Editing Tomorrow’s Videos Using Only Today’s 2D Images
- Video Editing Without Video Data: ViFeEdit eliminates the need for scarce paired video data and high computational costs by adapting text-to-video models using solely 2D images.
- Innovative Architecture: By decoupling spatial interactions from full 3D attention, the framework ensures precise visual control without losing the smooth, temporal consistency of the video.
- Enhanced Stability and Consistency: A unique dual-path pipeline with separate timestep embeddings ensures backgrounds and motions stay consistent, leading to faster and more stable model training.

The world of generative AI has been rapidly expanding, with Diffusion Transformers (DiTs) leading the charge in creating high-quality, scalable images and videos. As these models become more sophisticated, the natural next step is giving users the power to easily control and edit this generated content. However, while editing AI-generated images has become relatively seamless, video editing has hit a major roadblock. The primary culprits? A severe scarcity of paired video data required to teach the models, and the astronomical computational costs associated with training them.

To break through this bottleneck, a groundbreaking new framework has been introduced: ViFeEdit. Acting as a “video-free tuner” for video diffusion transformers, ViFeEdit proposes a solution that sounds almost paradoxical. It enables versatile, high-quality video generation and editing without requiring a single frame of video training data. Instead, it adapts text-to-video DiTs to diverse video editing tasks at minimal costs by training exclusively on 2D images.

At the heart of ViFeEdit’s success is a clever architectural reparameterization. In standard modern video diffusion transformers, spatial and temporal data are often tightly intertwined in full 3D attention blocks. ViFeEdit changes the game by decoupling spatial independence from this full 3D attention. This separation isolates the image tuning process, vastly strengthening the model’s visual control capabilities. Most importantly, it achieves this visually faithful editing while perfectly maintaining the video’s temporal consistency—meaning the video still flows naturally without flickering or jarring jumps. Impressively, this is all accomplished with only minimal additional parameters added to the model.
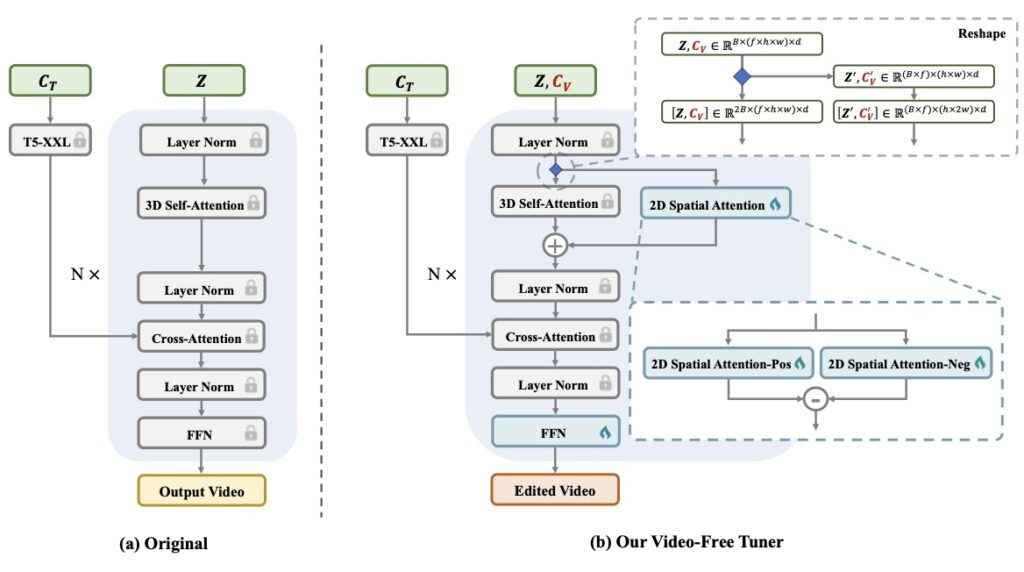
Beyond its core architecture, ViFeEdit introduces a dual-path pipeline to handle the complexities of noise scheduling. By utilizing separate timestep embeddings within this pipeline, the framework exhibits strong adaptability to a diverse range of conditioning signals. This specific design choice goes a long way in further enhancing both background and motion consistency across frames. As an added benefit, this dual-path approach streamlines the training process itself, allowing for more stable optimization and significantly faster convergence.

ViFeEdit represents a major leap forward for accessible video generation. Extensive experiments have demonstrated that, armed with only limited paired image data, this proposed method delivers highly promising performance across a wide range of video editing tasks. By removing the dependency on massive video datasets and heavy computational loads, ViFeEdit opens the door for faster, cheaper, and highly controllable video editing.
