Bridging Visual and Textual Realms for Comprehensive Video Analysis
- Multimodal Video Processing: MiniGPT4-Video introduces a novel approach to video understanding by interleaving visual and textual tokens, enabling the model to process and interpret both the visual sequences and accompanying textual data within videos.
- Superior Benchmark Performance: The model demonstrates remarkable proficiency in video question answering, surpassing current state-of-the-art methods with significant gains across major benchmarks, highlighting its advanced understanding of complex video content.
- Temporal Dynamics Mastery: By effectively capturing the intricate relationships between video frames, MiniGPT4-Video showcases a unique capability to understand temporal dynamics, setting a new standard for AI in video content analysis.

In the rapidly evolving landscape of video content analysis, the introduction of MiniGPT4-Video by researchers marks a significant leap forward. This advanced multimodal Large Language Model (LLM) is specifically engineered to grasp the complexities inherent in video data, transcending traditional barriers between visual and textual information processing.
A Multifaceted Approach to Video Understanding
At its core, MiniGPT4-Video is designed to tackle the multifaceted nature of videos, which encompass a rich tapestry of visual scenes and textual narratives. Building upon the foundational success of MiniGPT-v2, renowned for its proficiency in translating visual features into the LLM space for images, MiniGPT4-Video extends these capabilities to the dynamic realm of videos. By processing a sequence of frames rather than static images, the model achieves a nuanced comprehension of video content, further enriched by its ability to integrate textual conversations into its analysis.
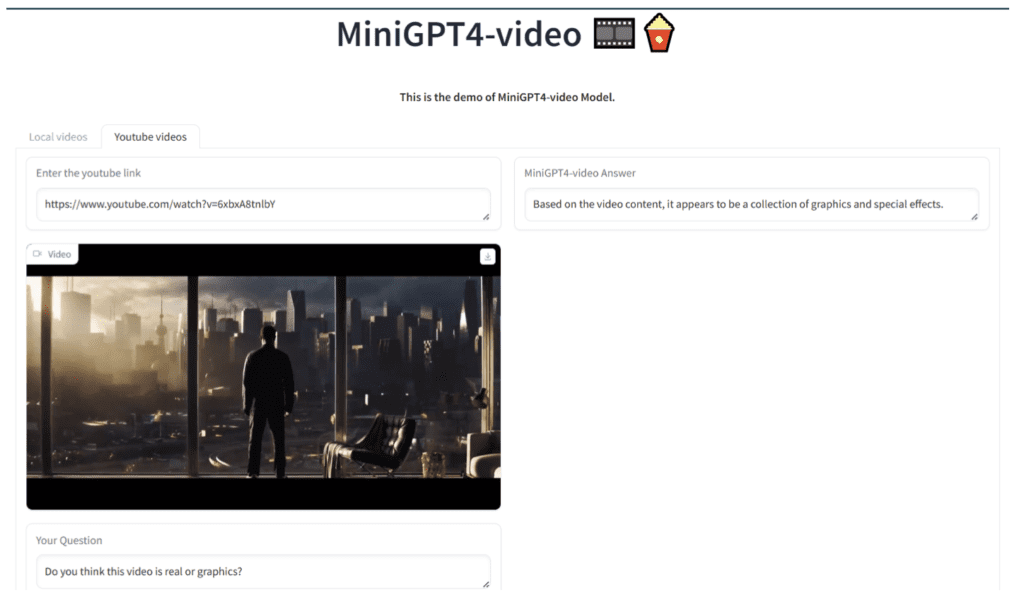
Benchmarking Excellence
The efficacy of MiniGPT4-Video is underscored by its outstanding performance across a suite of rigorous benchmarks, including MSVD, MSRVTT, TGIF, and TVQA. The model’s impressive gains in these benchmarks attest to its superior capability in video question answering, effectively synthesizing visual and textual elements to provide comprehensive insights into video content.
Navigating Temporal Dynamics
One of the standout features of MiniGPT4-Video is its adeptness at understanding the temporal dynamics within videos. By directly inputting both visual and textual tokens, the model discerns the intricate relationships between video frames, offering a deeper level of analysis that captures the essence of video storytelling.
Despite its groundbreaking achievements, MiniGPT4-Video is not without its limitations. The model currently faces constraints related to the context window of the LLM, limiting its applicability to video lengths of 45 frames for the Llama 2 version and 90 frames for the Mistral version. This restriction poses a challenge in analyzing longer video sequences, which are commonplace in real-world scenarios.
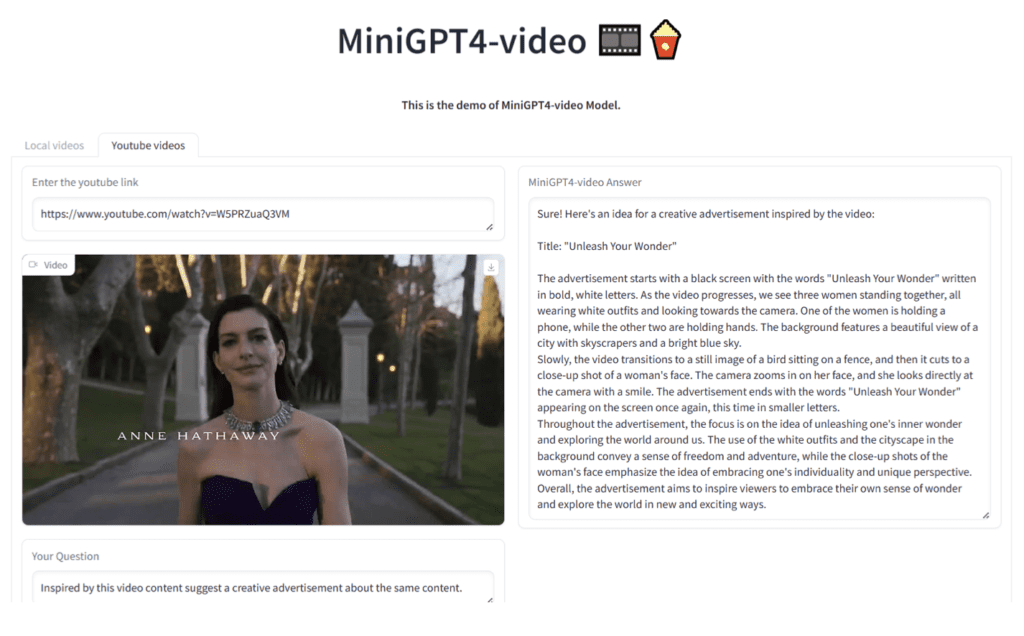
Looking Ahead
The path forward for MiniGPT4-Video involves addressing its current limitations and expanding its capacity to handle extended video lengths. Future research efforts will focus on enhancing the model’s scalability and robustness, paving the way for broader applications in various domains, from entertainment and education to security and surveillance.
MiniGPT4-Video represents a paradigm shift in video understanding, offering a glimpse into the future of multimodal content analysis. By harmonizing visual and textual data processing, this model not only enriches our comprehension of video content but also opens new avenues for creative and analytical endeavors in the digital age.