A new hypernetwork framework injects repository-level knowledge directly into model parameters, eliminating the hidden costs of long inputs and keeping pace with evolving code.
- The Context Bottleneck: Current AI coding assistants rely on costly, token-heavy retrieval methods (RAG) or brittle fine-tuning to understand the massive context of entire software repositories.
- A Parametric Solution: Code2LoRA introduces a hypernetwork that generates custom, repository-specific LoRA adapters, injecting vital project knowledge with zero inference-time token overhead.
- Adapting to Software Evolution: Featuring both “Static” and “Evo” modes, the framework adapts to both stable codebases and active development environments, proving its efficacy on a newly established benchmark of 604 Python repositories.
Modern software development doesn’t happen in a vacuum. Real-world codebases span thousands of files containing complex imports, distinct APIs, and strict project conventions. For an AI language model to be genuinely helpful—whether it is completing assertions, navigating a project, or squashing bugs—it must possess a deep understanding of this repository-level context.
Historically, providing this context has been a heavy lift. Today’s large language model (LLM) coding assistants typically rely on injecting repository knowledge as massive, long inputs. Through Retrieval-Augmented Generation (RAG) or dependency analysis, relevant files are pulled and fed to the model at query time. This approach is notoriously expensive; it maxes out context windows and stresses retrieval pipelines, forcing developers to pay for that retrieved context on every single query. The alternative—fine-tuning the model or using standard LoRA (Low-Rank Adaptation) adapters for a specific repository—is equally flawed. Standard fine-tuning requires costly, repetitive training and is incredibly brittle when faced with evolving codebases, where a single commit can render an adapter obsolete.
Enter Code2LoRA: Zero-Overhead Knowledge Injection
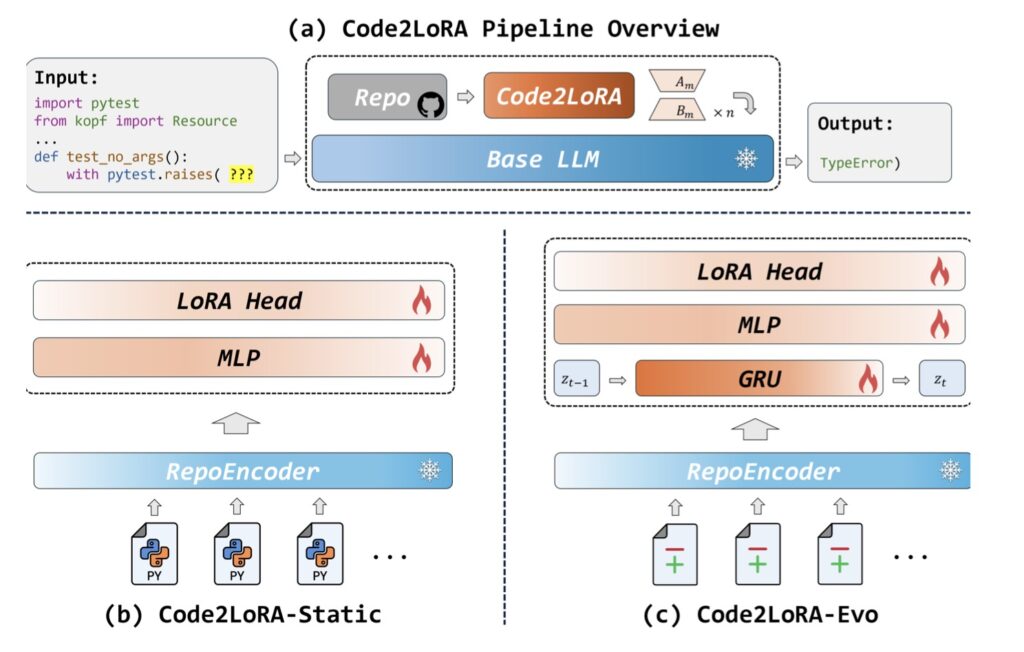
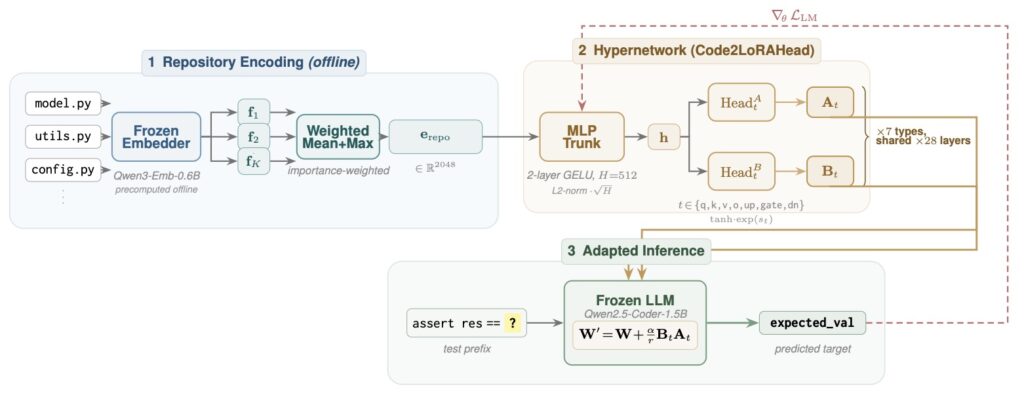
To solve this, researchers have introduced Code2LoRA, a groundbreaking hypernetwork framework designed to generate repository-specific LoRA adapters. Instead of forcing an LLM to read through retrieved files at inference time, Code2LoRA uses a single forward pass over a conditioning input to produce task-specific weights for a frozen LLM.
The result? Repository knowledge is injected parametrically. The model simply “knows” the context, requiring zero inference-time token overhead. While previous hypernetwork approaches were limited to short, natural-language tasks or static documents, Code2LoRA is explicitly engineered to handle the massive scope and constant flux of real-world software repositories.
Two Flavors for Real-World Development
Because software ranges from legacy archives to highly active development branches, Code2LoRA was designed around two orthogonal axes: how knowledge enters the parameters, and when it is updated. This results in two distinct usage scenarios:
- Code2LoRA-Static: Designed for the comprehension of stable codebases. This version converts a single, massive repository snapshot directly into a functional adapter.
- Code2LoRA-Evo: Built for the chaotic reality of active development. Rather than replacing the snapshot every time code changes, Code2LoRA-Evo maintains an adapter backed by a GRU (Gated Recurrent Unit) hidden state. This state is updated per code diff, allowing the model’s understanding to evolve in real-time alongside the codebase.
Putting Code2LoRA to the Test: RepoPeftBench
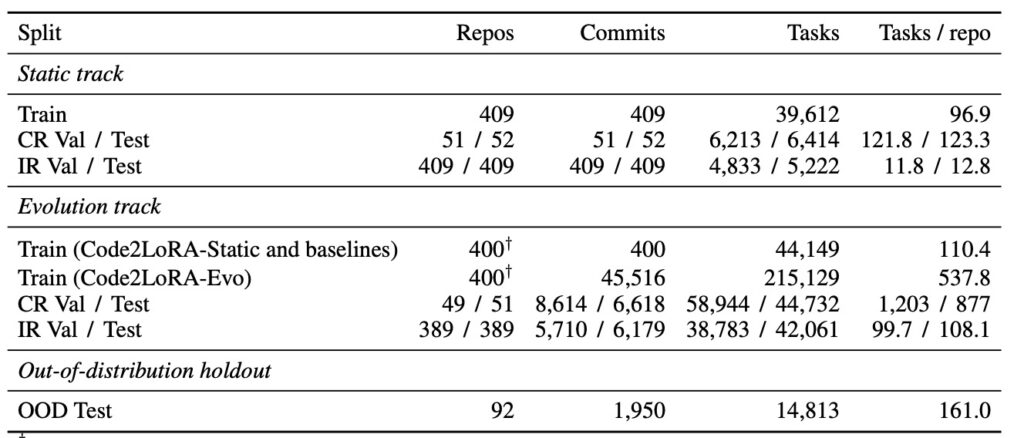
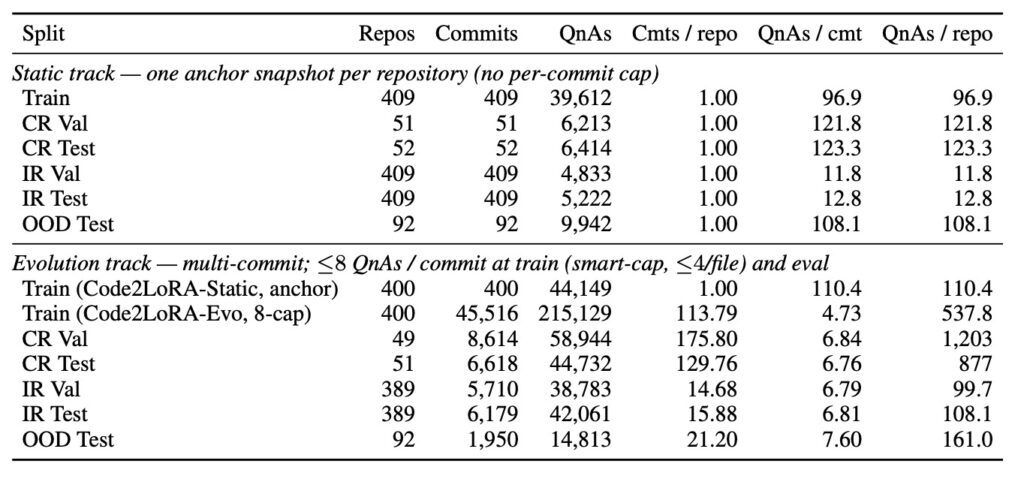
To rigorously evaluate this new architecture against existing parameter-efficient fine-tuning (PEFT) baselines, researchers built RepoPeftBench. This massive benchmark comprises 604 Python repositories and is divided into two distinct testing tracks focused on assertion completion tasks.
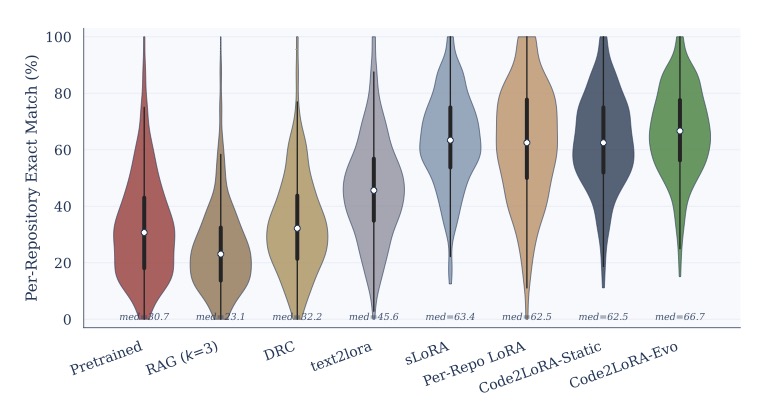
On the Static Track (40K training and 12K test tasks), the results were striking. Code2LoRA-Static achieved a 63.8% Cross-Repo (CR) and 66.2% In-Repo (IR) Exact Match rate, effectively matching the upper bound of costly, per-repository LoRA training.
The Evolution Track (215K training and 87K test tasks derived from commits) proved the framework’s ability to learn over time. Code2LoRA-Evo achieved a 60.3% CR and 64.5% IR Exact Match, beating a single shared LoRA baseline by 5.2 percentage points. Furthermore, the framework demonstrated strong generalization capabilities on out-of-distribution (OOD) repositories, scoring a 74.1% exact match—outperforming the next-best fine-tuned adapter by roughly 1.8 percentage points.
Understanding the Scope and Future Potential
While the results are highly promising, the researchers are transparent about the current scope of the project. The evaluation was conducted exclusively on Python repositories using a single frozen backbone (Qwen2.5-Coder-1.5B). Additionally, while exact match metrics are standard, they can miss functional equivalence—a limitation researchers mitigated by using EditSim, CodeBLEU, and pytest-based execution probes.
It is also worth noting the computational footprint of the hypernetwork itself. The LoRA-generation hypernetwork dominates the trainable parameter count, utilizing roughly 720M parameters for the Static version and 745M for the Evo version. Whether the recurrent aggregation over commit diffs scales effectively to much larger foundation models remains an exciting open question for future research.
Despite these scoped limitations, Code2LoRA proves that repository knowledge is best injected parametrically and updated to track software evolution, rather than being brute-forced through long input contexts. As the framework expands to become language- and task-agnostic, Code2LoRA is poised to serve as a foundational building block for the next generation of AI code assistants—making them stronger, deeply customizable to local environments, and vastly more cost-effective.