Breaking free from scale inconsistencies and rigid layouts to build immersive, user-controlled virtual environments.
- Breaking Boundaries: Map2World overcomes the traditional constraints of 3D scene generation—like rigid grid layouts and jarring scale inconsistencies—by allowing users to build expansive worlds using flexible, free-form segment maps.
- The Devil in the Details: A novel “detail enhancer network” adds fine-grained, intricate textures to the environment without breaking the overarching global structure, bridging the gap between broad world-building and micro-level realism.
- Smart Generalization: By leveraging the strong priors of existing 3D asset generators, Map2World requires less scene-specific training data, making it highly adaptable across diverse domains like gaming, VR, and autonomous vehicle simulations.
The demand for expansive, immersive, and realistic three-dimensional worlds has never been higher. From the sprawling landscapes of modern video games and the immersive realms of virtual reality to the highly rigorous simulation environments required to train autonomous vehicles, 3D world generation is a pivotal technology of the future. Yet, while artificial intelligence has made staggering leaps in generating individual 3D objects or small-scale assets, scaling that capability up to entire, cohesive worlds has remained a stubborn bottleneck. Building a digital universe is fundamentally harder than sculpting a digital coffee cup.

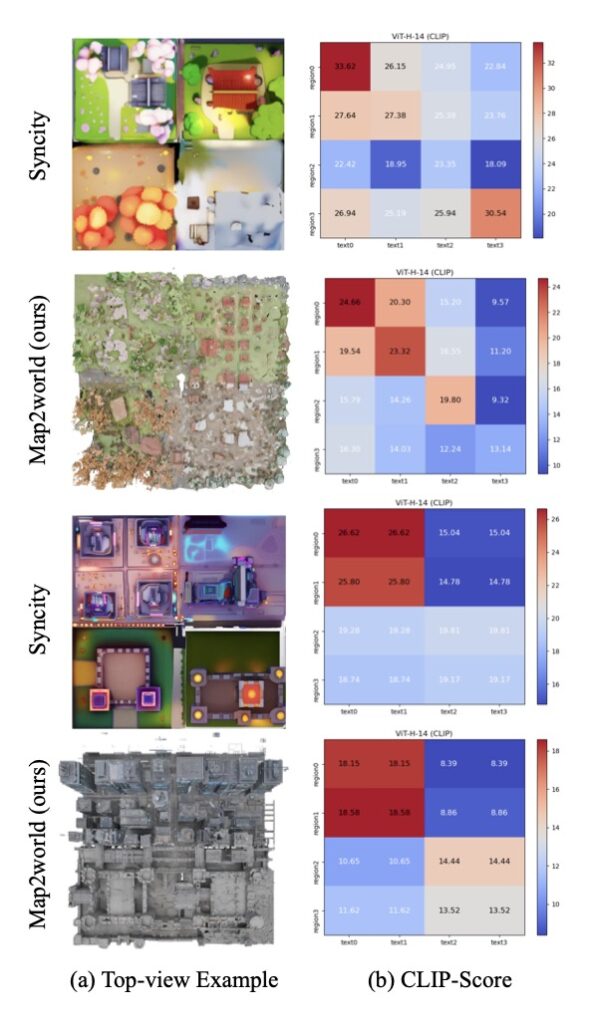
The primary hurdle has been data. While we have massive datasets of isolated objects, high-quality, world-level datasets are incredibly complex and labor-intensive to construct. Previous pioneers in the space—such as BlockFusion, NuiScene, LT3SD, WorldGrow, and SCube—attempted to train their own generators using what little dataset existed. Unfortunately, these methods found themselves trapped in limited, specific domains, capable of generating only indoor rooms or specific driving sequences, which severely limited their broader applicability.
To bypass this data drought, researchers often turned to pre-trained diffusion models. Some pipelines attempted to stitch 2D generated images into 3D using depth estimators, but these “Frankenstein” worlds suffered from view-dependent inconsistencies, often falling apart when viewed from a new angle. Others tried using video diffusion models to generate scene-like sequences, but the limited memory span of these models fundamentally crippled their ability to maintain true 3D consistency over time and space.
This is where a novel framework called Map2World steps in, fundamentally shifting the paradigm of how digital environments are constructed.
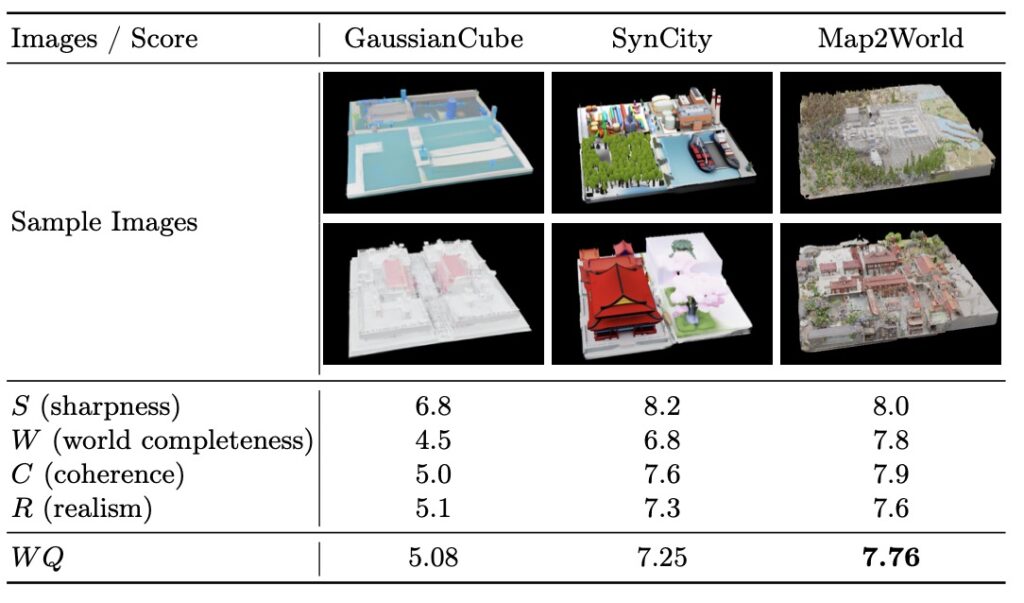
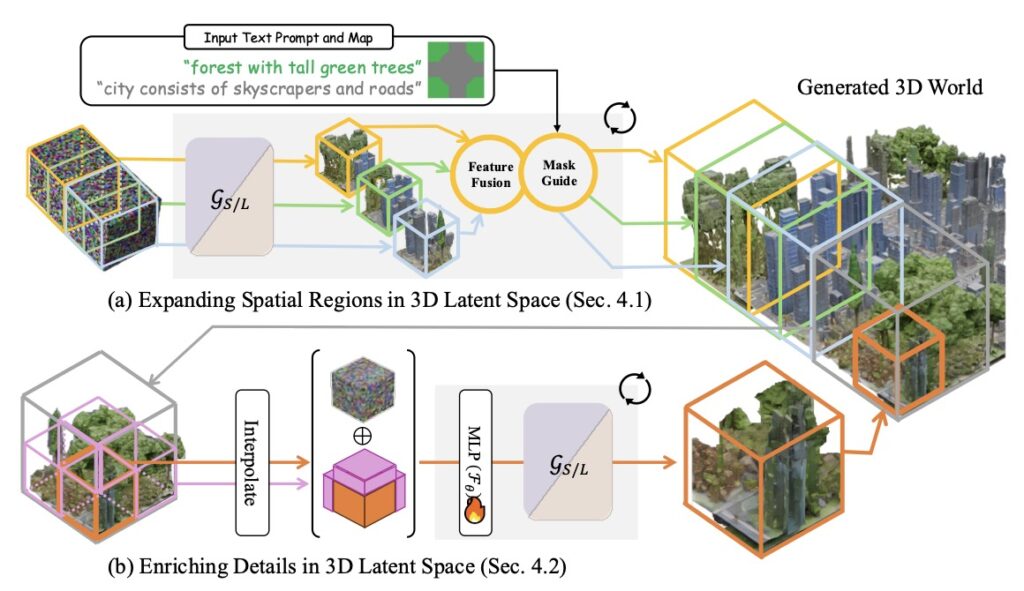
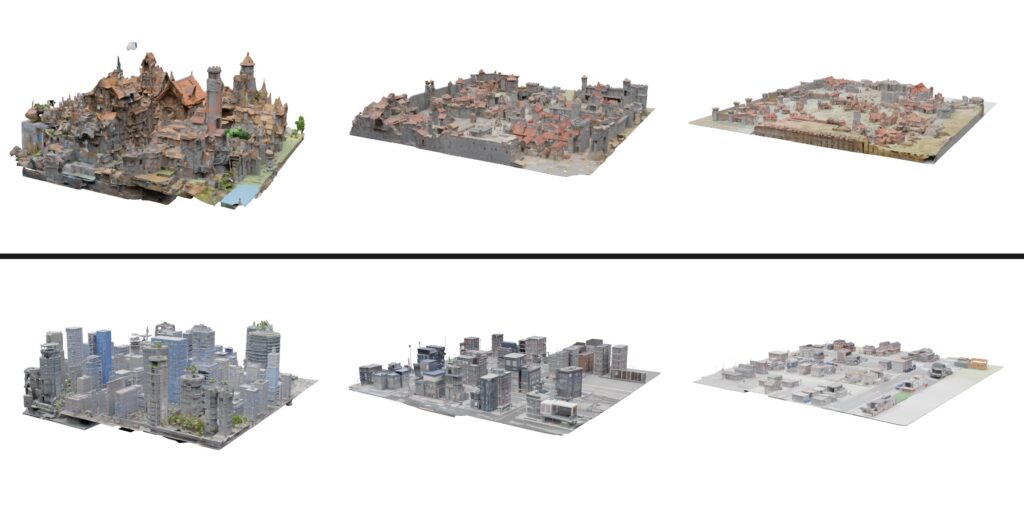
Instead of relying on rigid, pre-defined grids that often lead to awkward object scaling and disjointed environments, Map2World introduces a system conditioned on user-defined segment maps. This means creators can input arbitrary shapes and scales as a foundational blueprint. The AI then uses this segment map to generate the 3D world, ensuring global-scale consistency and absolute flexibility, no matter how expansive the environment becomes. Extensive testing has shown that this method drastically outperforms existing approaches, offering unprecedented user-controllability and structural coherence.
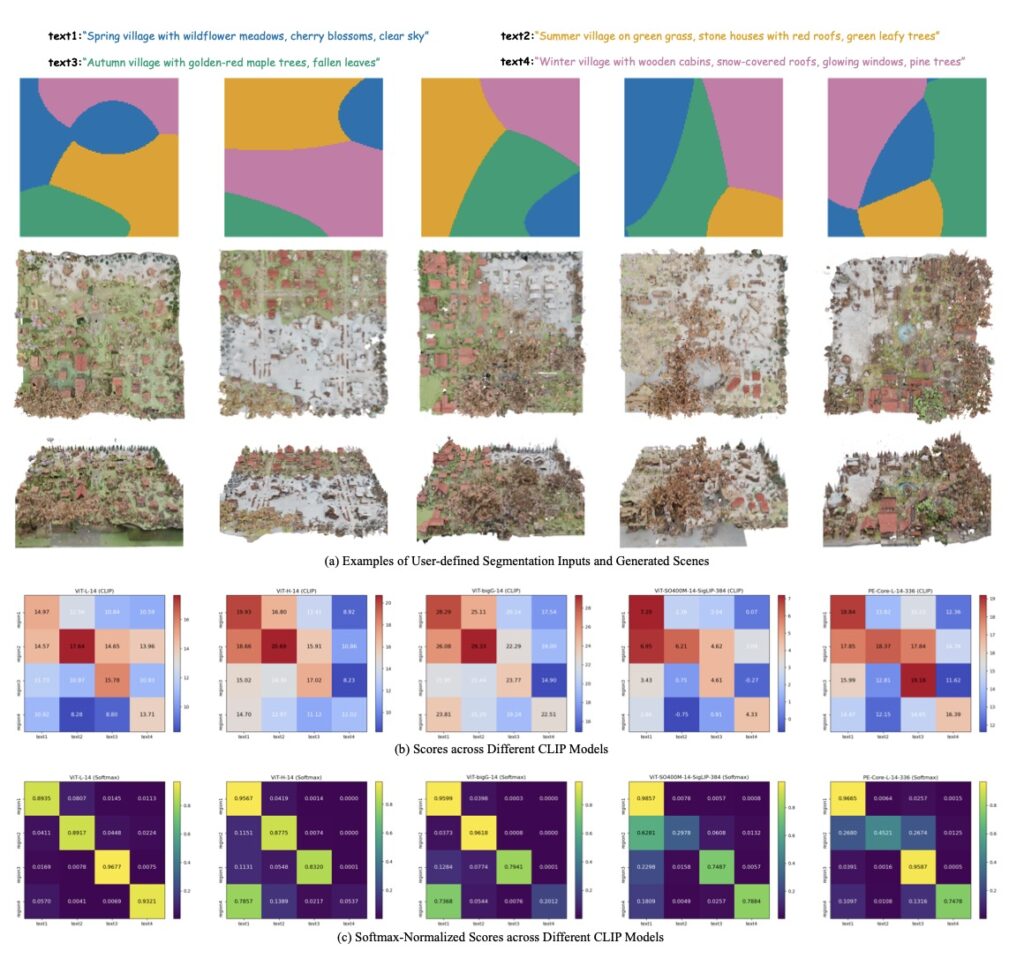
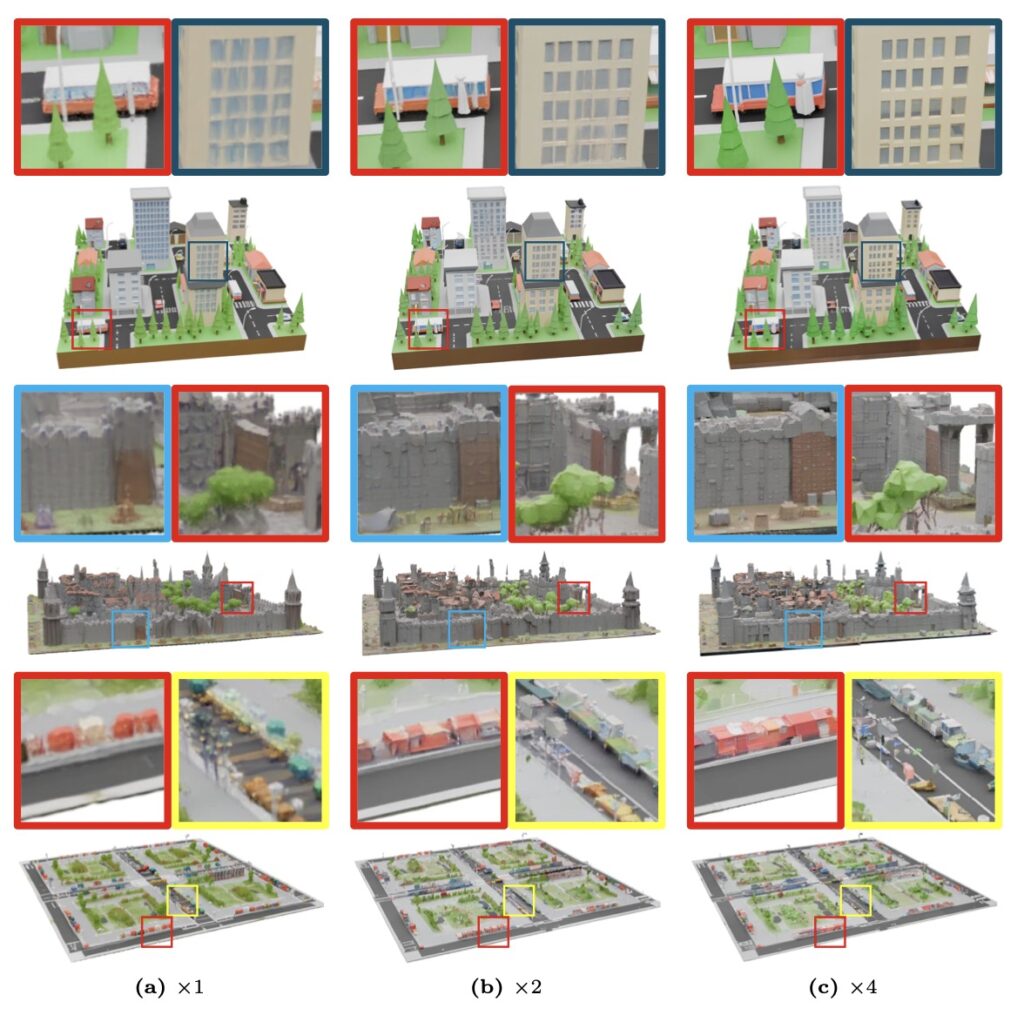
But a world is only as believable as its smallest details. To prevent these expansive scenes from looking flat or structurally generic, the framework introduces a specialized “detail enhancer network.” This enhancer operates with a deep understanding of the world’s global structure, allowing it to inject fine-grained details—like the texture of bark on a tree or the weathering on a building—without compromising the overall coherence of the scene. Furthermore, the entire pipeline is cleverly designed to piggyback on the “strong priors” (the pre-existing knowledge) of established 3D asset generators. This allows Map2World to achieve robust generalization across entirely different visual domains, even when it is starved of extensive scene-generation training data.

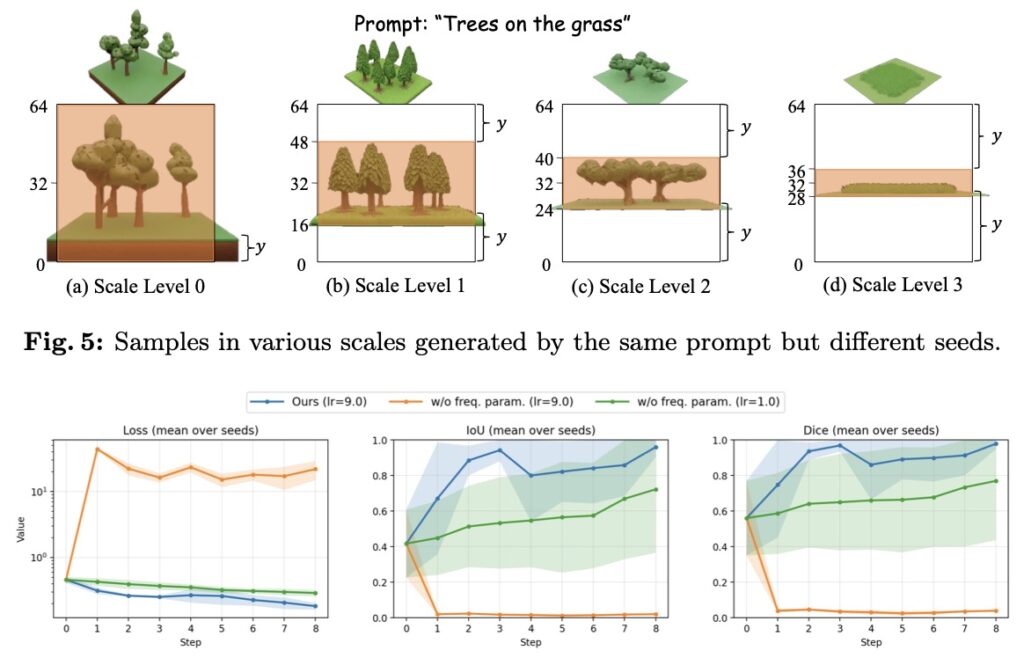
Like any pioneering technology, Map2World is a stepping stone with its own set of limitations to overcome. Because the model is built upon the TRELLIS architecture, it inherits its reliance on absolute position encoding. In practice, when the pipeline attempts to merge smaller structural “cubes” to build the world, the positional information can shift, occasionally altering the decoded 3D structure. However, researchers are already charting the path forward. This issue can be smoothed out by transitioning to baseline models that use relative positioning, or by refining training strategies to help the model adapt to changing encodings.
Looking to the future, the potential for growth is immense. Currently, the detail enhancer is fine-tuned primarily on scene-level cropped data and simple meshes from datasets like Objaverse. By feeding the network more complex, photo-realistic textures and training it concurrently on both object-level and world-level data, the visual fidelity of these generated worlds will skyrocket.
The creators of Map2World emphasize that this is an industrial and creative tool. Because it does not model personal identity or utilize personal data, it carries very low risk for significant adverse social impacts. As we stand on the brink of a new era in content generation and simulation, Map2World offers a vital, flexible blueprint for building the virtual realities of tomorrow—responsibly, cohesively, and on a truly global scale.