Stratified Evaluation Offers Deeper Insights into LLM Performance and Guides Model Improvement
A recent research paper by Patrik Puchert, Poonam Poonam, Christian van Onzenoodt, and Timo Ropinski introduces LLMMaps, a novel visualization technique designed to evaluate the performance of Large Language Models (LLMs) in relation to question and answer (Q&A) datasets. LLMMaps aims to support a stratified evaluation, providing detailed insights into an LLM’s knowledge capabilities in different subfields and revealing areas where hallucinations are more likely to occur.
Traditionally, LLM performance evaluations report a single accuracy number for an entire knowledge field. This method, however, lacks transparency and does not effectively guide model improvement. LLMMaps addresses this issue by transforming Q&A datasets and LLM responses into an internal knowledge structure, offering a more granular view of model performance.
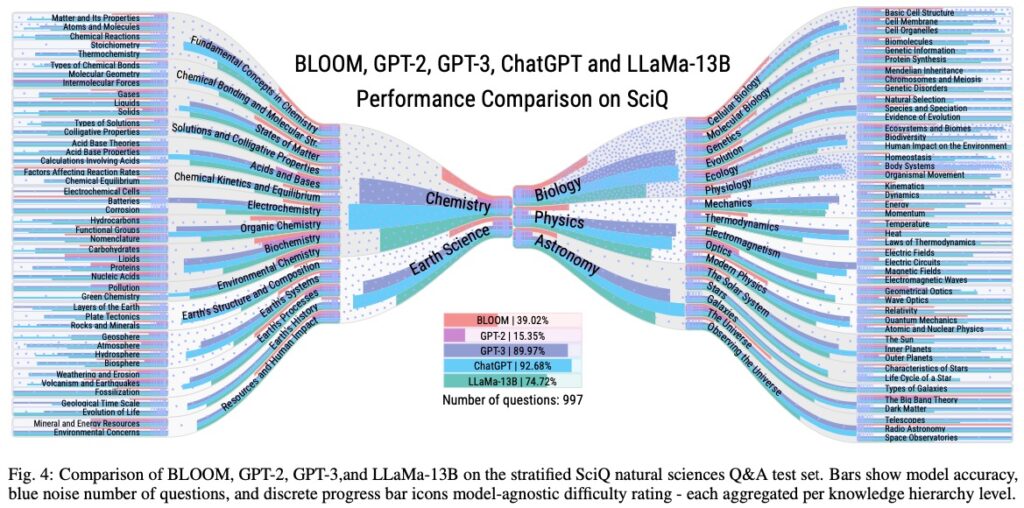
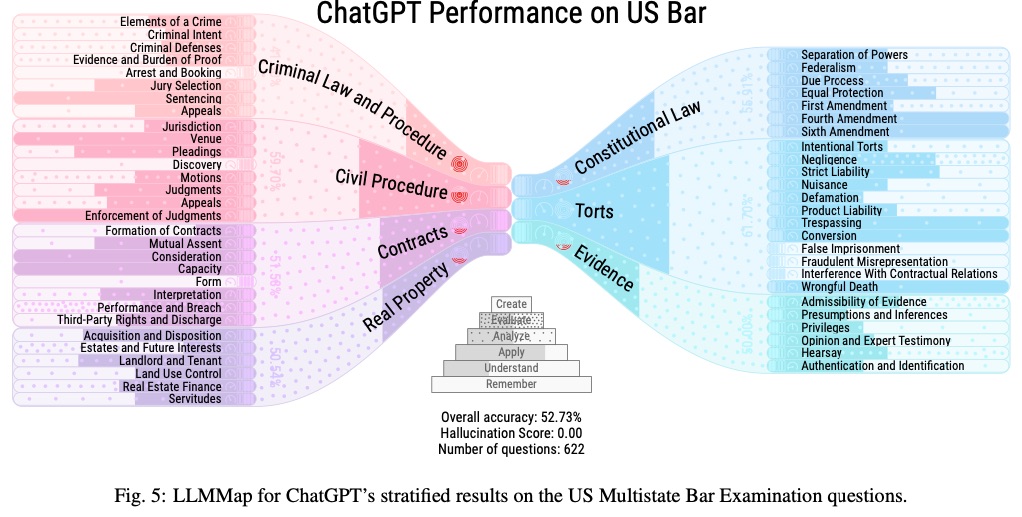
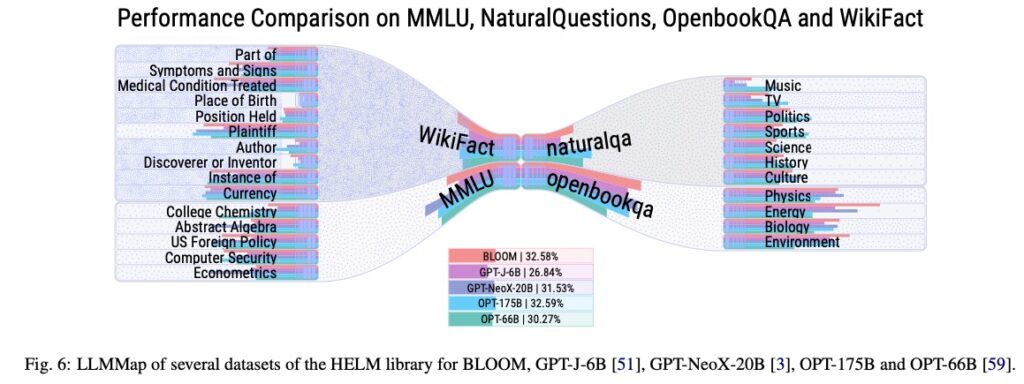
LLMMaps also features an extension for comparative visualization, allowing users to conduct detailed comparisons of multiple LLMs. The researchers used LLMMaps to analyze state-of-the-art models, including BLOOM, GPT-2, GPT-3, ChatGPT, and LLaMa-13B, and conducted two qualitative user evaluations.
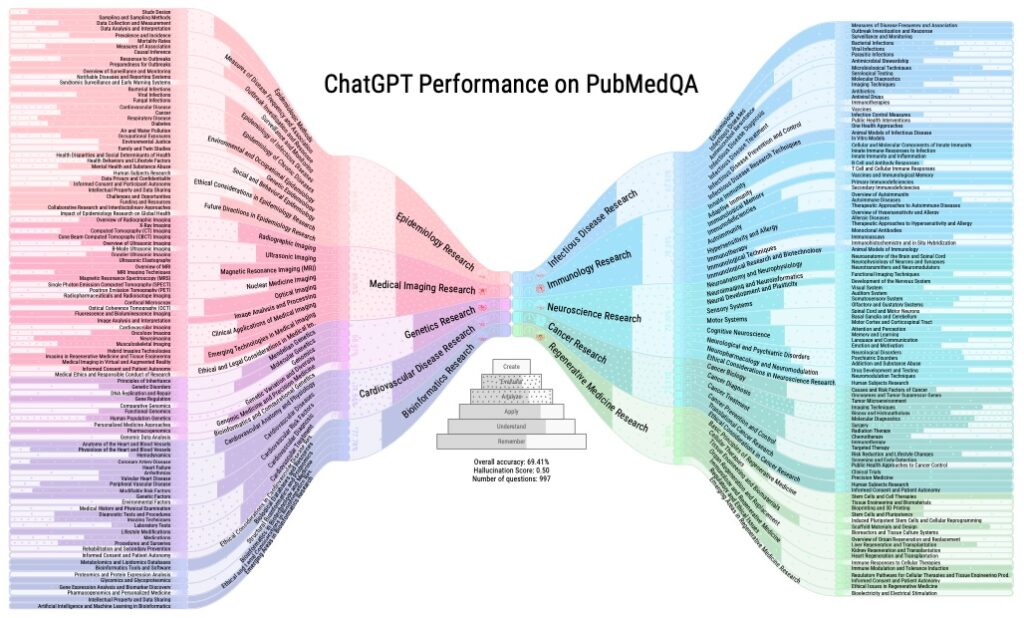
One example provided in the paper shows LLMMaps being used to evaluate ChatGPT’s knowledge capability on PubMedQA, a Q&A dataset containing 997 biomedical research questions. The visualization depicts performance per subfield, including accuracy, the number of questions per subfield, average difficulty level, response time, and hallucination score. The performance is also stratified according to Bloom’s learning dimension hierarchy.
By providing a more comprehensive evaluation method, LLMMaps has the potential to significantly impact the development and improvement of LLMs. The source code and data for generating LLMMaps will be made available on GitHub for use in scientific publications and other applications.