Achieving Hyper-Realistic 3D Models at Unprecedented Speeds
- End-to-End Mesh Reconstruction: FlexiDreamer introduces a groundbreaking single image-to-3D generation framework that enables end-to-end reconstruction of target meshes, avoiding the pitfalls of post-processing and long convergence times associated with NeRF-based methods.
- Innovative FlexiCubes Extraction: By employing FlexiCubes, a flexible gradient-based extraction method, FlexiDreamer circumvents the visual artifacts typically introduced by post-processing, ensuring the direct acquisition of high-quality target meshes.
- Multi-Resolution Hashgrid Encoding: The framework enhances geometric detail capture through a novel multi-resolution hashgrid encoding scheme, progressively activating encoding levels within the implicit field, resulting in more detailed and accurate 3D models.
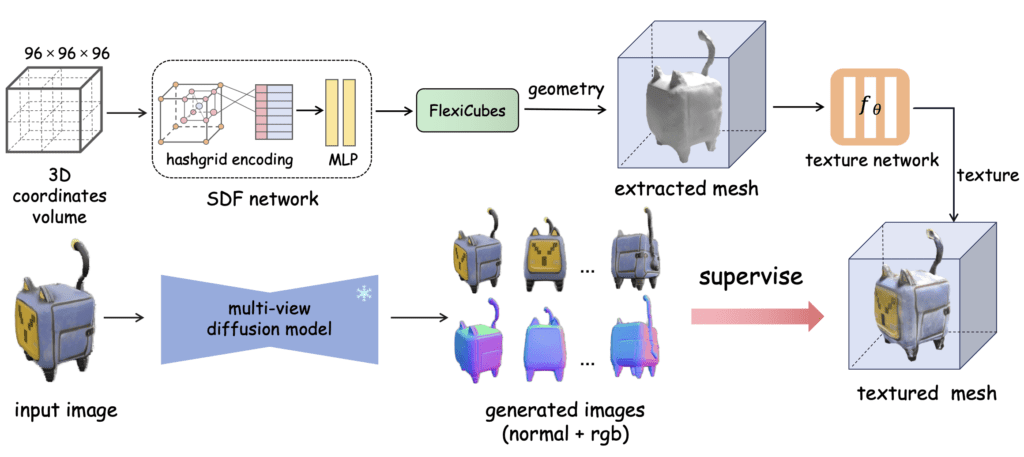
The quest for hyper-realistic 3D content generation from minimal input, such as text prompts or single images, has seen remarkable strides in quality and efficiency. FlexiDreamer emerges as a pivotal innovation in this domain, redefining the landscape of single-image 3D reconstruction. This novel framework ushers in a new era of end-to-end mesh reconstruction, eschewing the traditional reliance on implicit representations and post-processing extractions that have long been the industry standard.
Redefining 3D Reconstruction
FlexiDreamer’s core innovation lies in its utilization of FlexiCubes, a state-of-the-art gradient-based extraction technique that directly transforms single-view images into textured meshes. This approach not only streamlines the generation process but also significantly reduces the time required to produce detailed 3D models. The introduction of a multi-resolution hashgrid encoding scheme further bolsters this process, enabling the capture of intricate geometric details and textures, thereby elevating the fidelity of the generated 3D assets.
Surpassing Traditional Limitations
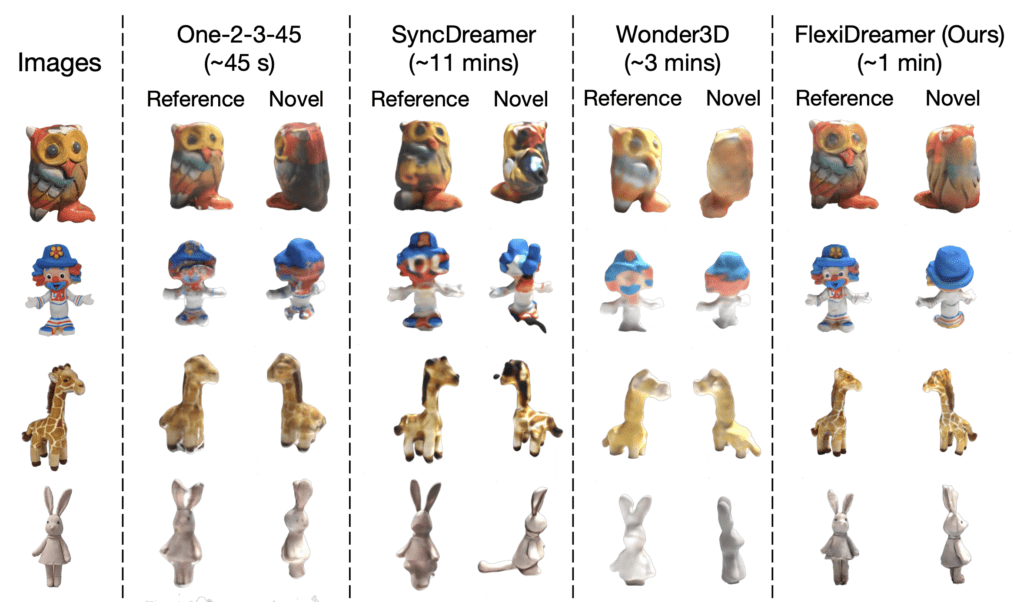
Traditional methods, particularly those based on Neural Radiance Fields (NeRF), often grapple with long convergence times and the introduction of visual artifacts during the post-extraction phase. FlexiDreamer transcends these limitations, offering a swift and seamless conversion from a single image to a fully realized 3D model in approximately one minute on advanced hardware like the NVIDIA A100 GPU. This leap in efficiency and quality positions FlexiDreamer at the forefront of 3D reconstruction technologies.
Ethical Considerations and Future Challenges
Despite its groundbreaking capabilities, FlexiDreamer’s potential for misuse, particularly in the creation of deepfakes or counterfeit products, raises significant ethical concerns. The ease and fidelity with which FlexiDreamer can replicate real-world objects underscore the need for vigilance among developers and users alike to prevent harmful applications of this technology.

Moreover, while FlexiDreamer significantly advances the field of 3D reconstruction, it is not without its limitations. The quality of the generated 3D assets remains contingent upon the quality of the input images and the existing multi-view diffusion models. Imperfections in these areas can lead to inconsistencies in the final 3D model, highlighting areas for future refinement.
FlexiDreamer represents a significant leap forward in the field of 3D content generation, offering a rapid, high-fidelity solution to single-image 3D reconstruction. As the technology continues to evolve, it holds the promise of transforming a wide range of industries, from digital media and entertainment to virtual reality and beyond. However, the ethical implications and current limitations of the framework serve as a reminder of the ongoing challenges in the quest for perfecting 3D reconstruction technology.