Redefining Efficiency with a “More Intelligence, Less Compute” Approach to Foundation Models
- Architectural Leap: Built on the same advanced foundation as their larger siblings, the Qwen 3.5 Small Model Series integrates early-fusion multimodal training and a hybrid Gated Delta Network/MoE architecture.
- Scale for Every Need: The lineup ranges from the ultra-fast 0.8B and 2B models for edge devices to the 9B powerhouse that rivals much larger legacy systems.
- Real-World Robustness: Enhanced by massive-scale Reinforcement Learning (RL) and expanded linguistic support for 201 languages, these models are optimized for complex reasoning, coding, and agentic workflows.
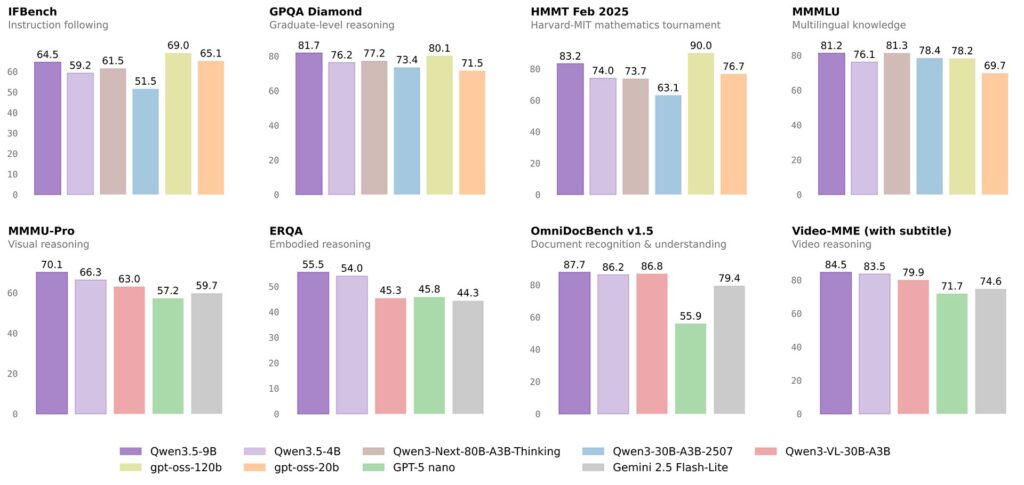
In the rapidly evolving landscape of artificial intelligence, the mantra has long been “bigger is better.” However, the release of the Qwen 3.5 Small Model Series—comprising the 0.8B, 2B, 4B, and 9B variants—flips this script. By prioritizing “more intelligence, less compute,” these models represent a significant leap forward in making high-performance AI accessible, portable, and industrially viable. Far from being “lite” versions with stripped-back features, these models are built on the full Qwen 3.5 foundation, featuring native multimodality, improved architecture, and scaled reinforcement learning.
Multimodal by Design, Global by Nature
The standout feature of the Qwen 3.5 series is its Unified Vision-Language Foundation. Unlike previous iterations where vision was often an “add-on,” this series utilizes early-fusion training on multimodal tokens. This allows even the smallest models to achieve cross-generational parity with older, larger models in reasoning, coding, and visual understanding. This intelligence is paired with an unprecedented Global Linguistic Coverage, supporting 201 languages and dialects. Whether it is nuanced cultural understanding or technical coding in a regional dialect, Qwen 3.5 is designed for truly inclusive, worldwide deployment.
A Spectrum of Capability
Each model in the series serves a distinct purpose in the modern tech ecosystem:
- The Edge Specialists (0.8B & 2B): Designed for speed and minimal footprint, these are perfect for “on-device” AI where latency and privacy are paramount.
- The Agentic Base (4B): This model serves as a surprisingly strong multimodal base, striking a balance between size and power that is ideal for lightweight autonomous agents.
- The Gap Closer (9B): Despite its compact size, the 9B model is already closing the performance gap with much larger traditional models, offering enterprise-grade utility without the massive hardware overhead.
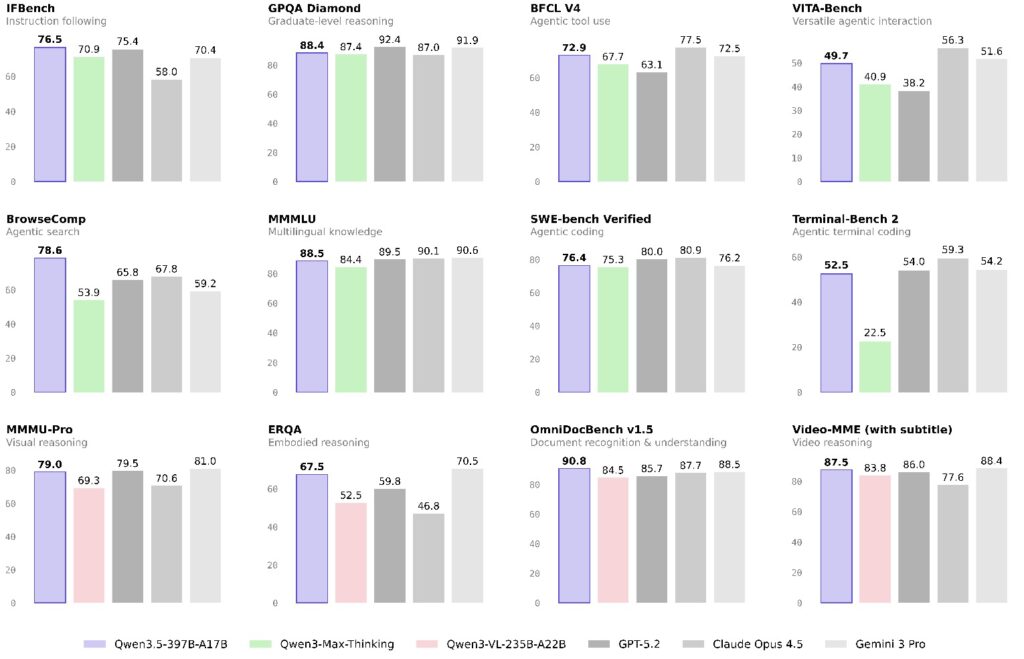
Efficiency Meets Rigorous Validation
Under the hood, Qwen 3.5 employs an Efficient Hybrid Architecture. By combining Gated Delta Networks with sparse Mixture-of-Experts (MoE), the models deliver high-throughput inference with minimal cost. This is supported by a next-generation training infrastructure that achieves near-100% multimodal training efficiency.
To ensure these models perform in the real world, they have been subjected to rigorous benchmarking, including the HLE-Verified dataset (a revised version of Humanity’s Last Exam) and TAU2-Bench. From “Search Agents” using smart context-folding strategies to handle 256k windows, to “BrowseComp” tests where the models achieved scores as high as 78.6, the series proves it can handle the complexity of modern web navigation and tool usage.
Empowering the Future of Innovation
By releasing both the specialized and the Base models, the Qwen team is providing a versatile toolkit for researchers and industrial innovators alike. These models are not just tools for today; they are scaffolds for the massive-scale agent environments of tomorrow. With scaled RL generalization across million-agent environments, Qwen 3.5 is ready to adapt to progressively complex task distributions, ensuring that “small” AI can solve “big” problems.