How a single encoder is bridging the gap between LiDAR, CAD, and robotics to create a foundation for spatial cognition.
- A Unified Framework: Utonia introduces a single, self-supervised point transformer encoder capable of processing point clouds from wildly different domains, from city-scale LiDAR to fine-grained CAD models.
- Breaking Domain Barriers: By addressing cross-domain mismatches with domain-agnostic designs, Utonia creates a shared representation space that enhances 3D perception and enables emergent cross-domain intelligence.
- Beyond Simple Recognition: Utonia’s features significantly improve robotic manipulation and spatial reasoning in vision-language models, setting the stage for future 4D-aware foundation models for the physical world.

For years, the field of artificial intelligence has dreamed of a “universal” model—a single brain capable of understanding the world regardless of how that data is collected. While we have seen massive strides in text and 2D images, the 3D world has remained fragmented. Point clouds, the sparse and unstructured data points that represent our physical reality, come from a dizzying array of sources: spinning LiDAR on autonomous cars, RGB-D cameras in living rooms, and synthetic CAD models in design studios. Until now, these domains were treated as separate silos. Utonia changes that narrative, serving as a first step toward a single encoder that can “speak” the language of every point cloud.
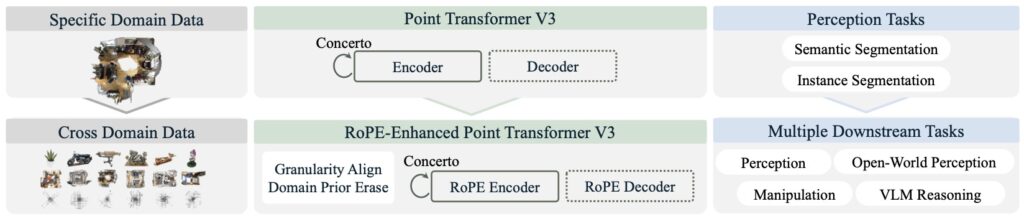
The challenge of unifying 3D data lies in its inherent messiness. Unlike images, which live on a standard, predictable grid, point clouds are sparse and vary wildly in density, scale, and sensor patterns. An outdoor LiDAR scan might stretch across a city block with characteristic “scan-line” artifacts, while an indoor object scan is dense, tiny, and rich with color. Traditionally, these differences forced researchers to build domain-specific models. Utonia breaks this cycle by identifying cross-domain mismatches and solving them with minimal, domain-agnostic designs. This allows a single transformer-based encoder to learn a consistent representation space that transfers seamlessly from a city-level intersection to the fine-grained geometry of a household object.
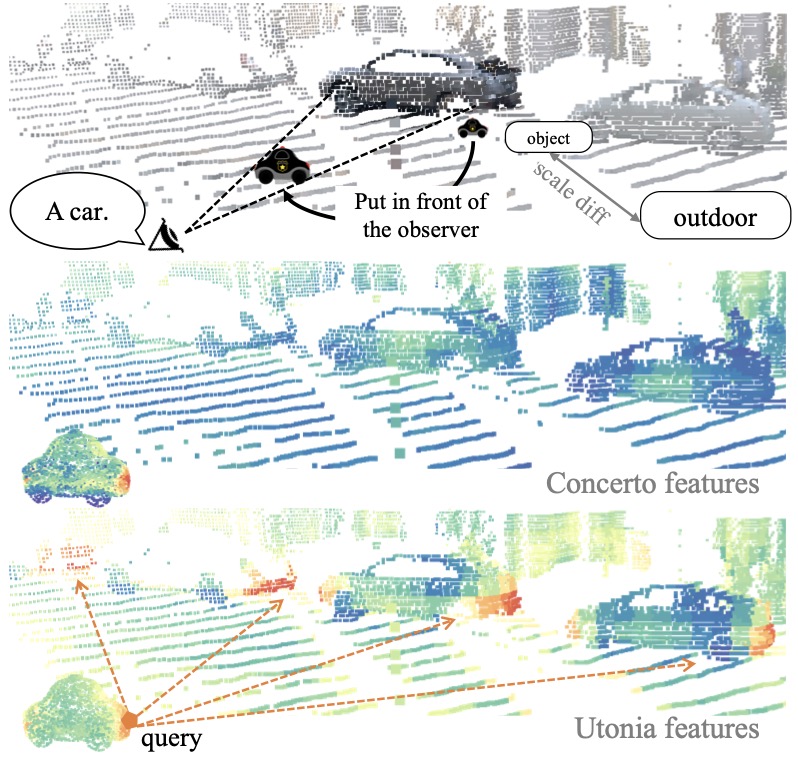
What makes Utonia truly remarkable is the emergence of cross-domain benefits. When these diverse data sources are trained jointly, the model begins to exhibit “emergent behaviors”—capabilities that don’t appear when domains are trained in isolation. By visualizing these features through PCA projections, researchers have observed a striking consistency: the model maintains its geometric “understanding” even as it zooms from a city-scale scene down to a single street corner, and finally to an individual object. This suggests that Utonia isn’t just memorizing patterns; it is learning the fundamental rules of 3D geometry.
The impact of this unification extends far beyond simple 3D perception. Utonia is already proving its worth in the realms of embodied AI and multimodal reasoning. When integrated into Vision-Language-Action (VLA) policies, Utonia’s features help robots manipulate objects more effectively. In Vision-Language Models (VLMs), it provides a boost to spatial reasoning, helping AI understand where things are in relation to one another. By providing a “geometry-first” interface, Utonia acts as a compact yet expressive foundation that complements traditional video-based models, offering a more efficient way to compress the physical world without losing its structural integrity.

The road to total spatial cognition involves three key frontiers. First is the move toward query-based task interfaces, which will allow the model to retrieve specific, fine-grained information for complex tasks like part segmentation. Second is the leap into 4D spatial cognition, where the model learns to understand motion and time-evolving changes rather than just static snapshots. Finally, there is the need for scalable next-generation backbones that move away from memory-heavy sparse convolutions toward hardware-friendly architectures. As Utonia continues to evolve, it promises to become the foundational backbone for everything from AR/VR headsets to the autonomous vehicles of tomorrow.