Google DeepMind’s latest AI powerhouse delivers Apache 2.0 freedom, groundbreaking architecture, and out-of-the-box brilliance for developers everywhere.
- Truly Open and Accessible: Released under an Apache 2.0 license, Gemma 4 is available on Hugging Face and purpose-built for advanced reasoning and agentic workflows on the hardware you already own.
- Architectural Leap: Built on Gemini 3 technology, it introduces revolutionary features like Per-Layer Embeddings (PLE) and Shared KV Caches to maximize intelligence-per-parameter and efficiency.
- Unrivaled Out-of-the-Box Performance: From native JSON GUI detection to video comprehension and flawless function calling, the models perform so well natively that developers are struggling to find reasons to fine-tune them.
The artificial intelligence landscape just experienced a seismic shift. Google DeepMind has officially unveiled the Gemma 4 family of multimodal models, and it is nothing short of a game-changer. Deployed straight to Hugging Face and fully open under the permissive Apache 2.0 license, Gemma 4 is built for developers who want to run highly intelligent, agentic workflows right on their own hardware. Listening closely to invaluable community feedback, DeepMind has leveraged the cutting-edge research behind Gemini 3 to create a model that punches far above its weight class, maximizing intelligence for every single parameter.

What makes this release truly remarkable is its sheer quality right out of the box. The models are hitting Pareto frontier arena scores, proving that you don’t need a massive closed-source API to get top-tier results. In fact, early testers working with pre-release checkpoints reported a rather unique “problem”: the base models are so incredibly capable that finding good examples to justify fine-tuning has become a struggle. From day one, Gemma 4 is ready to slot into your favorite tools, boasting widespread compatibility with transformers, llama.cpp, MLX, WebGPU, and Rust.
What is New Under the Hood?
Like its predecessor Gemma-3n, Gemma 4 is a true polymath, effortlessly handling image, text, and audio inputs while generating crisp text responses. However, it takes giant strides forward in how it processes this data. The text decoder has been supercharged for long context windows, and the image encoder now boasts two crucial upgrades: it supports variable aspect ratios and allows for a configurable number of image token inputs. This means developers can finally find their perfect “sweet spot” balancing speed, memory, and output quality. While all models in the family support image, video, and text inputs, the smaller, highly agile variants—specifically the E2B and E4B models—also boast robust audio support.
Architecturally, Gemma 4 is a masterclass in streamlined efficiency. DeepMind consciously left out complex, inconclusive features like Altup, opting instead for a highly compatible mix designed for speed, long context, and quantization. It utilizes alternating local sliding-window attention (512 tokens for smaller dense models, 1024 for larger ones) alongside global full-context attention layers. This is paired with Dual RoPE configurations—standard RoPE for sliding layers and proportional RoPE for global ones—to flawlessly manage long contexts. The efficiency is further amplified by a Shared KV Cache, where the final layers of the model reuse key-value states from earlier layers. This eliminates redundant projections, saving both compute and memory without sacrificing quality.
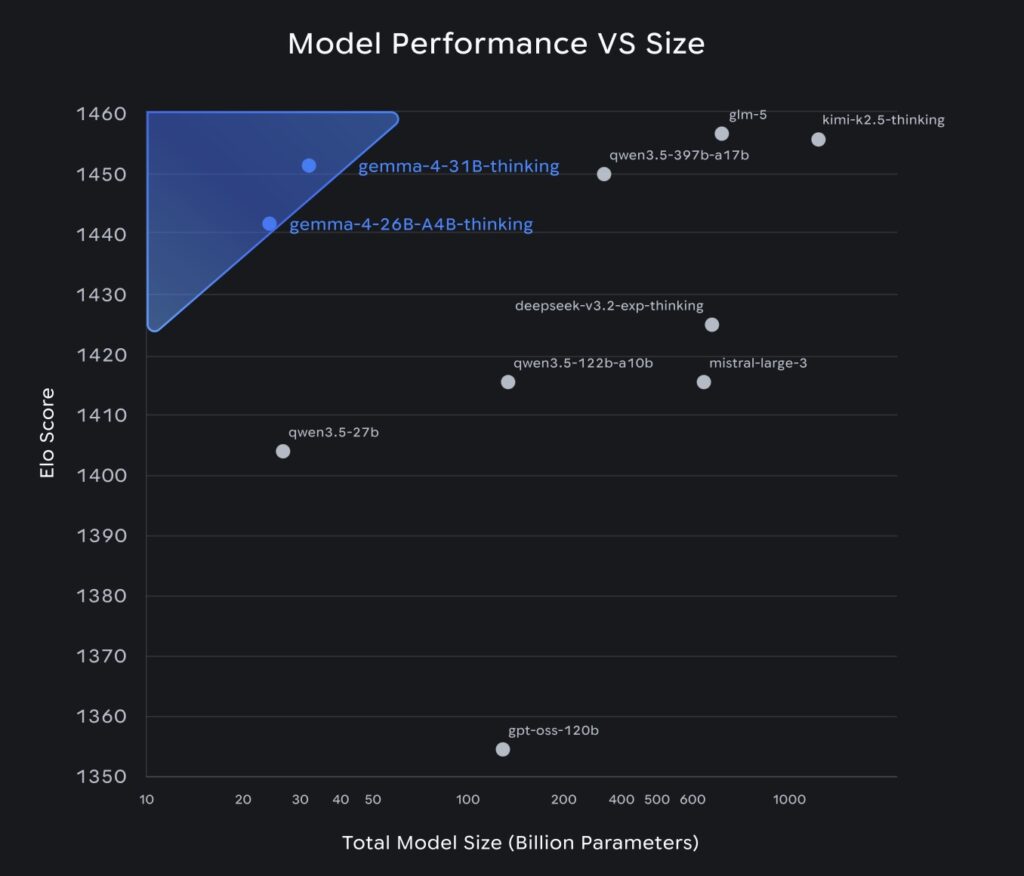
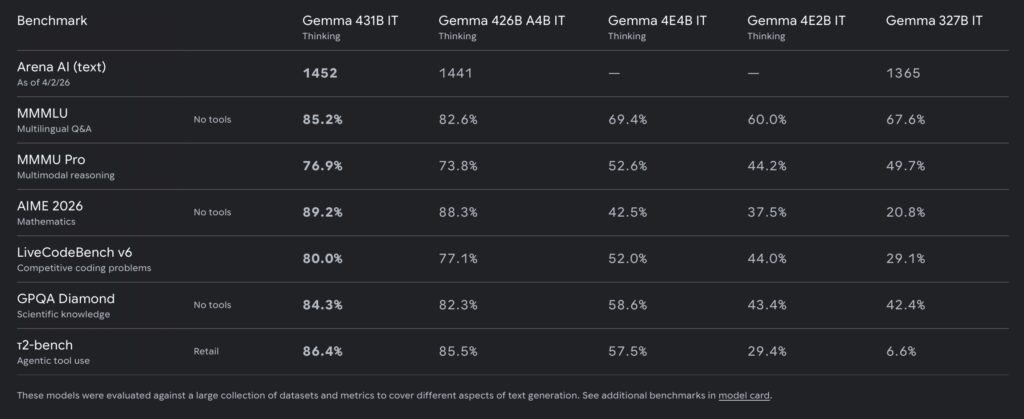
The numbers speak for themselves. This refined architecture allows the 31B dense model to achieve an estimated text-only LMArena score of 1452. Even more mind-boggling is the 26B Mixture-of-Experts (MoE) variant, which hits a score of 1441 while utilizing a mere 4B active parameters.
The Secret Weapon: Per-Layer Embeddings (PLE)
One of the standout innovations driving the smaller Gemma 4 models is Per-Layer Embeddings (PLE). In a traditional transformer, a token gets a single embedding vector right at the input, and the model has to cram everything it might need into that one initial representation. PLE flips this script.
It adds a parallel, lower-dimensional pathway alongside the main residual stream. By combining a token-identity component with a context-aware projection, it generates a tiny, dedicated vector for every single layer. This grants each layer its own private channel to receive token-specific information exactly when it becomes relevant, rather than front-loading it all at the start. For multimodal inputs, PLE operates cleverly by computing before soft tokens are merged into the sequence, using pad token IDs to provide neutral per-layer signals. Because this PLE dimension is so small, it adds massive per-layer specialization at a surprisingly modest parameter cost.
Multimodal Mastery
Informal testing reveals that Gemma 4’s multimodal operation isn’t just a gimmick; it’s as robust as its text generation. The model excels at a dizzying array of tasks natively, including OCR, speech-to-text, sophisticated object detection, and pointing.
When put to the test on GUI element detection—prompted to find the bounding box for a “view recipe” button—the model natively responded in perfect JSON format with accurate bounding boxes. No special formatting instructions or grammar constraints were needed; it simply understood the assignment, providing coordinates relative to an internal 1000×1000 image space. It replicated this success in everyday object detection, accurately finding and mapping elements like bicycles in complex scenes.
But Gemma 4 doesn’t just see; it thinks. When tasked with reverse-engineering an HTML page originally created by Gemini 3, the model utilized multimodal thinking to generate thousands of tokens of flawless code. Its video comprehension is equally impressive. The smaller models can ingest video paired with audio, while the larger models process video visually. Despite not being explicitly post-trained on video data, they capture the nuance of moving images perfectly. Cap this off with stellar, highly detailed image captioning abilities, and it is clear that Gemma 4 isn’t just an upgrade—it is a new standard for open-source AI.