-driven two-stage curriculum learning strategy. This unique training approach is crucial; it stabilizes the training process of the diffusion model while significantly enhancing boundary precision and robustness for long-sequence inference. By breaking the document down and denoising the text in parallel blocks, the model is forced to look at the visual data rather than lazily relying on the semantic context of the previous sentence.
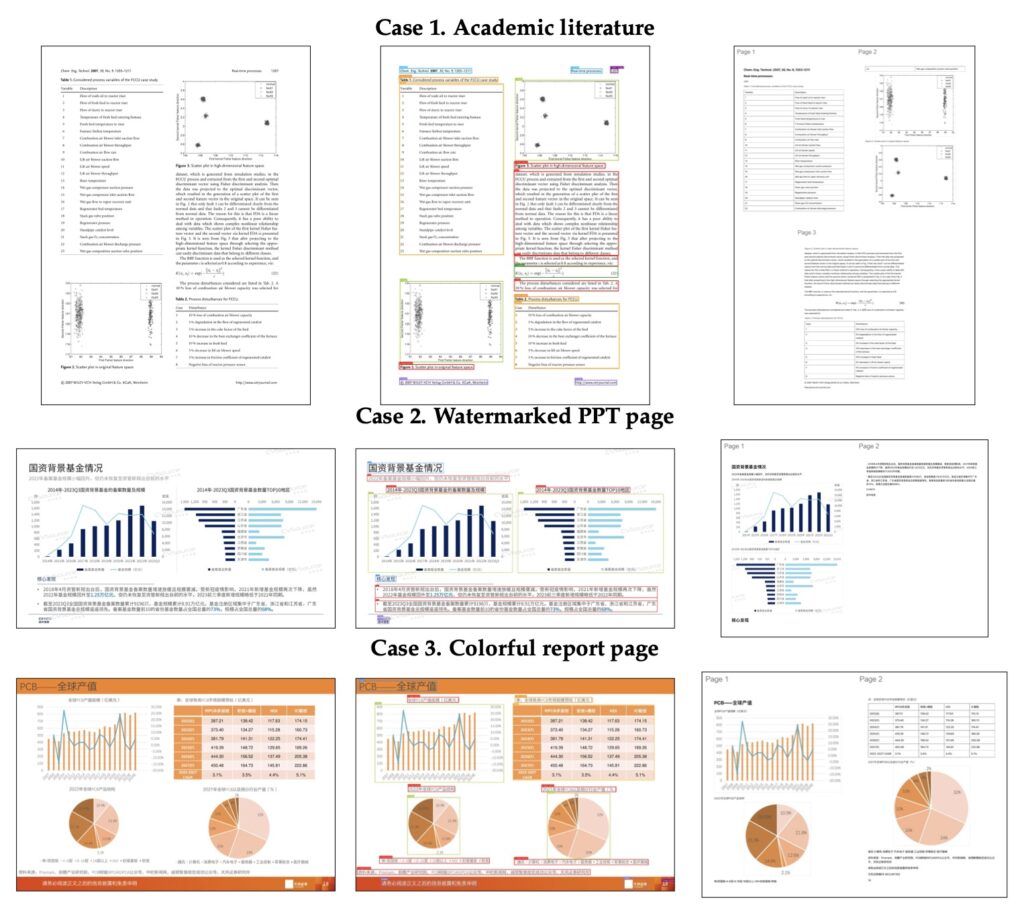
The results of this architectural shift are striking. Extensive experiments across document, table, and formula benchmarks demonstrate that MinerU-Diffusion consistently improves robustness while achieving decoding speeds up to 3.2 times faster than its autoregressive counterparts. To truly test the model’s resilience, researchers evaluated it on a novel “Semantic Shuffle” benchmark. By deliberately disrupting the semantic structure of the text, they proved that traditional AR-based systems suffer substantial performance degradation—highlighting their fragility. MinerU-Diffusion, on the other hand, stood strong. It confirmed a vastly reduced dependence on linguistic priors and showcased a much stronger, authentic visual OCR capability.

Ultimately, MinerU-Diffusion proves that we do not have to accept the latency and hallucinations inherent in sequential text generation. By treating the page as a visual canvas rather than a string of words waiting to be predicted, diffusion-based parallel decoding emerges as a highly promising alternative for the future of structured document parsing.