Bridging the gap between raw AI generation and precise, real-world control in human-object interaction.
- The Ultimate Multimodal Maestro: ByteDance’s new framework, OmniShow, tackles the complex challenge of Human-Object Interaction Video Generation (HOIVG) by seamlessly blending text, reference images, audio, and pose data into a single, cohesive output.
- Engineering Uncompromised Control: Through innovative architecture like Unified Channel-wise Conditioning and Gated Local-Context Attention, OmniShow eliminates the traditional trade-off between high visual quality and precise user controllability.
- Setting a New Industry Standard: Alongside the OmniShow model, researchers have introduced a novel “Decoupled-Then-Joint” training strategy to combat data scarcity, as well as HOIVG-Bench, a comprehensive new benchmark to evaluate future progress in the field.

The rapid evolution of text-to-video generation models has fundamentally revolutionized how we approach content creation. We have moved quickly from blurry, surreal clips to breathtakingly realistic, human-centric scenarios. Yet, as visually impressive as these models have become, they often fall short when deployed in demanding, real-world applications. Industries such as e-commerce, short video production, and interactive entertainment don’t just need a video that looks good; they require precise, granular control over specific subjects and their dynamic movements. This critical industry demand gives rise to a highly practical yet challenging task known as Human-Object Interaction Video Generation (HOIVG).
The core challenge of HOIVG lies in synthesizing high-quality videos that are simultaneously conditioned on four distinct inputs: a text prompt to dictate global semantics, reference images to lock in specific character and object appearances, audio tracks for perfectly synchronized lip and body movements, and explicit pose sequences to direct motion. Historically, existing approaches have struggled to juggle all these requisite conditions, often forcing creators to choose between visual fidelity and strict controllability.
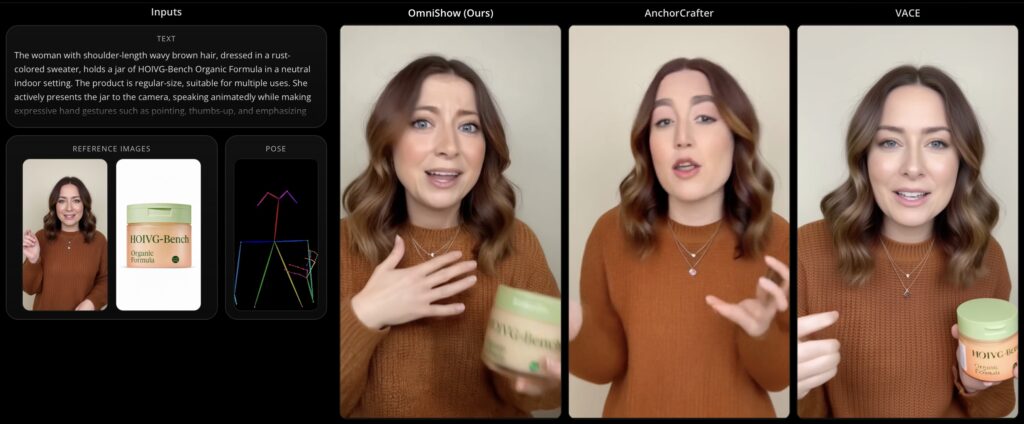
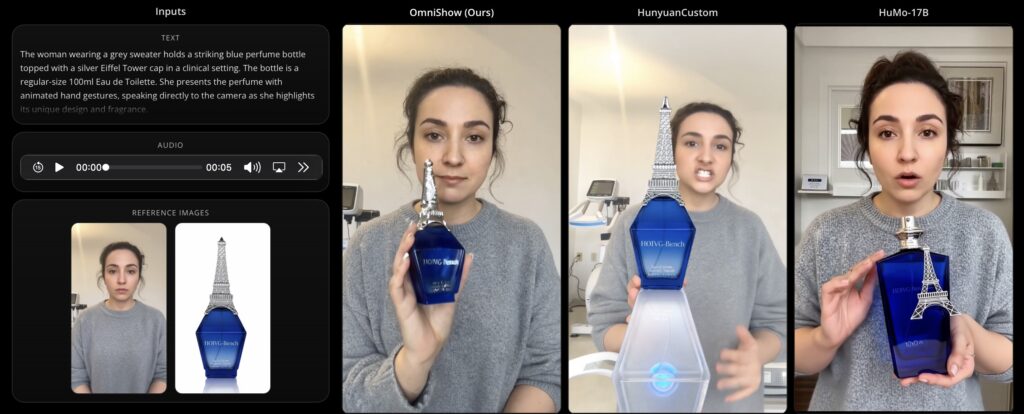
Enter OmniShow, an end-to-end framework developed by ByteDance that is explicitly tailored to master this multimodal juggling act. By orchestrating text, reference images, audio, and pose conditions within a unified system, OmniShow achieves precise multimodal control without sacrificing the high-quality video generation that modern audiences expect. It acts as a digital director, capable of harmonizing diverse inputs to deliver genuinely industry-grade performance.
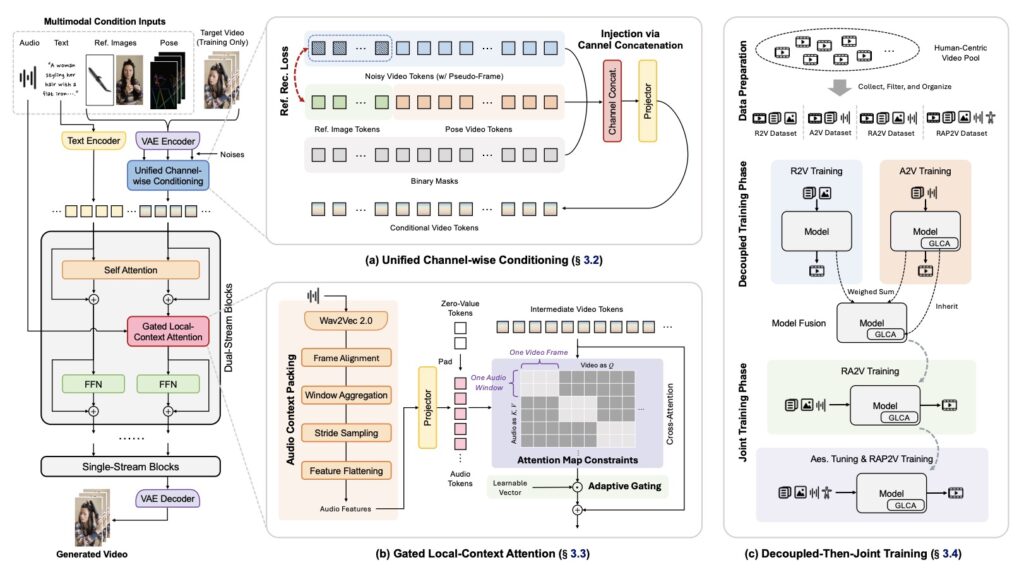
To achieve this breakthrough, the researchers behind OmniShow had to engineer entirely new architectural solutions to overcome the persistent trade-off between controllability and quality. They introduced Unified Channel-wise Conditioning, a sophisticated method for injecting image and pose data efficiently into the generation process. To ensure that a character’s movements—particularly their lips—perfectly match the spoken audio, the team implemented Gated Local-Context Attention, securing precise audio-visual synchronization that is vital for believable human interactions.
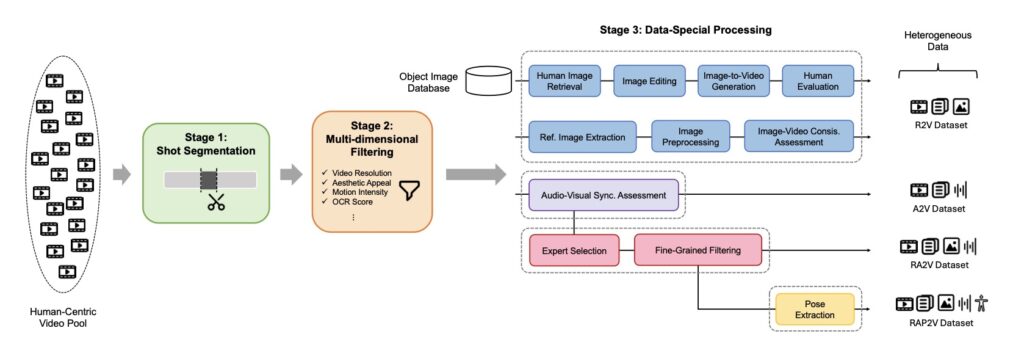
Beyond the architecture itself, the OmniShow project tackles the severe bottleneck of data scarcity in the HOIVG space. Because perfectly annotated datasets containing text, image, audio, and pose data are rare, the team developed a Decoupled-Then-Joint Training strategy. This multi-stage training process leverages model merging, allowing the system to efficiently harness diverse and heterogeneous sub-task datasets to build its comprehensive understanding. Furthermore, recognizing a stark evaluation gap in this emerging field, the creators established HOIVG-Bench, a dedicated and comprehensive benchmark designed to test and validate performance in human-object interaction scenarios.

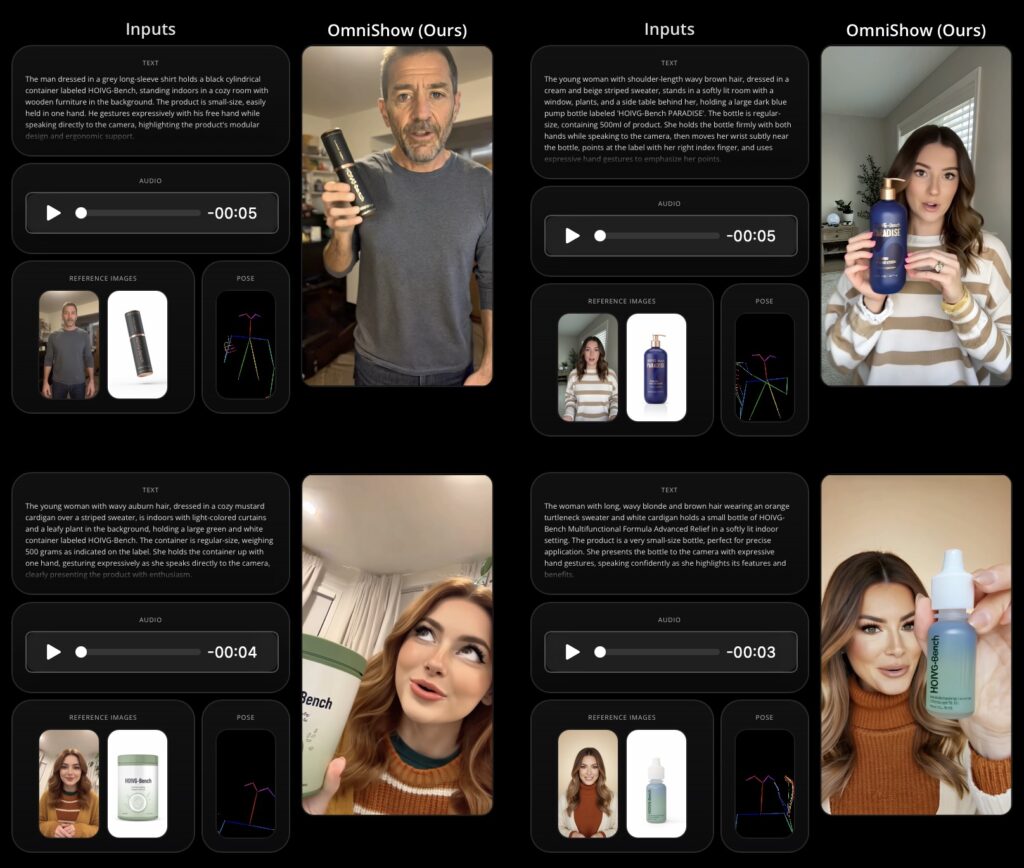
Through extensive experiments, OmniShow has demonstrated overall state-of-the-art performance across a variety of multimodal conditioning settings. By effectively achieving harmonious multimodal injection and maximizing heterogeneous data utility, ByteDance has set a solid standard for the emerging HOIVG task. As we look to the future, frameworks like OmniShow are poised to expand their capabilities by integrating with even larger datasets and richer inputs, ultimately broadening the horizon of what automated, AI-driven content creation can achieve across every digital medium.