A Comprehensive Framework to Benchmark the Code Editing Prowess of Large Language Models
- Bridging Real-World Scenarios: CodeEditorBench extends beyond traditional code generation benchmarks to assess LLMs on tasks that mirror real-world software development, including debugging, translating, polishing, and requirement adjustments.
- In-Depth Evaluation Reveals Key Insights: Initial evaluations of 19 LLMs demonstrate a notable performance gap, with closed-source models like Gemini-Ultra and GPT-4 leading, especially in complex code editing scenarios.
- Open Collaboration and Continuous Improvement: The release of all prompts and datasets aims to foster community involvement, facilitating ongoing enhancements and broader applicability of the benchmark to future LLM developments.
The rapid evolution of Large Language Models (LLMs) has revolutionized numerous fields, with software development standing out as a particularly ripe area for AI-driven innovation. Among the capabilities being honed within these AI models, code editing has emerged as a critical and highly demanded skill, reflective of real-world development challenges. Addressing this need, the introduction of CodeEditorBench marks a significant leap forward in the evaluation of LLMs tailored for software engineering tasks.
CodeEditorBench distinguishes itself from existing benchmarks by focusing on the practical aspects of coding that developers encounter daily. This includes not just writing new code but refining existing codebases through debugging, translating code across programming languages, enhancing code quality, and adapting code to new requirements. This holistic approach ensures that the framework addresses the multifaceted nature of software development, providing a more comprehensive assessment of an LLM’s utility in real-world scenarios.
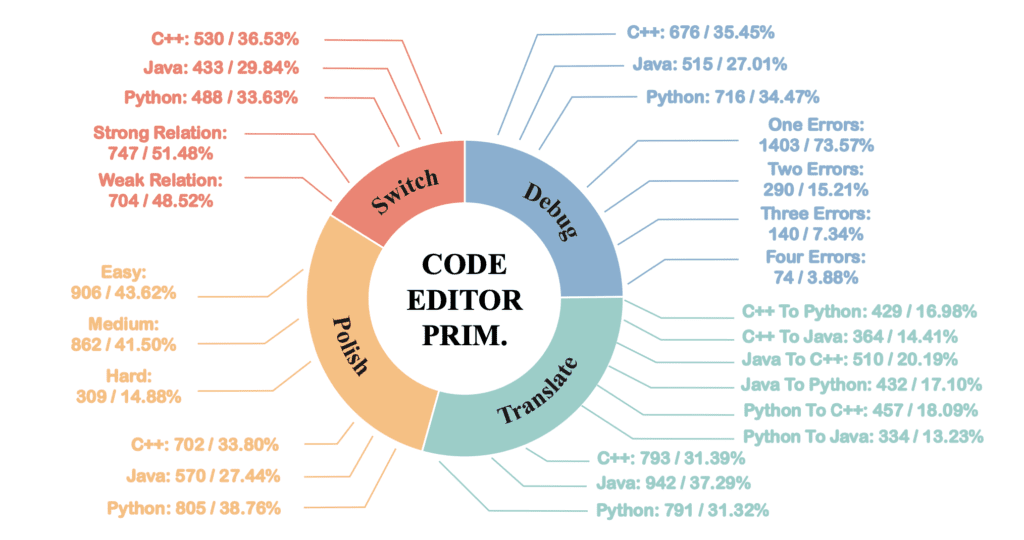
The framework‘s initial evaluation encompassed 19 LLMs, uncovering insightful trends. Notably, closed-source models such as Gemini-Ultra and GPT-4 showcased superior performance in tackling the diverse challenges posed by CodeEditorBench. This disparity in model efficacy underscores the complexity of code editing tasks and the varying degrees to which different models have been optimized for such challenges. The results highlight the importance of problem-specific tuning and the sensitivity of LLMs to the nuances of software development prompts.
In the spirit of open science and collaborative advancement, the creators of CodeEditorBench have committed to releasing all prompts and datasets associated with the framework. This move not only ensures transparency but also invites the broader research and development community to engage with and expand upon the benchmark. Such openness is expected to catalyze further advancements in LLMs, driving innovations that could reshape the landscape of AI-assisted software development.
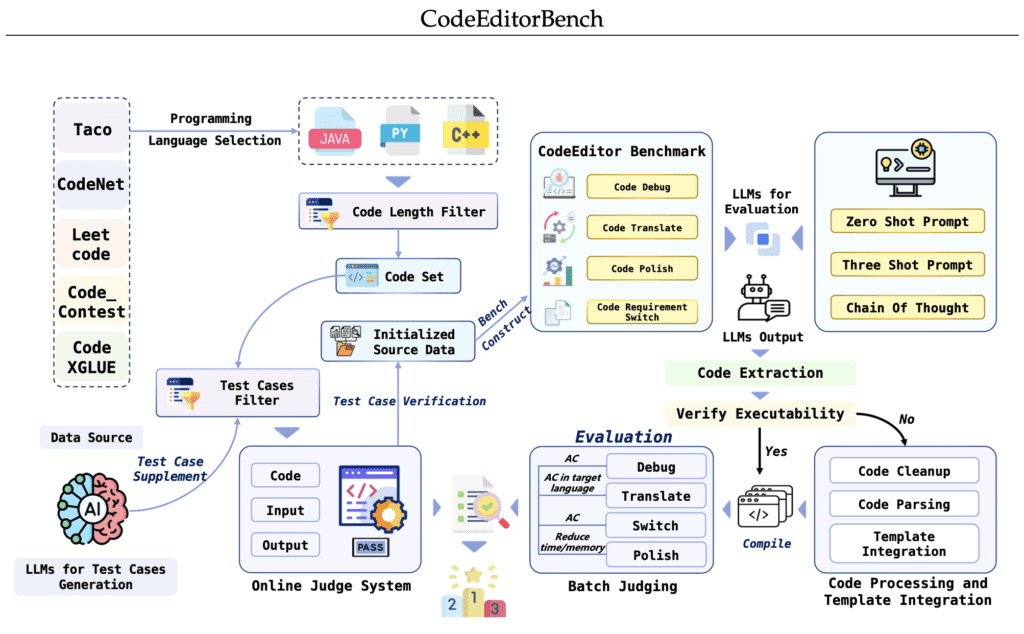
By providing a robust platform for systematically assessing code editing capabilities, CodeEditorBench contributes significantly to the field. It not only offers a valuable tool for researchers and practitioners to gauge the effectiveness of current models but also sets a precedent for the development of future LLMs. As AI continues to integrate deeper into the software development lifecycle, benchmarks like CodeEditorBench will play a pivotal role in guiding progress, ensuring that emerging models are both powerful and attuned to the practical needs of developers.