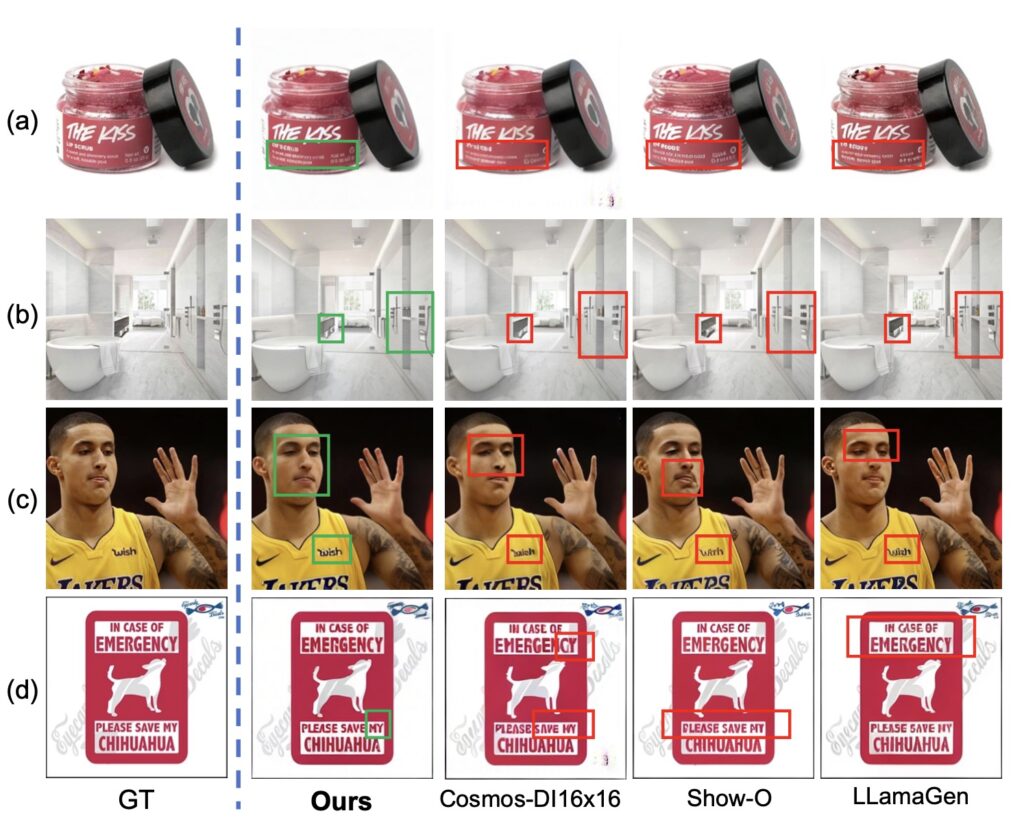
Overcoming the 3D data bottleneck by unifying text, 2D images, and 3D geometry into a single, seamless foundation model.
- The 3D Data Bottleneck: While 2D generative AI thrives on nearly infinite web data, the evolution of 3D generation has been severely stifled by a scarcity of high-quality 3D assets.
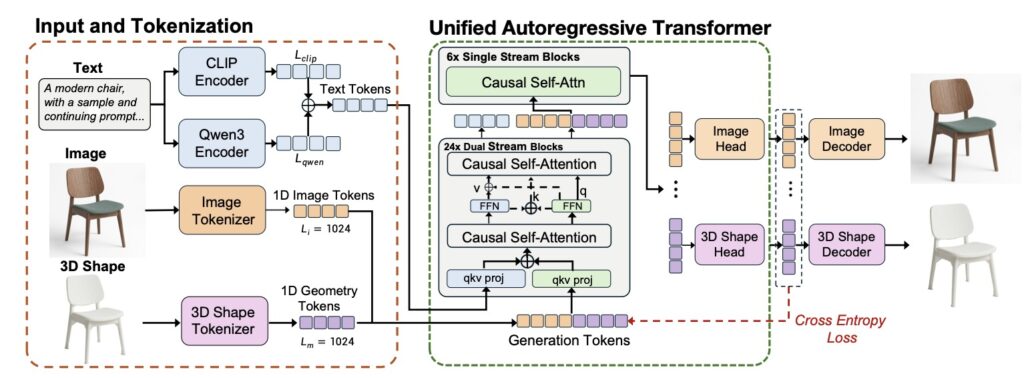
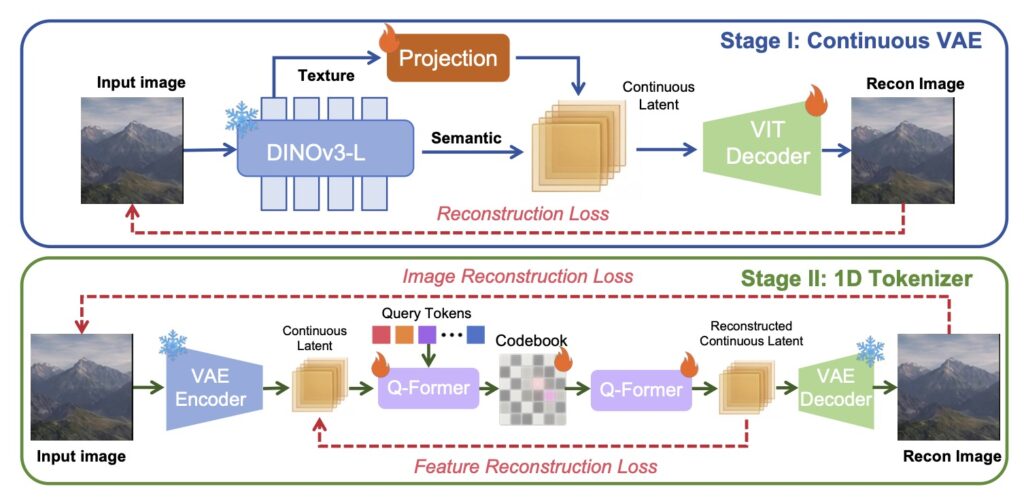
- A Unified Solution: Omni123 elegantly bypasses this data shortage by tokenizing text, 2D images, and 3D geometry into a shared sequence space, using abundant 2D visuals as a structural guide for 3D generation.
- A New Training Paradigm: Through an innovative three-stage “X-to-X” training cycle, Omni123 avoids the pitfalls of competing generative tasks, delivering unprecedented geometric consistency and paving the way for fully immersive, multimodal virtual worlds.

The generative AI landscape has recently undergone a tectonic shift. We have moved from simple text generators to unified multimodal giants capable of jointly reasoning across linguistic and visual domains. With powerhouse models like GPT-4o and Nano-Banana enabling stunningly high-fidelity synthesis and instruction-guided editing in 2D, the community’s gaze has naturally shifted toward the next great frontier: immersive digital environments. The ultimate quest is to build the “3D Nano-Banana”—a unified framework capable of native 3D generation and editing. Such a leap forward is the missing puzzle piece for embodied AI and the autonomous synthesis of virtual worlds. Yet, bridging the gap from two dimensions to three remains an incredibly complex, open challenge.
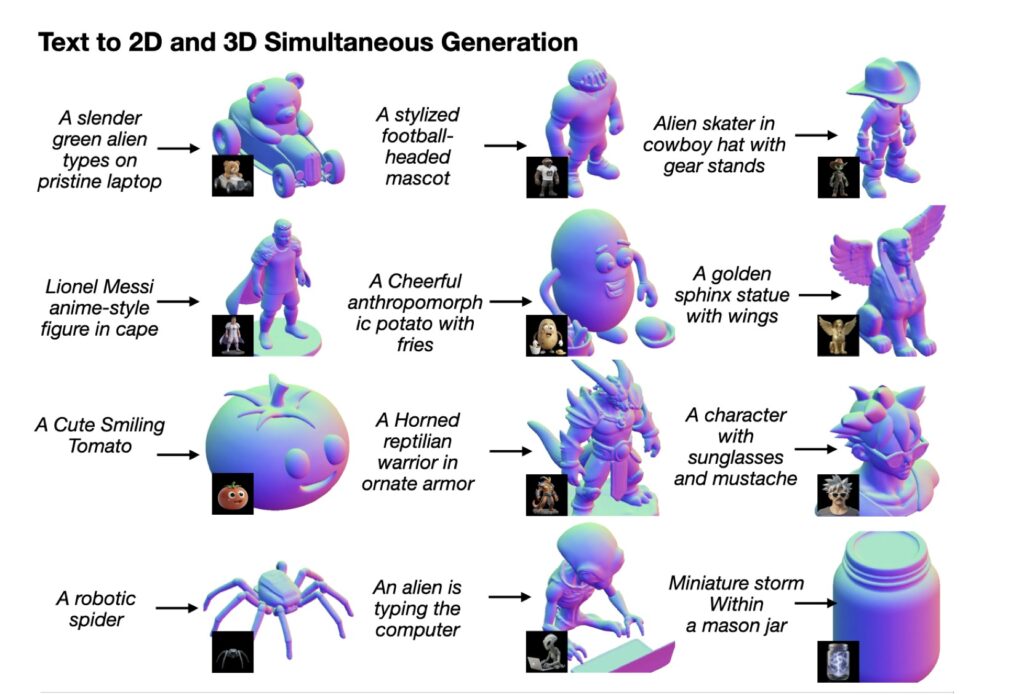
The core bottleneck holding back this 3D revolution is surprisingly simple: data. Unlike 2D artificial intelligence generated content (AIGC), which feasts on the near-infinite buffet of imagery available across the web, 3D generation suffers from acute data scarcity. High-quality 3D assets are orders of magnitude rarer than 2D pictures. This massive disparity leaves 3D synthesis inherently under-constrained, especially when models are trying to generate complex shapes using only sparse supervision from a simple text prompt or a single viewing angle.

Historically, developers have tried to cheat this limitation by using 2D images as an intermediate proxy. These indirect pipelines edit an object in a flat 2D image space and then attempt to “lift” those results into 3D through a painstaking process of iterative optimization. While clever, these indirect workflows are flawed. They frequently compromise geometric consistency—resulting in warped or illogical shapes from certain angles—and lack the straightforward, elegant nature of native generation. It has become clear that true 3D learning requires much stronger structural constraints than sparse, indirect signals can provide.
This brings us to a pivotal hypothesis: Because 2D visual data already implicitly encodes a wealth of 3D structural information—including object shape, appearance, and spatial relationships—could we leverage the sheer abundance of 2D observations to fortify 3D generation within a unified multimodal framework?
Enter Omni123, a groundbreaking 3D native foundation model designed to do exactly that. Omni123 addresses the 3D data drought by unifying text-to-2D and text-to-3D generation within a single, cohesive autoregressive framework. The key insight behind Omni123 is that cross-modal generative consistency between flat images and 3D shapes can act as an implicit structural constraint. By representing text, 2D images, and 3D geometry as discrete tokens in a shared sequence space, the model effectively uses the massive pool of 2D data as a rich geometric prior to strengthen its 3D representations.
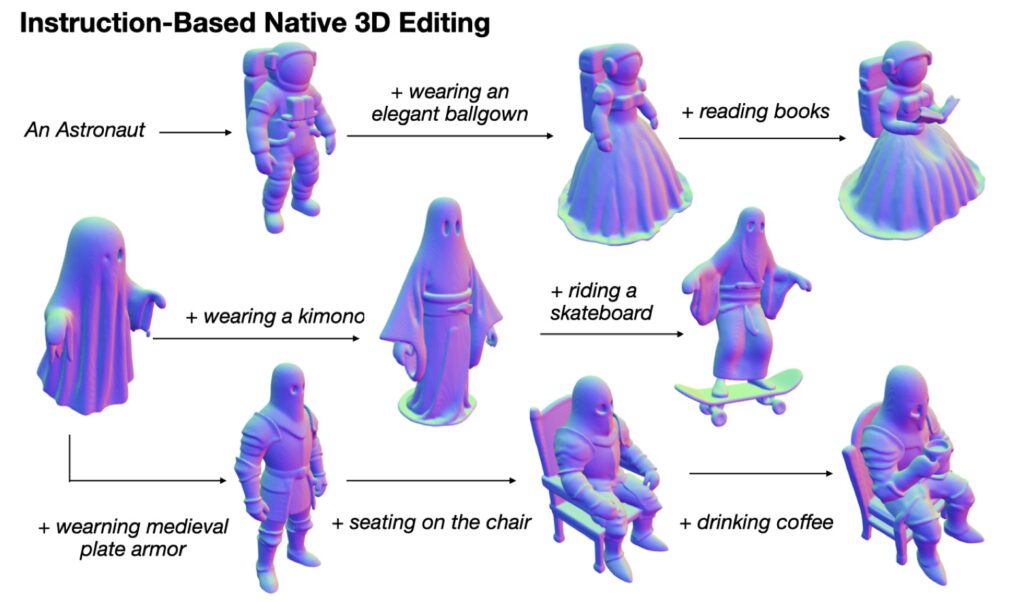
Simply throwing multiple cross-modal tasks together doesn’t guarantee success. Different generative tasks rely on entirely different statistical rules; text-to-image focuses on making things look right (appearance distributions), while text-to-3D requires things to physically make sense (geometric reasoning). Without careful coordination, training these together can cause harmful task interference, where competing gradients degrade the quality of the 3D output.
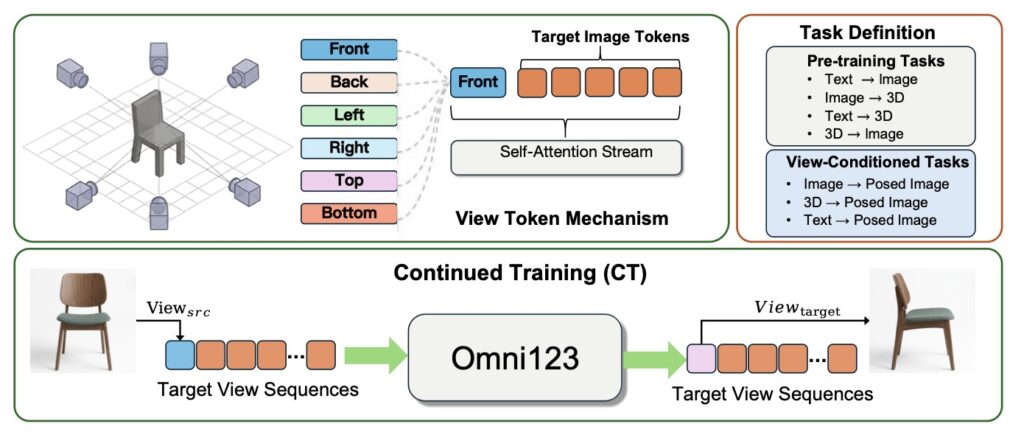
To solve this, the researchers behind Omni123 introduced an ingenious interleaved “X-to-X” training paradigm. This process coordinates diverse cross-modal tasks over heterogeneous paired datasets, entirely removing the need for perfectly aligned “text-image-3D” triplets, which are notoriously hard to find. The training recipe unfolds in three distinct stages:
Cross-modal pre-training over varied datasets to establish a baseline understanding.
Continued training with learnable view tokens to give the model a robust sense of viewpoint awareness.
Text–Image–3D interleaved fine-tuning to close the loop.
By traversing “semantic–visual–geometric” cycles (for example, generating from Text → Image → 3D → Image) within a single autoregressive sequence, the model learns to simultaneously satisfy high-level semantic intent, appearance fidelity, and multi-view geometric consistency.
Extensive experiments have already demonstrated that Omni123 represents a massive leap forward. It significantly improves both geometric consistency and semantic alignment in text-guided 3D generation and editing, proving that unifying 2D and 3D generative processes is not just possible, but highly effective.
While Omni123 is a monumental step, the journey isn’t over. Current limitations include a fixed mesh resolution tied to the 3D tokenizer and a reliance on canonical viewpoints. However, the roadmap for the future is thrilling. Upcoming iterations will aim to explore adaptive-resolution tokenization, expand from single objects to entire scene-level generation, and eventually incorporate complex material and physics modeling. By successfully turning 2D abundance into 3D capability, Omni123 has illuminated a scalable, definitive pathway toward the fully multimodal 3D world models of tomorrow.