Shanghai AI Lab’s SU-01 model proves that massive parameter counts aren’t the only path to elite mathematical and scientific problem-solving.
- A Paradigm Shift in AI Sizing: Shanghai AI Lab has demonstrated that a general-size 30B-A3B model can achieve gold-medal-level performance on elite competitions like IMO 2025, USAMO 2026, and IPhO 2024/2025 without relying on massive scale or external tools.
- A Unified Three-Step Recipe: The model’s success is built on a simple, reusable loop consisting of reverse-perplexity Supervised Fine-Tuning (SFT), two-stage Reinforcement Learning (RL), and inference-time scaling (Test-Time Scaling).
- Ingenious Frameworks alongside Structural Limitations: While the AI excels at translating complex problems into rigid formal frameworks (like using complex numbers for geometry), it still struggles with tasks requiring delicate combinatorial structures or finely tuned global strategies.
In the fast-paced world of artificial intelligence, the prevailing wisdom has often been “bigger is better.” For years, the pursuit of elite reasoning capabilities seemed permanently tied to building ever-larger neural networks and discipline-specific external systems. However, a recent breakthrough by the Shanghai Artificial Intelligence Laboratory (Shanghai AI Lab) is challenging this narrative from a much broader perspective. Through their newly introduced SU-01 pipeline, researchers have proven that Olympiad-level scientific reasoning does not require an extremely large backbone. Instead, a general-size 30B-A3B model, when guided by appropriate behavior shaping, reward learning, and inference-time scaling, can unlock verifiable, long-horizon proof-search abilities.
This development represents a profound shift toward a “specializable-generalist” view of compact reasoning models. By proving that a broadly capable backbone can be transformed into an expert-level mathematical and physical reasoner, SU-01 highlights a future where highly advanced AI tools could become more efficient and accessible. The secret to this success lies in a unified post-training recipe—a meticulously designed training-inference loop that teaches the AI not just to answer, but to rigorously reason, verify, and revise.
Instilling Rigor Through Supervised Fine-Tuning
The foundation of the SU-01 pipeline is built on Supervised Fine-Tuning (SFT), which is designed to reshape the model’s foundational reasoning behavior. Rather than simply feeding the model raw data, the researchers curated a pool of prompts from a broad mixture of mathematical, scientific, instruction-following, and coding sources. After filtering out contaminated problems, they utilized DeepSeek-V3.2-Speciale to generate high-quality, long-form reasoning trajectories.
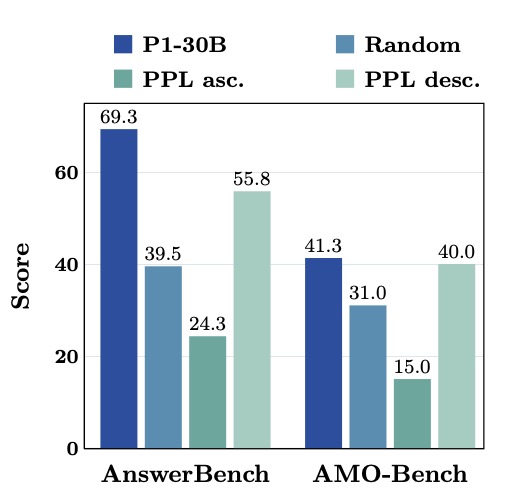
To ensure the supervised signal remained focused on usable reasoning traces, the team filtered out noisy generations and capped trajectories at 8,192 tokens. This prevented the introduction of unstable optimization or truncation issues. The true innovation in this stage, however, is the “reverse-perplexity curriculum.” Within each training epoch, examples are sorted by descending perplexity (PPL). This means the model tackles the hardest, most mismatched teacher trajectories first, gradually consolidating its learning on easier, lower-PPL samples. This stabilizes the learning process and successfully installs the rigorous reasoning patterns needed for the challenges ahead.
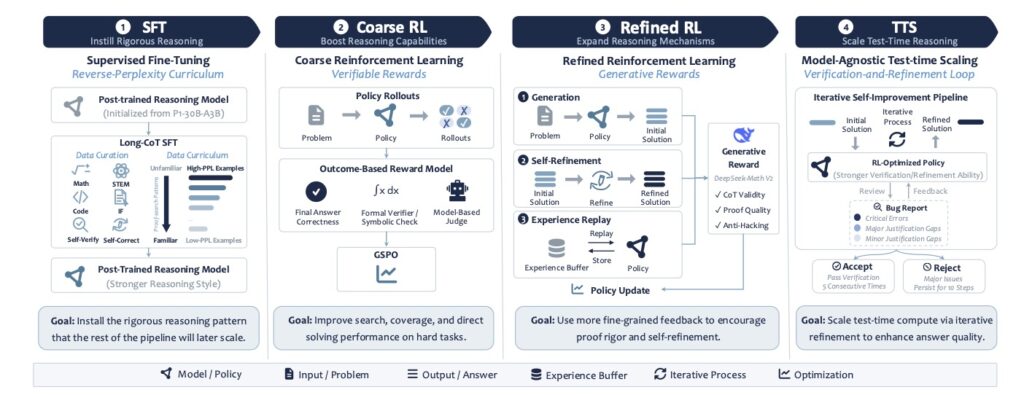
Boosting Capability with Two-Stage Reinforcement Learning
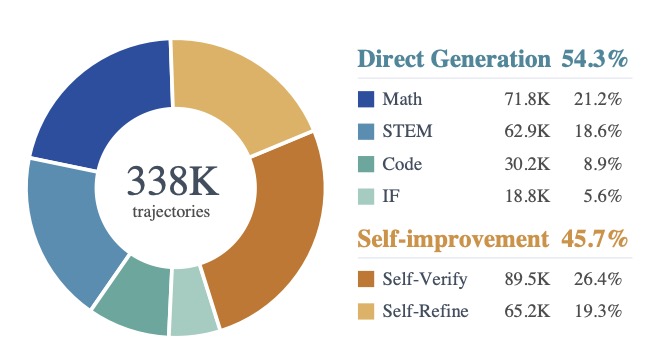
Once the long-form reasoning pattern is installed, SU-01 employs a two-stage reinforcement learning process to drastically scale its solving capability based on a pool of 338K high-quality trajectories. The RL data is split into 8,967 verifiable prompts (where answers can be reliably checked) and 16,287 non-verifiable prompts (for open-ended reasoning).
The first stage, Coarse RL, utilizes reinforcement learning with verifiable rewards (RLVR) and Group Sequence Policy Optimization (GSPO). This phase applies reward assignment at the complete-response level to build the model’s foundational search ability. Following this, the Refined RL stage shifts the focus entirely to proof quality. By using stronger process-level rewards, self-refinement, and experience replay, the model learns to repair its own failures. This ensures that rare, successful proofs remain learnable and ingrained in the model’s memory.
Achieving Gold via Test-Time Scaling
Even with exceptional training, the hardest problems from the International Mathematical Olympiad (IMO) require massive amounts of search and verification. This is where Test-Time Scaling (TTS) elevating SU-01 to its gold-medal status. Unlike basic answer sampling, TTS functions as a multi-round generate-verify-revise loop. Through iterative cycles—generating a candidate solution, verifying the proof, locating hidden gaps, and refining the argument—the model transforms incomplete attempts into scorable solutions.
Remarkably, this is achieved entirely through the model’s own natural language computation, without calling external tools, executing code, or relying on dedicated symbolic solvers. The scale of this computation is staggering: on the USAMO 2026, the initial solution generation had a median length of roughly 106K tokens, with refinement stages averaging around 83K tokens. By sustaining reasoning trajectories beyond 100K tokens, SU-01 effectively repairs arguments and identifies logical gaps on the fly.
Olympiad Triumphs: Ingenious Analytic Reformulations
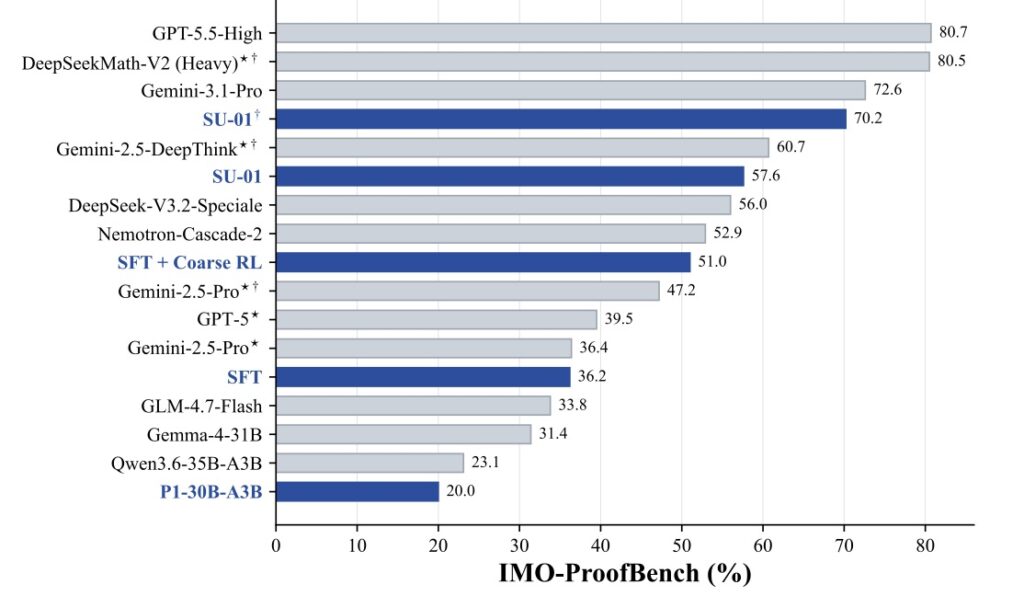
The results of this simple and unified scaling recipe are spectacular. In competition-style evaluations, SU-01 scored 35 points on both IMO 2025 and USAMO 2026, securing gold-medal-level performance. It also exceeded the gold cutoff for IPhO 2024/2025 and substantially outperformed similarly sized models on proof-level benchmarks like ProofBench. Out of twelve problems across IMO 2025 and USAMO 2026, SU-01 delivered full-credit solutions to ten.
The model’s primary strength lies in translating complex Olympiad problems into rigid formal frameworks. A striking example is USAMO 2026 P3. Instead of relying on traditional synthetic geometry and angle chasing, SU-01 elegantly employed complex numbers to unify the unit circle, equilateral-triangle rotations, chord relations, and tangent conditions into a single algebraic framework. Similarly, for IMO 2025 P2, it brilliantly reduced a two-circle tangency problem to coordinate and distance computations. Other standout performances included a carry-state dynamic programming approach for USAMO P4 and a complex number-theoretic proof for USAMO P6 utilizing totients, congruences, Vieta jumping, and Fibonacci structures.
The Achilles’ Heel: Navigating Structural Limitations
Despite its extraordinary successes, SU-01 is not without its flaws. The two problems it failed to solve—IMO 2025 P6 and USAMO 2026 P2—highlight a clear limitation in its current architecture. While the model thrives when a problem admits a rigid formal representation (like coordinates or modular classifications), it struggles with subtle structural constraints.
In IMO P6, the model faltered due to an invalid column-permutation reduction. In USAMO P2, it left critical gaps in delicate global strategy arguments. These failures reveal that preserving combinatorial structure and proving finely tuned process invariants remain significant hurdles for compact AI models.
Shanghai AI Lab’s SU-01 represents a massive leap forward in democratizing high-level scientific reasoning. By decomposing rigorous reasoning improvement into behavior shaping, scalable reward feedback, proof-level specialization, and inference-time repair, they have crafted a model that punches far above its weight class. Furthermore, the model has shown promising transferability to scientific domains beyond its main math and physics training signals.
As research continues, the focus will undoubtedly shift toward addressing these combinatorial limitations through more reliable reward modeling, advanced proof-level evaluation, and the joint optimization of training and inference. For now, SU-01 stands as a testament to the power of efficient, unified scaling—proving that with the right recipe, a compact generalist can indeed become a gold-medal specialist.