A new 200-million-parameter foundation model brings powerful zero-shot capabilities to retail, finance, and beyond—without the need for exhaustive retraining.
- A New Era of Forecasting: Google Research has developed TimesFM, a decoder-only foundation model pre-trained on a massive corpus of 100 billion real-world time points.
- Zero-Shot Power: Unlike traditional deep learning models that require lengthy, domain-specific training cycles, TimesFM delivers highly accurate, out-of-the-box predictions on unseen data.
- Smart Architecture: By treating groups of time-points as “patches” and utilizing a blend of synthetic and real-world training data, TimesFM rivals or outperforms state-of-the-art supervised models despite its relatively small size.
Time-series forecasting is the invisible engine driving decision-making across almost every major industry. Whether it is predicting patient admissions in healthcare, anticipating market shifts in finance, or optimizing supply chains in manufacturing, seeing into the future is a critical capability. In retail, for instance, even a marginal improvement in demand forecasting accuracy can significantly reduce inventory costs and boost revenue.
Historically, data scientists have relied on statistical methods or, more recently, deep learning (DL) models. While DL models (like those that dominated the M5 competition) have proven incredibly effective for multivariate time-series data, they come with a catch: they require long, involved, and expensive training and validation cycles before they can be deployed on a new dataset.
But what if a model could predict the future right out of the box?
The Foundation Model Revolution
In the realm of Natural Language Processing (NLP), Large Language Models (LLMs) have changed the paradigm. Trained on massive datasets like Common Crawl, models used for translation, retrieval-augmented generation, and code completion can identify profound patterns, making them incredibly powerful “zero-shot” tools—meaning they can perform tasks they weren’t explicitly trained to do.
In a paper accepted at ICML 2024, Google Research bridges this gap with TimesFM (Time Series Foundation Model). TimesFM takes the core philosophy of LLMs and applies it to numerical forecasting. It is a single forecasting model that provides highly accurate out-of-the-box forecasts on unseen time-series data, allowing users to bypass tedious training cycles and focus immediately on refining their downstream tasks.
Despite having a relatively small footprint of just 200 million parameters compared to today’s massive LLMs, TimesFM’s zero-shot performance comes remarkably close to—and often matches—state-of-the-art supervised approaches.
Under the Hood: Decoding TimesFM
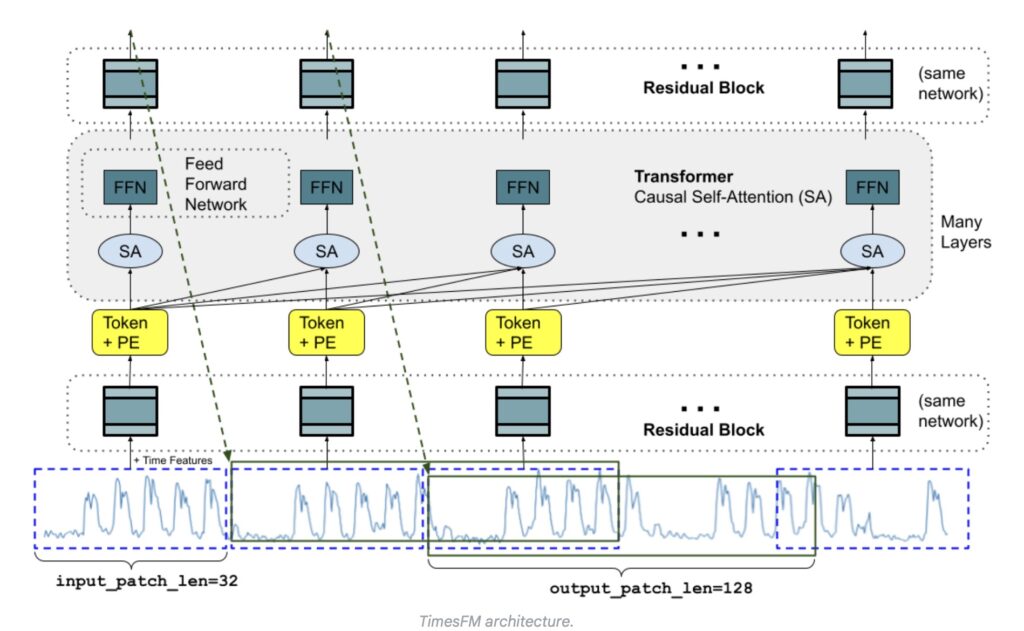
LLMs operate in a decoder-only fashion: they break text down into tokens, process them through stacked causal transformer layers, and predict the next token in a sequence based on everything that came before it. TimesFM adapts this architecture to handle the variable contexts and horizon lengths inherent in time-series data.
However, predicting numbers is not the same as predicting words. TimesFM introduces several key innovations:
- Patching as Tokens: Instead of individual words, TimesFM treats a “patch”—a group of contiguous time-points—as a single token.
- Translation Layers: The model utilizes a multilayer perceptron block with residual connections to convert these time-series patches into tokens. These are then fed into transformer layers alongside positional encodings (PE).
- Asymmetric Patch Lengths: In language generation, one token predicts the next single token. In TimesFM, an output token can predict a sequence of time-points much longer than the input patch. For example, an input patch of 32 time-points might be used to forecast the next 128. This drastically reduces the number of generation steps required for long-horizon forecasting, which in turn prevents errors from accumulating over time.
The Diet of a Forecasting Giant
Just as language models require vast amounts of text to learn grammar and context, TimesFM required a massive, high-quality dataset to learn the rhythm of time. Google Research curated a specialized corpus of 100 billion time-points using a two-pronged approach:
- Synthetic Data for the “Grammar”: By utilizing statistical models and physical simulations, researchers generated basic temporal patterns. This taught the model the fundamental “rules” of time-series movements.
- Real-World Data for the “Flavor”: To help the model understand the bigger picture, the training corpus was heavily supplemented with real-world data, including Google Trends and Wikipedia Pageviews. Because human search interests naturally mirror trends in finance, retail, and economics, this data allowed TimesFM to generalize remarkably well when faced with entirely new, domain-specific contexts.
Proven Zero-Shot Performance
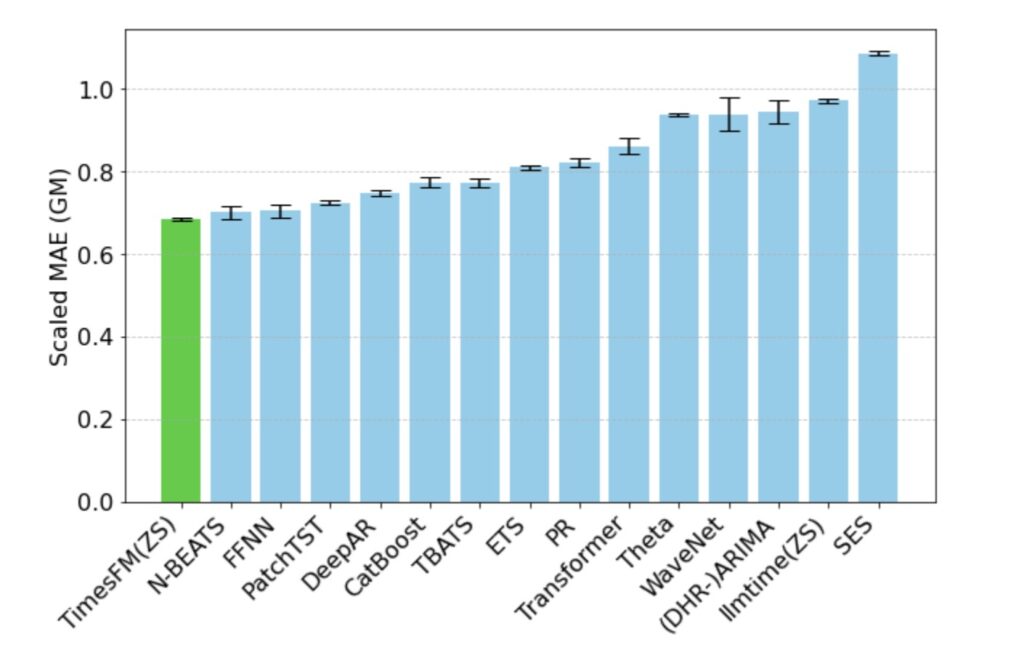
The true test of a foundation model is how it handles data it has never seen before. When evaluated on the Monash Forecasting Archive—a massive collection of time-series data spanning traffic, weather, and demand at various frequencies—TimesFM’s out-of-the-box performance was stellar.
Looking at the scaled Mean Absolute Error (MAE), zero-shot TimesFM consistently outperformed traditional statistical methods like ARIMA and ETS. More impressively, it bested specialized LLM prompting techniques like GPT-3.5 (llmtime), despite being orders of magnitude smaller.
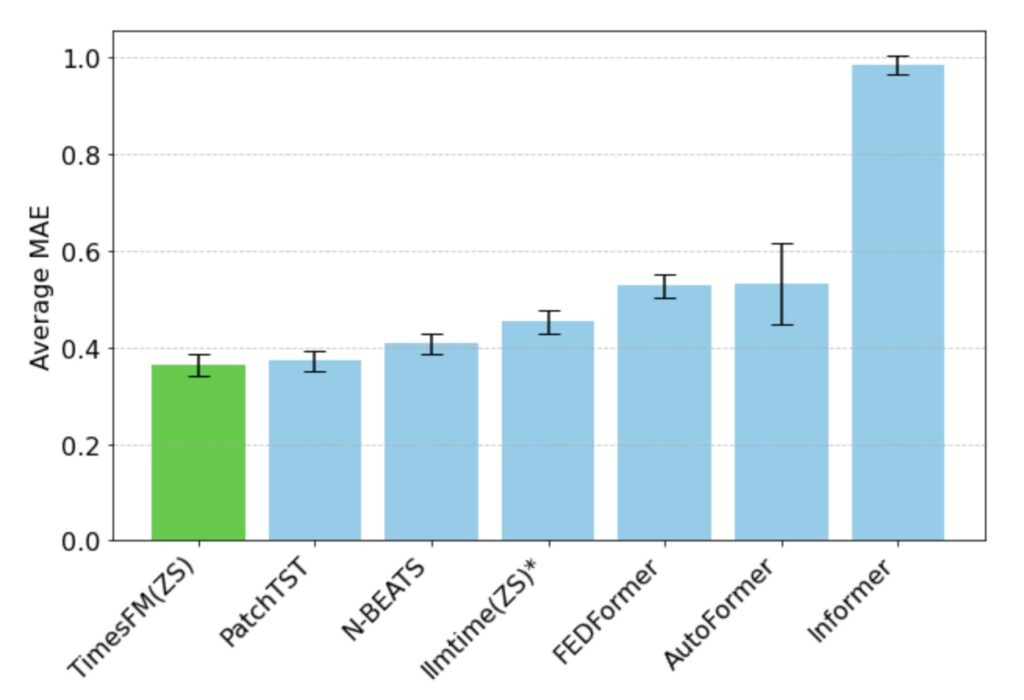
When tested on long-horizon forecasting benchmarks (such as the ETT datasets predicting 96 to 192 time-points into the future), TimesFM didn’t just beat zero-shot competitors; it matched the performance of powerful, explicitly trained deep learning models like DeepAR and PatchTST.
The Future is Open
Google Research’s TimesFM proves that the foundation model paradigm isn’t just for text and images. By pre-training a specialized, decoder-only architecture on 100 billion diverse time-points, TimesFM delivers a lightweight, highly capable tool that democratizes advanced forecasting. For data scientists and businesses looking to leverage state-of-the-art predictions without the heavy compute costs of starting from scratch, the future is already here.