Inside the split relay and transceiver architecture that makes ChatGPT’s voice interactions feel perfectly human.
- The Kubernetes Conundrum: To support 900 million weekly users, OpenAI moved away from the traditional, port-heavy WebRTC deployment, which clashed with Kubernetes’ autoscaling and security models.
- The Split Architecture Solution: By adopting a “relay plus transceiver” model, OpenAI successfully decoupled lightweight packet routing from stateful media protocol termination, preserving native WebRTC behaviors for the client.
- Intelligent Global Routing: Utilizing clever first-packet routing via ICE
ufragmetadata and a globally distributed relay network, the system dramatically cuts connection times and guarantees the crisp, real-time turn-taking essential for voice AI.
Voice AI only feels natural when the conversation moves at the speed of human speech. When network latency gets in the way, the illusion shatters. Users instantly notice the awkward pauses, clipped interruptions, and delayed barge-ins. Whether it is a user conversing with ChatGPT, a developer utilizing the Realtime API, or an autonomous agent navigating an interactive workflow, low latency is non-negotiable. The AI model must process audio while the user is still speaking.
Operating at OpenAI’s massive scale—serving over 900 million weekly active users—translates this low-latency goal into three strict infrastructural requirements. First, the system must have a robust global reach. Second, connection setups must be lightning-fast so users can speak the moment a session initiates. Finally, media round-trip times must remain stable, with minimal jitter and packet loss, to ensure turn-taking feels crisp and conversational. To meet these demands, OpenAI’s engineering team recently executed a complete rearchitecture of their WebRTC stack, resolving major friction points between traditional media streaming and modern cloud infrastructure.
The WebRTC Foundation
WebRTC is the undisputed open standard for transmitting low-latency audio, video, and data across browsers, mobile apps, and servers. While traditionally associated with peer-to-peer video calling, it provides an exceptionally practical foundation for client-to-server real-time AI systems. It elegantly standardizes the notoriously difficult aspects of interactive media: Interactive Connectivity Establishment (ICE) for traversing Network Address Translators (NATs), secure transport via DTLS and SRTP, complex codec negotiation, and vital client-side features like echo cancellation and jitter buffering.
For AI products, standardization is a massive advantage. Without WebRTC, engineers would have to invent bespoke solutions for encryption, connectivity, and network adaptation for every client type. By leveraging WebRTC, OpenAI builds upon a battle-tested protocol ecosystem. In fact, foundational WebRTC pioneers Justin Uberti and Sean DuBois (creator of Pion) are part of the OpenAI team, helping to bridge the gap between low-level transport infrastructure and advanced AI models.
The most critical property WebRTC provides for AI is the continuous audio stream. Instead of waiting for a user to finish speaking and upload a complete file (a “push-to-talk” dynamic), a conversational agent can begin transcribing, reasoning, and generating speech simultaneously.
Choosing the Right Media Architecture
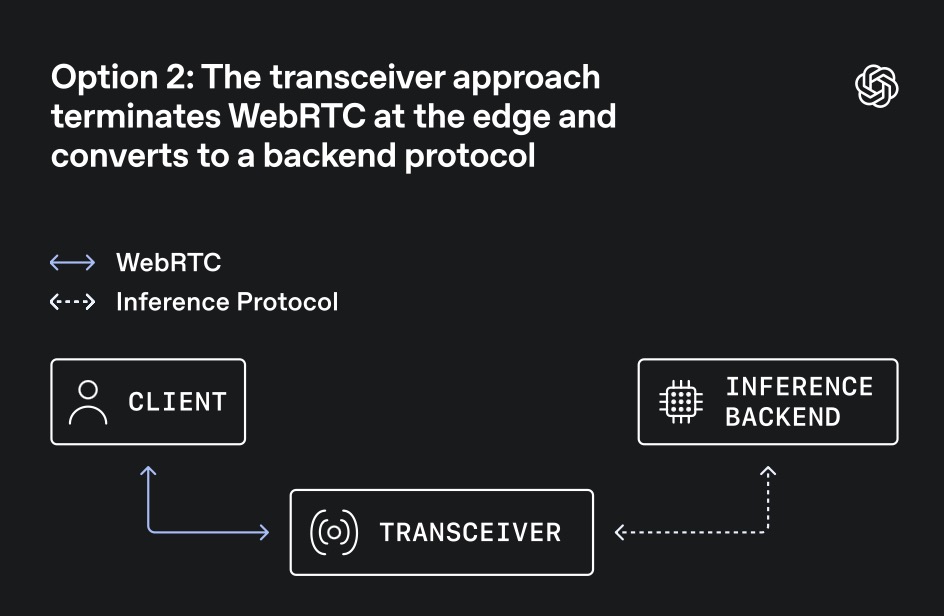
Integrating WebRTC into an AI backend forces a pivotal architectural decision: where to terminate the WebRTC connection.
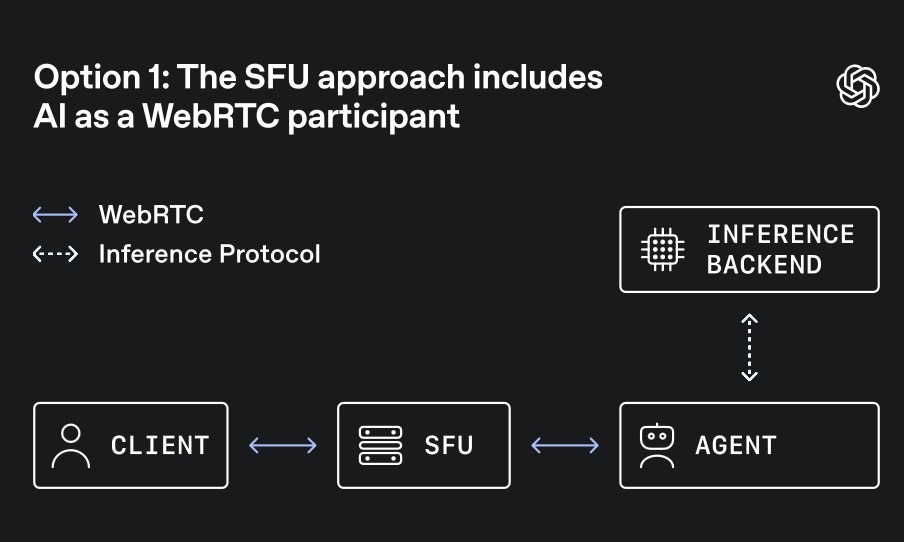
Traditionally, platforms use a Selective Forwarding Unit (SFU)—a media server designed to receive streams from multiple participants and forward them accordingly. SFUs are perfect for collaborative meetings or group classrooms where the AI acts as just another participant. However, AI traffic is predominantly 1:1; it is a single user talking to a single model, where latency on every turn is hyper-sensitive.
Because of this unique traffic shape, OpenAI opted for a transceiver model. In this setup, an edge service terminates the client’s WebRTC connection, owning the session state, handshakes, and encryption keys. It then converts the media and events into simpler internal protocols for backend inference, transcription, and speech generation. This centralized session ownership allows backend AI services to scale efficiently like standard APIs, rather than forcing them to act as complex WebRTC peers.
The Kubernetes Clash: Port Exhaustion and State Stickiness
The initial implementation of this transceiver model was a single Go-based service handling both signaling and media termination. However, deploying this on Kubernetes at scale revealed severe operational bottlenecks.
The fundamental issue was the conventional “one-port-per-session” WebRTC model. Kubernetes and modern cloud load balancers are simply not designed to manage tens of thousands of exposed, public UDP ports per service. This port exhaustion introduces massive operational complexity regarding firewall policies, load balancing, and rollout safety. Furthermore, dynamically adding or removing pods during autoscaling becomes incredibly brittle when each pod must reserve massive stable port ranges.
Moving to a single-port-per-server design solves the port count issue but introduces a new enemy: state stickiness. Protocols like ICE and DTLS are highly stateful. If packets for an established session accidentally route to a different server process, the setup fails and the media breaks. OpenAI needed a way to expose a tiny, fixed UDP surface to the internet while flawlessly routing every single packet to the specific transceiver that owned the corresponding session.
Split Relay Plus Transceiver
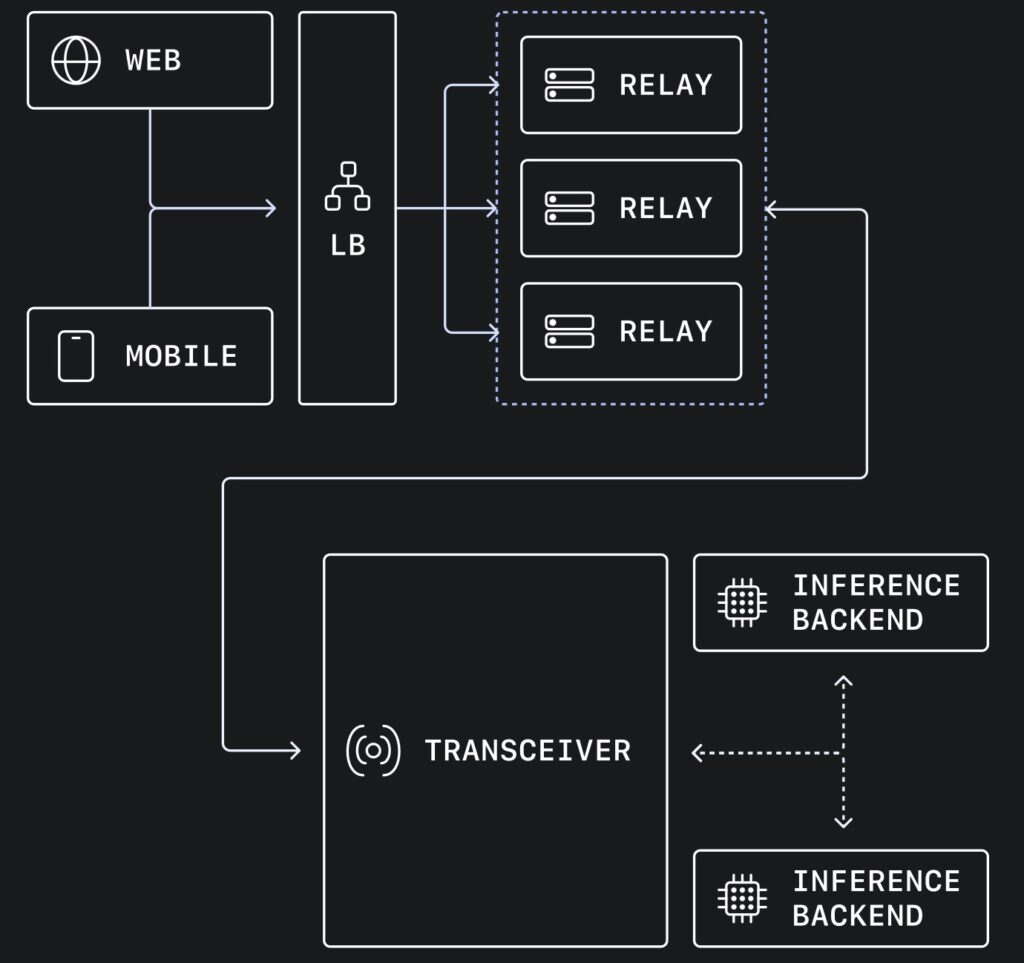
To conquer this, OpenAI deployed a brilliant split architecture that separates packet routing from protocol termination.
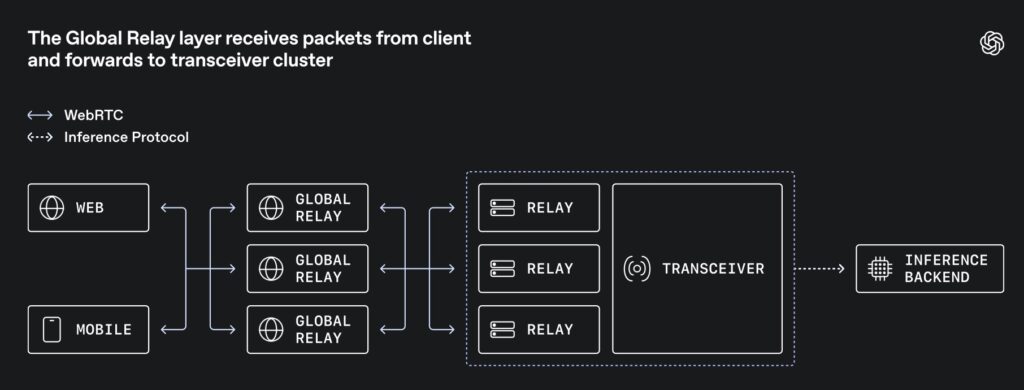
The architecture introduces a lightweight “Global Relay” layer. When media traffic enters the network, it hits the relay first. The relay does not decrypt media, negotiate codecs, or run complex state machines. It simply reads enough packet metadata to determine the destination and forwards it to the correct stateful transceiver. From the user’s perspective, they are still speaking standard WebRTC; the complexity is entirely hidden inside OpenAI’s infrastructure.
The Magic of First-Packet Routing
The genius of this system lies in how the relay knows where to send the very first packet. Instead of pausing traffic to query an external database (which adds latency), the team utilized a protocol-native hook: the ICE username fragment (ufrag).
During the initial signaling setup, the transceiver encodes routing metadata directly into the server-side ufrag. When the client sends its very first media-path packet (a STUN binding request), the relay simply parses the ufrag, decodes the routing hint, and instantly forwards the packet to the correct internal transceiver cluster. Once this path is established, an ephemeral, in-memory session is created to quickly route subsequent DTLS and RTP packets. A Redis cache backs this up for rapid flow recovery in case a relay restarts.
Global Reach and Bare-Metal Performance
By reducing the massive UDP port requirement down to a few stable addresses, OpenAI was able to deploy this relay pattern globally.
Using Cloudflare geo-steering, initial connections are directed to the nearest regional cluster. This dramatically shortens the first network hop, pulling the user’s traffic off the unpredictable public internet and onto OpenAI’s optimized backbone as quickly as possible. This directly reduces the wait time before an AI can start speaking.
Remarkably, the relay service achieves incredible performance without resorting to complex kernel-bypass frameworks. Written in Go, it leverages native Linux features like SO_REUSEPORT to distribute packets across multiple workers sharing the same port. By pinning Go routines to specific OS threads, the system maintains high cache locality and minimizes context switching. Combined with zero-copy parsing, the relay pushes massive volumes of global media traffic with a minimal infrastructural footprint.
Invisible Infrastructure
OpenAI’s WebRTC rearchitecture proves that when scaling real-time AI, the best place to handle complexity is in a thin, intelligent routing layer at the edge, rather than overburdening backend services or forcing custom client behaviors. By cleverly encoding routing data into native WebRTC metadata and splitting the architecture, they solved Kubernetes port exhaustion without breaking standard browser interoperability.
Ultimately, real-time voice AI is only successful when the underlying infrastructure makes latency feel completely invisible. Through this elegant engineering, OpenAI has ensured that when millions of users speak to ChatGPT, the AI is ready to listen—and reply—without missing a beat.