Expanding Access and Enhancing Efficiency in AI Language Training
- Innovative Efficiency: OpenELM introduces a novel layer-wise scaling strategy in its transformer architecture, optimizing parameter allocation to significantly improve model accuracy with fewer resources.
- Transparency and Reproducibility: Unlike traditional practices, OpenELM’s full training and inference framework, including logs and configurations, is made open-source, promoting transparency and aiding reproducibility in AI research.
- Resource Accessibility: By requiring fewer pre-training tokens and providing full compatibility with widely-used public datasets, OpenELM democratizes access to cutting-edge AI technologies, particularly for researchers with limited resources.
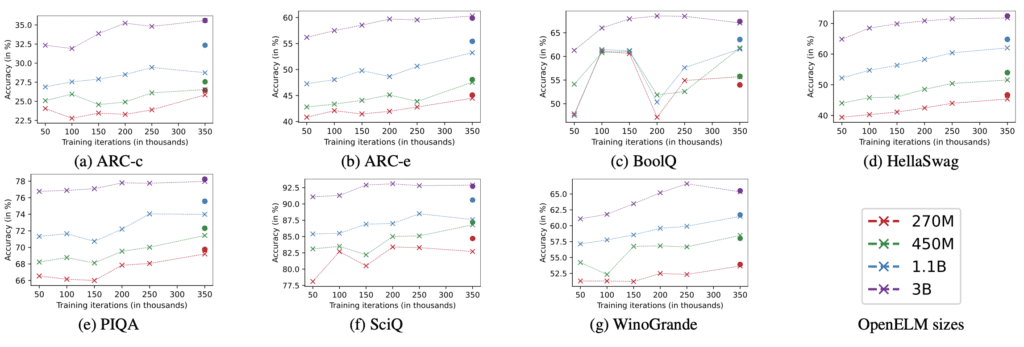
The field of AI research stands on the brink of a transformative era with the introduction of OpenELM, a state-of-the-art open-source language model designed to enhance accuracy and efficiency in AI language processing. Developed with a unique layer-wise scaling strategy, OpenELM allocates parameters within each layer of its transformer model more effectively, achieving a 2.36% improvement in accuracy over its predecessor, OLMo, while consuming only half the pre-training tokens.
Empowering Open Research
OpenELM’s release marks a significant departure from previous practices in the AI industry, which typically shroud AI developments in secrecy. By providing complete access to its training framework, OpenELM enables researchers worldwide to replicate, verify, and build upon its findings. This openness is not just about fostering transparency but also about empowering a broader range of institutions to contribute to, and benefit from, advanced AI research.
Strategic Resource Utilization
With models available in four sizes (270M, 450M, 1.1B, and 3B parameters), OpenELM is designed to be accessible and practical for a variety of use cases, from academic research to industry applications. Its efficient use of training data, sourced from publicly available datasets like RefinedWeb and The PILE, underscores its commitment to making high-performance AI more accessible.
Comprehensive Open-Source Release
The OpenELM project goes beyond just sharing the model weights. It includes detailed logs, multiple checkpoints, and configurations that guide users through the model’s training processes, fostering a deeper understanding and enabling precise tweaks for specific needs. Additionally, the inclusion of MLX library conversion codes extends the model’s utility to Apple devices, broadening its applicability.
Looking Ahead
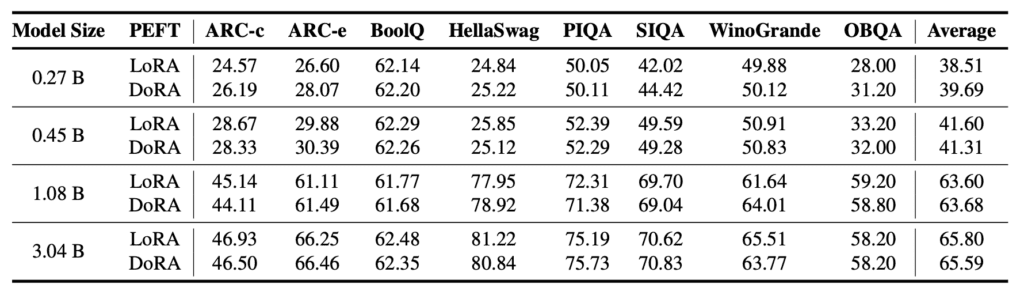
OpenELM’s approach not only sets a new standard for model efficiency and open accessibility but also lays the groundwork for future innovations in AI language modeling. The model’s adaptability and the potential for fine-tuning with various strategies, including LoRA and DoRA, indicate a robust framework capable of evolving with the growing demands of AI applications.

By redefining what is possible in the realm of open-source AI, OpenELM not only advances the technological frontier but also ensures that the benefits of these advancements are shared more broadly across the global research community. This initiative may well inspire a new wave of innovation, characterized by greater collaboration and accelerated discovery in AI.