The A.T.L.A.S. project proves that the future of artificial intelligence isn’t just about massive datacenters—it’s about smarter, self-hosted infrastructure.
- The Breakthrough: A 22-year-old student built an open-source system that runs a 14-billion parameter AI model on a single $500 consumer GPU, beating frontier models like Claude Sonnet 4.5 on rigorous coding benchmarks.
- The Method: Instead of relying on brute compute, the system wraps a smaller “frozen” model in intelligent infrastructure—using self-verified repair and constraint-driven generation—to boost baseline performance by nearly 20 percentage points.
- The Impact: Operating entirely offline at a cost of just $0.004 per task, this project challenges the narrative that trillion-dollar datacenters are the only path to state-of-the-art AI, signaling a shift toward highly capable, democratized, and private local models.
For the past few years, the prevailing narrative in the tech industry has been one of scale: bigger models, massive power consumption, and endless construction of billion-dollar datacenters. We’ve been told that to achieve state-of-the-art AI capabilities, you need an enterprise-grade cloud budget. But what if brute-forcing our way to general intelligence isn’t the only option? If we can achieve frontier-level performance on consumer-grade hardware through smarter system architecture, it is only a matter of time before the world realizes that top-tier AI is vastly less expensive—and far more obtainable—than we’ve been led to believe.
Enter A.T.L.A.S., an open-source project operating on the bleeding edge of this possibility. Built by a 22-year-old college student from Virginia Tech, A.T.L.A.S. manages to run a 14-billion parameter AI model on a single $500 consumer graphics card. Yet, despite its modest hardware footprint, it scored an impressive 74.6% on the LiveCodeBench (evaluating 599 problems)—outperforming Claude Sonnet 4.5, which scored 71.4%.
The Magic is in the Infrastructure
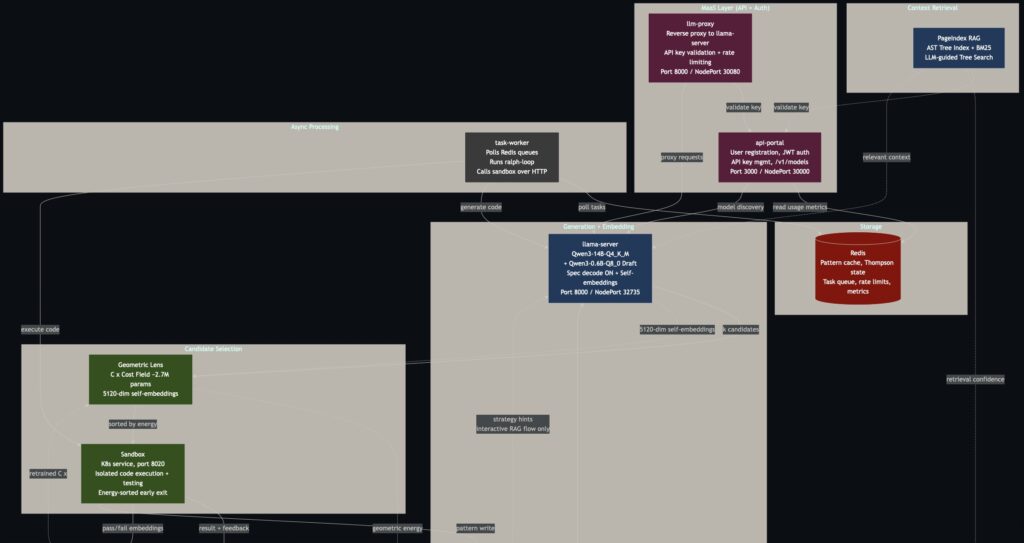
How does a small, locally hosted model punch so far above its weight class? The secret lies entirely in system design. The base model used in A.T.L.A.S. actually only scores about 55% out of the box. However, the surrounding pipeline adds nearly 20 percentage points of performance.
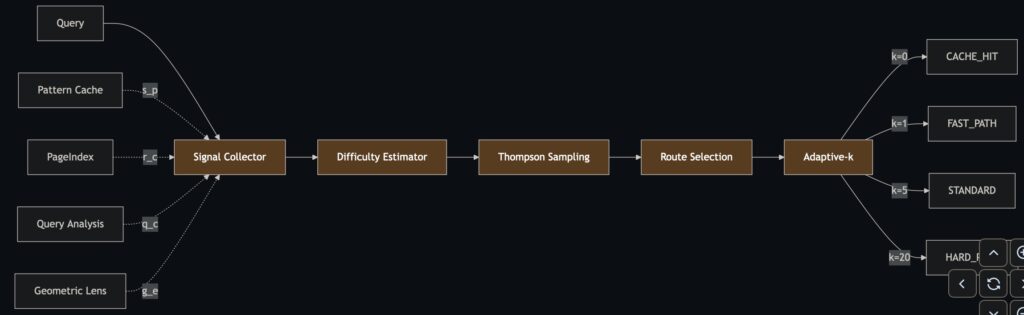
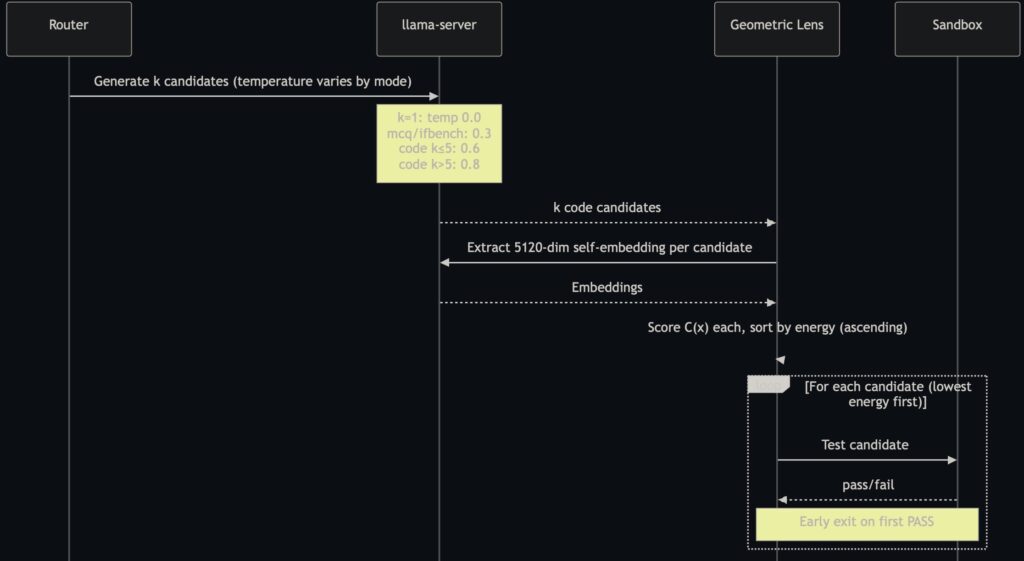
Instead of fine-tuning the model or relying on expensive API calls, A.T.L.A.S. wraps the “frozen” base model in an intelligent infrastructure pipeline. It utilizes constraint-driven generation, generating multiple solution approaches, testing them, and selecting the best one. When tasks fail, they enter a “Phase 3” where the model generates its own test cases and iteratively repairs its solutions via a process known as PR-CoT (Program Repair Chain-of-Thought). Real tests are only used for the final scoring.
The technical setup is equally lean. A single patched llama-server runs on K3s, providing generation with speculative decoding that achieves roughly 100 tokens per second. It also generates 5120-dimensional self-embeddings for scoring. The result is a fully self-hosted system: no data ever leaves the machine, no API keys are required, and there is no usage metering. The electricity cost to run this? A mere $0.004 per task.
Navigating the Growing Pains: A.T.L.A.S. V3 Limitations
While the LiveCodeBench (LCB) results are staggering, A.T.L.A.S. is still a heavily specialized tool with areas needing refinement. The current version, V3, was purpose-built and tuned specifically for LCB. Consequently, its performance on other benchmarks like GPQA Diamond (47.0%) and SciCode (14.7%) shows that cross-domain generalization remains a challenge.
Furthermore, several of the system’s more ambitious mathematical architectures are currently underperforming or dormant:
- Undertrained Geometric Lens: Phase 2 routing, powered by a Geometric Lens C(x) energy field, contributed essentially +0.0 percentage points to the current build. The lens was supposed to select the best candidates (achieving 87.8% accuracy on mixed-result tasks), but it was retrained on a dataset of only about 60 samples. This was far too small to learn a meaningful energy landscape, leaving the lens unable to properly discriminate candidates.
- Dormant Metric Tensor: The G(x) metric tensor, which applies corrections to the gradient signal of C(x), is completely dormant. Because C(x) is producing a noisy energy landscape, G(x) has no meaningful geometry to navigate. As a result, the correction term Δx=−G−1∇C currently contributes nothing to the system.
- Pipeline Bottlenecks: The task pipeline is currently single-threaded, processing tasks sequentially, and a standard input/output (stdio) handling bug in the SandboxAdapter has broken certain input tiebreaking functions.
What’s Coming in V3.1
The developer is actively addressing these hurdles in the upcoming V3.1 release, which promises to transform A.T.L.A.S. from a specialized coding tool into a faster, more generalized powerhouse.
The biggest shift will be a model swap: moving from Qwen3-14B to the newer Qwen3.5-9B featuring a DeltaNet linear attention architecture. This smaller model frees up valuable VRAM headroom while utilizing native multi-token prediction (MTP) to deliver a massive 3-4x throughput improvement at comparable or better accuracy.

Additionally, V3.1 will introduce task-level parallelization for radically faster benchmark runs and fix the glaring SandboxAdapter bug. The mathematical backbone is also getting an overhaul: the Geometric Lens will feature online C(x) recalibration—updating based on benchmark feedback rather than remaining static—and will be retrained on a properly sized self-embedding dataset. Meanwhile, the dormant G(x) metric tensor is being redesigned from the ground up, with the possibility of being removed entirely if further research demands it.
A.T.L.A.S. is more than just an impressive benchmark score; it is a proof of concept for the future of the industry. It proves that by prioritizing smarter infrastructure and systems design over sheer datacenter scale, we can put the power of frontier AI onto the desks of anyone with a consumer GPU.