Exploring the consistency bugs in long-form AI generation and how the new “ConStory” framework aims to fix them.
- The AI Amnesia Problem: While Large Language Models (LLMs) can generate thousands of words of fluent prose, they frequently suffer from “consistency bugs”—contradicting established facts, character traits, timelines, and world rules as the story progresses.
- A New Standard for Measurement: To combat this, researchers have introduced ConStory-Bench, a comprehensive dataset of 2,000 prompts, alongside ConStory-Checker, an automated, four-step pipeline that acts as a judge to detect and document narrative contradictions.
- Predictable Failures: Evaluations reveal that AI consistency errors are not random. They primarily occur in factual and temporal dimensions, tend to cluster in the middle of narratives, and correlate strongly with moments of high textual entropy.
Imagine reading a gripping mystery novel. In chapter two, the detective establishes that the murder weapon was a silver candlestick. But by chapter ten, the detective triumphantly reveals that the poison was the cause of death—without any explanation for the change. If a human author wrote this, you would demand a refund. When an AI writes it, we call it a “consistency bug.”
As Large Language Models (LLMs) continue to evolve, long-form narrative generation has become a centerpiece of their capabilities, empowering everything from creative storytelling and content creation to educational authoring. Modern context windows have expanded massively, allowing models to generate tens of thousands of words. However, the illusion of a master AI storyteller quickly shatters when the model forgets its own story. Rather than just producing locally fluent text, true storytelling requires tracking entities, preserving world rules, and sustaining stylistic conventions over vast token distances.

Until now, the AI community has lacked a standardized way to measure this specific flaw. Existing benchmarks have heavily favored plot quality and sentence-level fluency, leaving the insidious problem of cross-context contradictions largely ignored.
Building the Ultimate Consistency Test: ConStory-Bench
To address the gap between writing a pretty sentence and telling a coherent story, researchers have developed ConStory-Bench. Unlike previous tools, this benchmark is specifically engineered to isolate and evaluate narrative consistency in long-form generation.
The dataset is built from the ground up to challenge an AI’s memory and reasoning. Researchers curated long-context narrative materials from seven diverse, public corpora: LongBench, LongBench_Write, LongLamp, TellMeAStory, WritingBench, WritingPrompts, and WikiPlots. They intentionally selected passages packed with clear plot progressions, multiple interacting entities, and explicit temporal movement—the exact ingredients that cause an AI to stumble.
From these sources, they crafted 2,000 unique prompts distributed across four distinct task scenarios:
- Generation: Asking the model to instantiate a complete story from scratch.
- Continuation: Having the model provide a context-preserving extension to an existing narrative.
- Expansion: Requiring the model to elaborate on a specific, focused segment.
- Completion: Challenging the AI to coherently fill in a narrative gap.
To categorize the inevitable failures, the researchers developed a hierarchical taxonomy rooted in narrative theory, breaking down consistency errors into five top-level categories and 19 fine-grained subtypes.
Catching the AI Red-Handed: ConStory-Checker
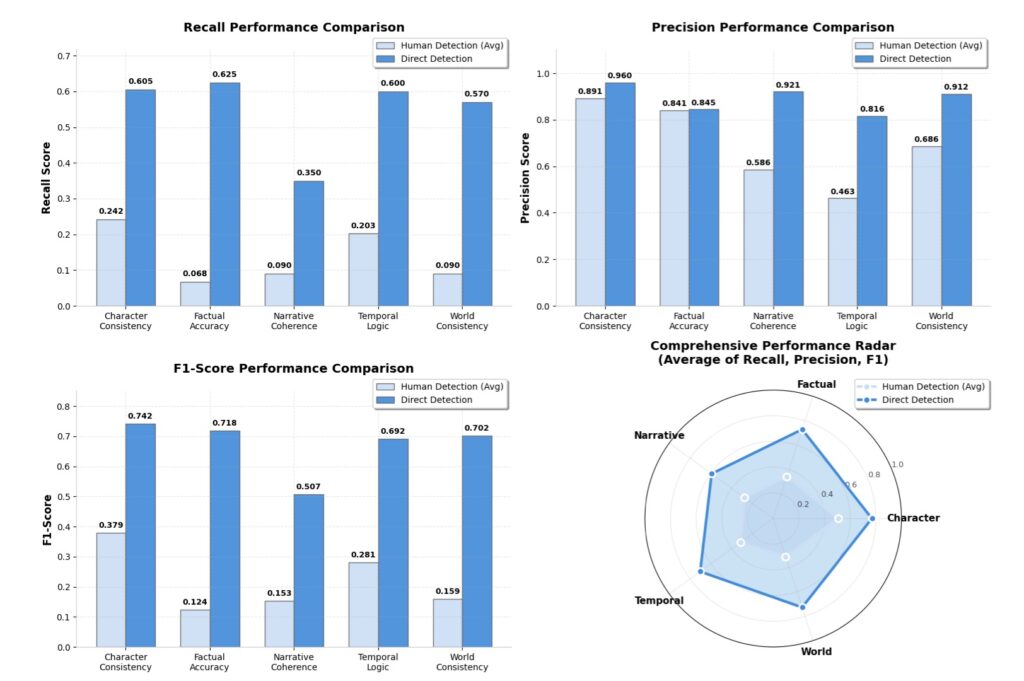
Having a benchmark is only half the battle; evaluating thousands of long-form stories manually is virtually impossible. Enter ConStory-Checker, an automated “LLM-as-a-judge” evaluation pipeline designed to scale consistency checking while remaining entirely auditable. Powered by the efficient and accurate o4-mini model, the checker operates in four meticulous stages:
- Category-Guided Extraction: The system scans the generated narratives using specific prompts to pull out text spans that are likely to harbor contradictions across the five error dimensions.
- Contradiction Pairing: The extracted spans are compared against each other. The system classifies them as either “Consistent” or “Contradictory,” effectively filtering out false positives.
- Evidence Chains: It is not enough to simply flag an error. The Checker documents every contradiction with a structured chain: the reasoning behind the judgment, exact quoted evidence with character-level offsets, and a conclusive typed error.
- JSON Reports: Finally, the pipeline outputs standardized JSON files detailing the quotations, positions, pairings, and explanations, ensuring the analysis is perfectly reproducible.
Uncovering the “Mushy Middle”: Research Findings
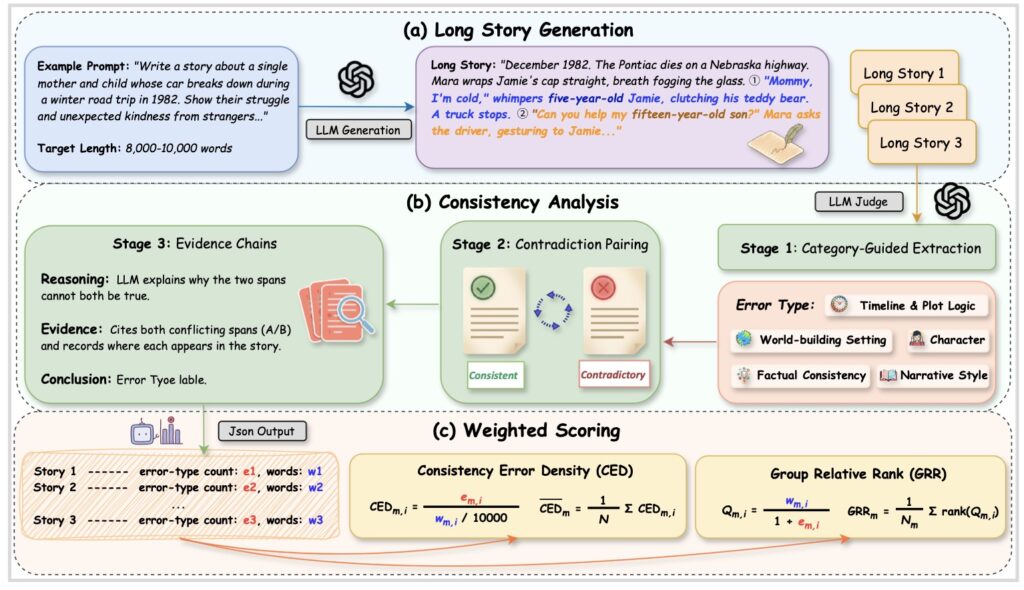
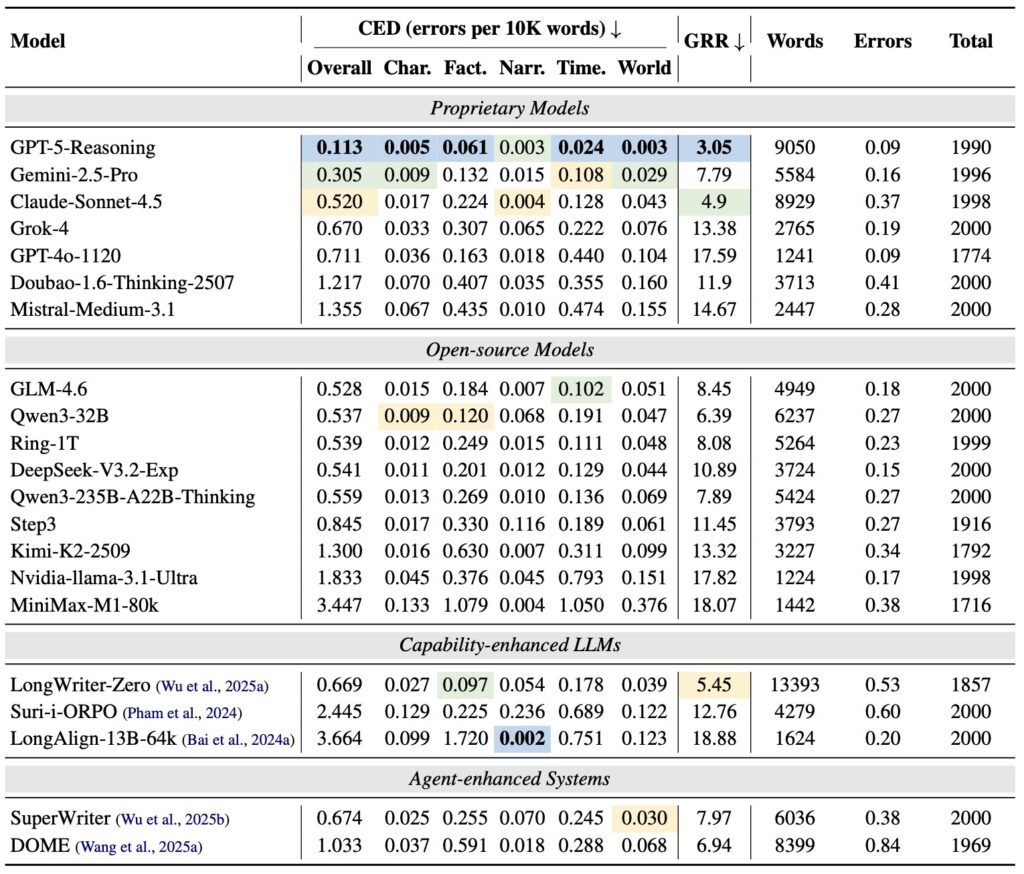
Armed with ConStory-Bench and ConStory-Checker, researchers evaluated a wide array of proprietary, open-source, and agent-enhanced models. To ensure fairness, they established two primary metrics: CED (Consistency Error Density, measuring errors per 10,000 words) and GRR (Group Relative Rank, which controls for the difficulty of the prompt).
The investigation was guided by five core research questions regarding how well models maintain coherence, how errors scale with length and architecture, the underlying factors of these bugs, how errors co-occur, and where they are physically located in the text.
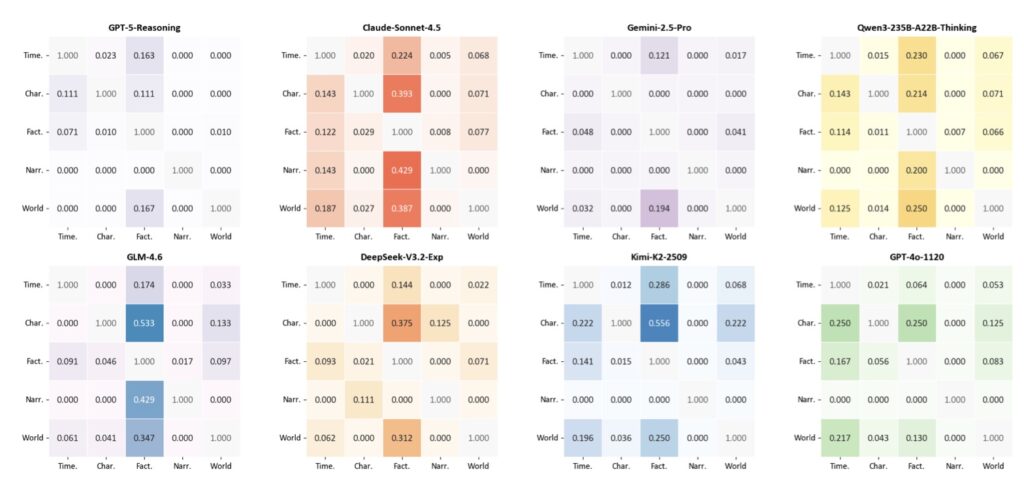
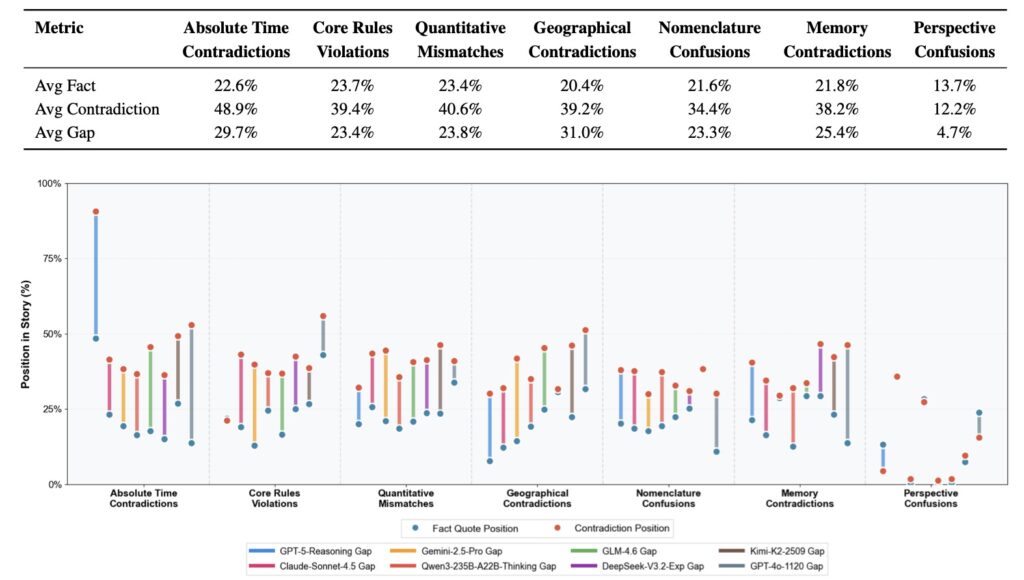
The findings paint a fascinating picture of AI psychology. Current LLMs, regardless of their architecture, exhibit systematic and predictable consistency errors. They struggle immensely with factual tracking and temporal reasoning—forgetting what happened and when it happened.
Furthermore, these errors are not sprinkled randomly throughout the text. They overwhelmingly cluster in the middle of narratives, a phenomenon human writers often call the “mushy middle.” The data also showed that consistency bugs are highly correlated with text segments exhibiting higher token-level entropy, meaning that when the AI is less certain about what word comes next, it is much more likely to contradict its own established facts. Finally, the researchers noted that certain types of errors systematically co-occur, suggesting underlying structural weaknesses in how models process narrative states.
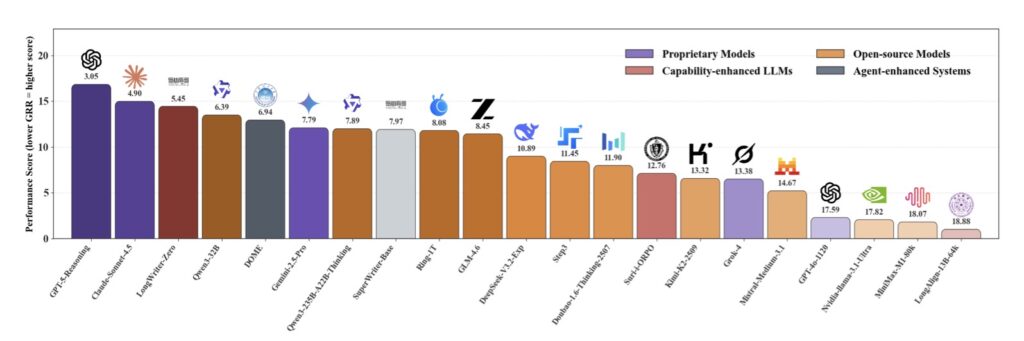
The Future of AI Storytelling
The development of ConStory-Bench and ConStory-Checker marks a pivotal shift in how we evaluate generative AI. We are moving past the novelty of models simply being able to speak, and demanding that they actually make sense over the long haul.
To accelerate this progress, the researchers plan to launch an interactive portal where the wider AI and developer community can discover, submit, and analyze new consistency errors and checking techniques. By understanding exactly when, where, and why our digital storytellers lose the plot, we are one step closer to AI that can author a novel without forgetting the murder weapon along the way.