By using reinforcement learning to enforce geometric constraints, this new framework bridges the gap between surface-level video generation and scalable, real-world simulation.
- The Core Problem: Today’s leading AI video models create stunning visuals but lack an intrinsic understanding of 3D geometry, leading to morphing objects and distorted physics during long scenes or large camera movements.
- The World-R1 Solution: Instead of rewriting a model’s underlying architecture, Microsoft’s World-R1 uses reinforcement learning (specifically Flow-GRPO) and a specialized text dataset to “teach” existing models structural coherence and spatial awareness.
- The Future Impact: By turning basic video generators into geometrically consistent simulators, this framework unlocks massive potential for autonomous driving, robotics, and immersive media, though training costs remain a significant hurdle.

Recent leaps in artificial intelligence have ignited a fundamental paradigm shift in visual media. We are no longer just looking at simple content creation; we are moving rapidly toward the ambitious goal of generating entire, interactive worlds. Pre-trained on vast oceans of internet-scale data, modern video generation models are increasingly viewed as the early precursors to general-purpose world models. These foundation models possess an almost magical ability to synthesize high-fidelity visual environments, holding transformative potential for industries ranging from autonomous driving and robotics to the next generation of immersive entertainment.
Beneath the stunning visual polish lies a critical structural flaw.
The Illusion of Reality: When the Geometry Glitches
Despite their impressive visual proficiency, current video foundation models fundamentally operate in image-space. They are incredible painters, but poor architects. Because they lack an intrinsic understanding of the 3D geometry that governs our physical reality, their illusions break down under stress.
While these models excel at generating short, static-camera clips, they quickly begin to struggle when tasked with synthesizing large camera movements or long-horizon driving scenes. Without explicit 3D constraints grounded in physics, the results are often riddled with geometric hallucinations and temporal inconsistencies. Objects might inexplicably morph into new shapes, vanish entirely from the frame, or distort in physically impossible ways. These errors reveal a stark truth: current models are merely mimicking surface-level, pixel-to-pixel correlations rather than actually simulating a coherent, structural world.

Historically, researchers have attempted to solve this by injecting 3D priors directly into the model via architectural modifications. Unfortunately, these structural changes often incur massive computational costs and severely limit the scalability of the technology.
World-R1: A Reinforcement Learning Revolution
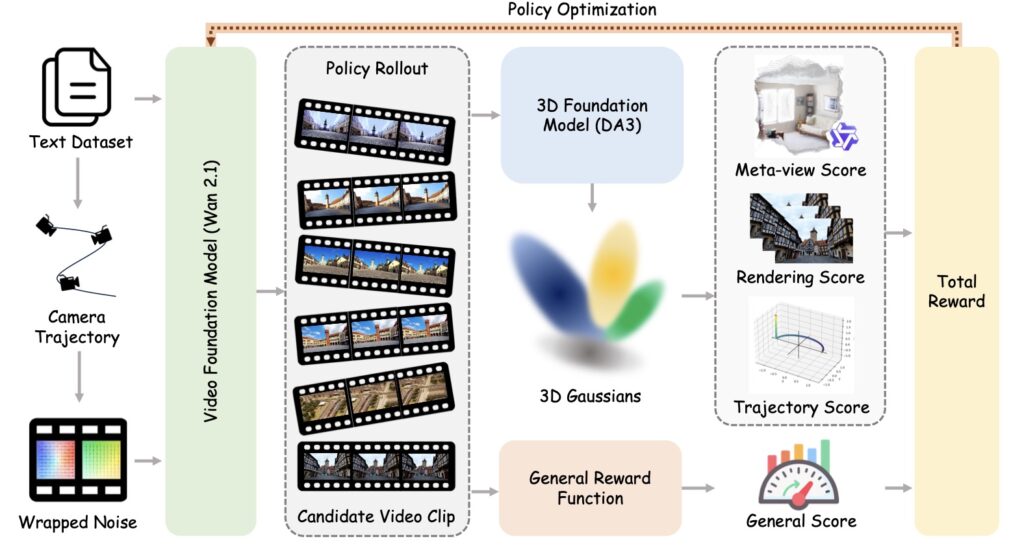
To solve this spatial crisis, Microsoft has introduced World-R1, a scalable framework designed to endow video generation models with robust world-modeling capabilities. Rather than ripping out a model’s foundation to build a new architecture, World-R1 reformulates the alignment of video generation and 3D geometry as a reinforcement learning (RL) problem.

By taking this approach, the framework successfully elicits latent spatial awareness from pre-trained models without requiring expensive supervised datasets or clunky architectural add-ons.
To make this alignment work, the researchers introduced a specialized, pure text dataset tailored specifically for world simulation. The heavy lifting is done by an optimization technique called Flow-GRPO. Through this algorithm, the model is fine-tuned using feedback from pre-trained 3D foundation models and vision-language models. This composite reward system—grounded in multi-view consistency and semantic coherence—enforces structural validity while preserving the original, high-quality visual fidelity of the base foundation model.
Balancing the Rigid and the Fluid
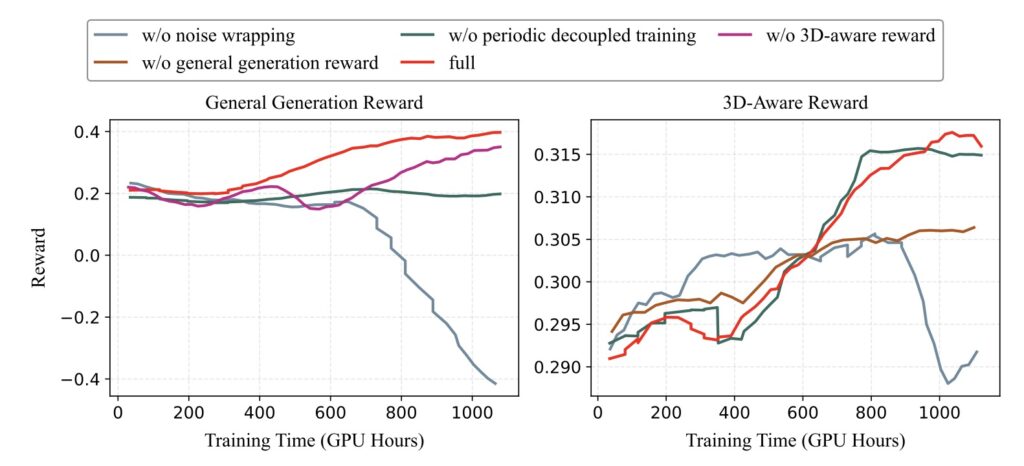
Real life is a mix of rigid geometry (like buildings and roads) and dynamic fluidity (like moving water, swaying trees, and walking pedestrians). To capture this complexity, World-R1 employs a periodic decoupled training strategy. This ensures that the enforcement of strict 3D consistency doesn’t accidentally freeze the dynamic nature of a scene. Coupled with proposed implicit camera conditioning, the framework enables precise trajectory control without compromising the generation of dynamic, non-rigid content.
Extensive quantitative and qualitative evaluations show that World-R1 effectively transforms basic video generators into geometrically consistent simulators.
While World-R1 represents a massive leap forward in scalable world modeling, the researchers acknowledge that the journey is far from over.

- The Computational Bottleneck: Applying reinforcement learning to video generation is incredibly resource-intensive. Unlike standard supervised fine-tuning, online RL requires repeated video rollouts and continuous reward evaluations. This makes the training process significantly more expensive. The development of more efficient rollout strategies, lower-cost evaluations, and stable video RL optimization will be critical next steps.
- The Ceiling of the Base Model: Because World-R1 is a post-training framework built on top of existing video models, it is inherently bound by their core generative capacities. In highly complex scenarios—such as dense multi-object compositions, intricate hand dynamics, fine-grained non-rigid motions, and extremely long-horizon scene evolutions—the system may still inherit artifacts from the original model.
As stronger, more advanced video foundation models are inevitably released, World-R1’s post-training framework is poised to directly absorb their improved scene understanding. For now, Microsoft has successfully laid down the physical laws for AI video generation, proving that the future of world simulation requires not just beautiful pixels, but true three-dimensional awareness.
