Rethinking depth-wise aggregation to solve hidden-state dilution and unlock smarter, more efficient scaling in large language models.
- The Problem: Standard residual connections blindly accumulate information with fixed, uniform weights, causing hidden-state growth that progressively dilutes the contributions of early layers in deep networks.
- The Innovation: Attention Residuals (AttnRes) treats network depth like a sequence, replacing fixed accumulation with learned, input-dependent softmax attention to selectively retrieve past layer representations.
- The Scale: To make this feasible for massive models, Block AttnRes compresses layers into blocks, enabling cross-layer attention on a 48-Billion parameter architecture with a 1.25x compute advantage and negligible (<2%) inference overhead.
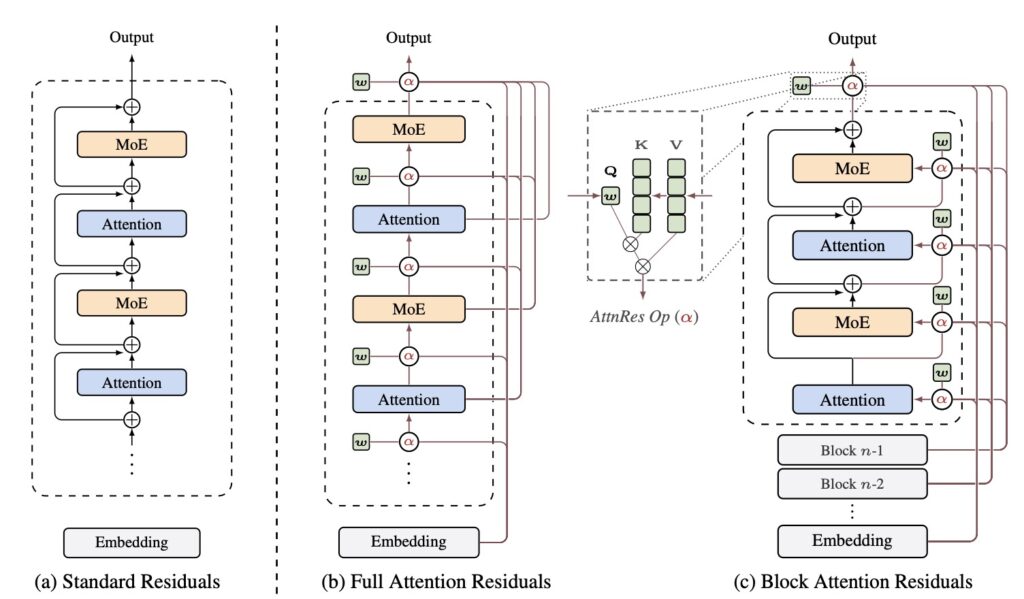
Standard residual connections have long been the de facto building blocks of modern Large Language Models (LLMs). The classic update formula, hl=hl−1+fl−1(hl−1), is universally recognized as a “gradient highway.” It allows gradients to bypass complex transformations via identity mappings, ensuring stable training even at massive depths. However, this mechanism plays a secondary role that has largely flown under the radar: it dictates exactly how information aggregates across the depth of the network.
If we unroll the recurrence of a standard residual network, a glaring limitation emerges. Every single layer receives the exact same uniformly weighted sum of all prior layer outputs. While sequence mixing and expert routing have evolved to use highly sophisticated, learnable, input-dependent weighting, depth-wise aggregation remains stuck in the past. It is governed entirely by fixed unit weights, completely lacking a mechanism to selectively emphasize or suppress individual layer contributions based on context.
The Dilution Dilemma
In practice, the combination of residual connections with PreNorm has become the dominant paradigm in LLM architecture. Yet, its unweighted accumulation has a hidden cost: hidden-state magnitudes grow at a rate of O(L) with depth. As the network gets deeper, this uncontrolled growth progressively dilutes the relative contribution of each individual layer.
Crucial information processed in early layers gets buried beneath a growing avalanche of subsequent accumulations, making it impossible for the network to selectively retrieve it later on. Empirically, this inefficiency is proven by the fact that a significant fraction of layers in modern models can often be pruned with minimal loss in performance. Previous attempts to fix this—such as scaled residual paths or multi-stream recurrences—remained tied to additive recurrence. The few methods that did introduce cross-layer access proved notoriously difficult to scale.
This architectural bottleneck perfectly mirrors the historical challenges Recurrent Neural Networks (RNNs) faced over the sequence dimension, right before the attention mechanism revolutionized the field.
Enter Attention Residuals: The Duality of Sequence and Depth
Recognizing a formal duality between depth-wise accumulation and sequential recurrence, researchers have introduced Attention Residuals (AttnRes). This approach fundamentally rethinks how layers communicate.
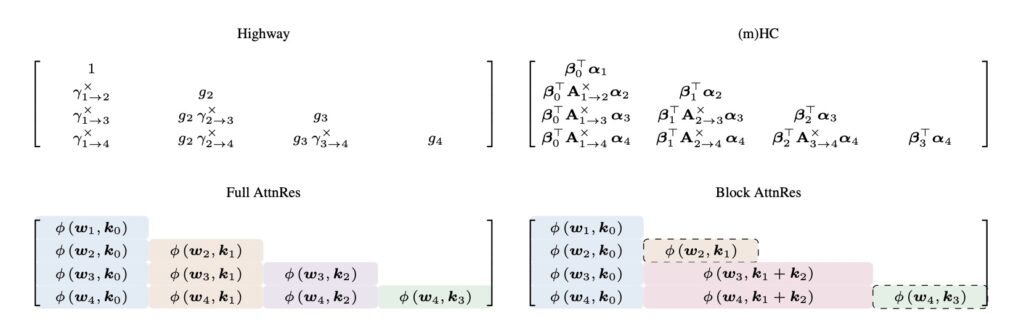
Instead of the fixed accumulation defined by hl=∑ivi, AttnRes transitions to a dynamic, content-aware retrieval system: hl=∑iαi→l⋅vi. In this new paradigm, αi→l represents softmax attention weights computed from a single, learned pseudo-query wl∈Rd per layer.
This incredibly lightweight mechanism requires only one d-dimensional vector per layer, yet it allows the network to selectively look back and pull exactly the representations it needs from previous depths. Essentially, AttnRes generalizes standard residuals to depth-wise softmax attention, completing the very same linear-to-softmax transition across network depth that once transformed sequence modeling.
The Power of Block AttnRes
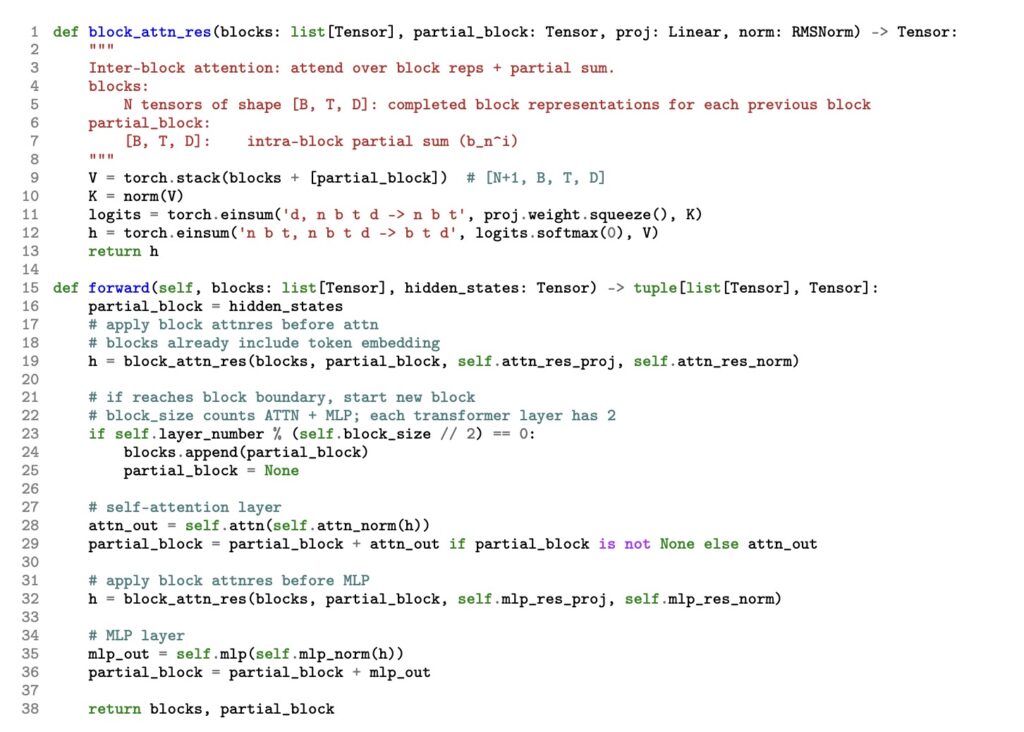
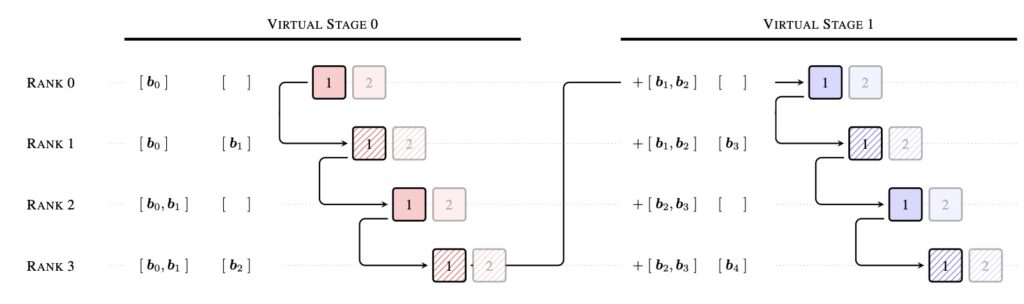
While Full AttnRes is theoretically elegant, it introduces a practical hurdle at scale. Because it must access all preceding layer outputs at every step, the memory footprint of cross-layer aggregation grows as O(Ld). In the era of massive LLMs utilizing activation recomputation and pipeline parallelism, saving and communicating all these activations across pipeline stages is prohibitive on current hardware.
To solve this, Block AttnRes bridges the gap between theory and hardware reality. By partitioning layers into N blocks, each block is reduced to a single representation via standard residuals. Cross-block attention is then applied only over these N block-level summaries. This clever partition slashes both memory and communication overhead down to a manageable O(Nd).
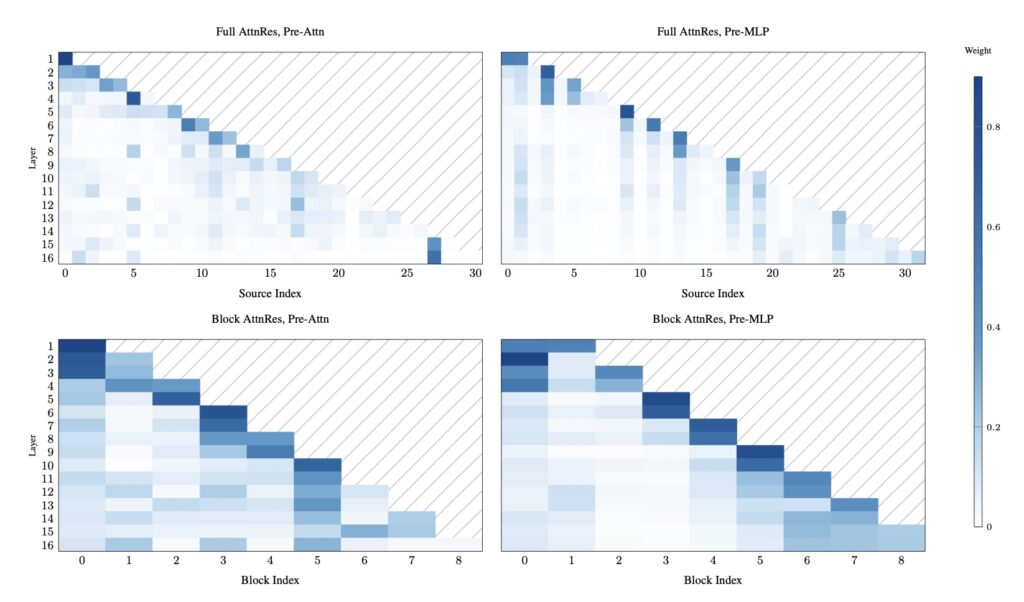
Empirically, using just about 8 blocks is enough to recover the vast majority of the performance gains seen in Full AttnRes. When combined with cross-stage caching and a two-phase computation strategy, Block AttnRes serves as a highly efficient, drop-in replacement for standard residual connections.
Proven at the Frontier
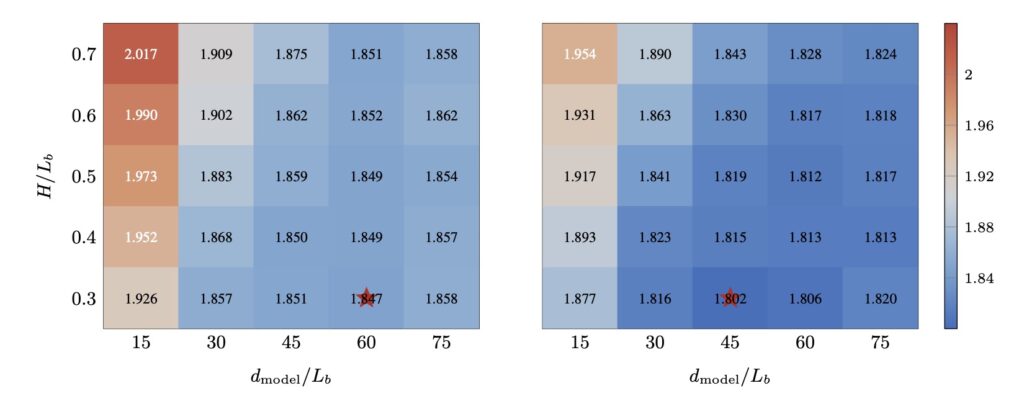
The real test of any architectural shift is its performance at scale. Scaling law experiments have confirmed that the benefits of content-dependent depth-wise selection persist as models grow.
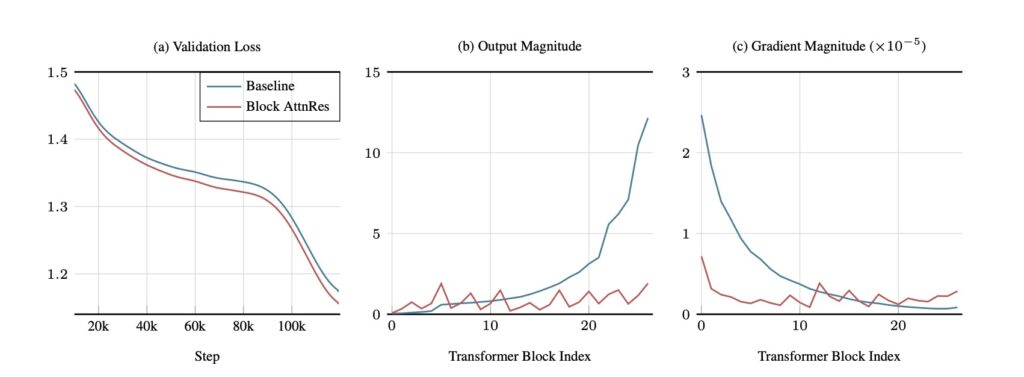
To definitively prove its viability, AttnRes was integrated into the Kimi Linear architecture—a massive model featuring 48B total and 3B activated parameters—and pre-trained on a staggering 1.4 Trillion tokens. The results speak for themselves. AttnRes successfully mitigated PreNorm dilution, yielding much more uniform output magnitudes and a healthier gradient distribution across the network’s depth.
It delivered a tangible 1.25x compute advantage while adding a negligible inference latency overhead of less than 2%. Ultimately, AttnRes improved downstream performance across all evaluated tasks, proving that redefining how neural networks look backward is a critical step forward.