From processing text to perceiving the world: A deep dive into the architecture, breakthroughs, and open challenges of native foundation models.
- A Shift to Native Perception: GLM-5V-Turbo moves AI beyond text-only interactions by natively integrating multimodal perception—such as images, videos, webpages, and GUIs—directly into its core reasoning, planning, and tool use.
- Under-the-Hood Innovations: Driven by the new CogViT vision encoder and large-scale joint reinforcement learning across 30+ task categories, the model achieves top-tier performance in visual tool use and multimodal coding without sacrificing text capabilities.
- The Next Frontier: Unlocking the true potential of AI agents requires solving complex open challenges, namely allowing models to discover their own strategies, developing true visual memory for long-horizon tasks, and mastering the symbiosis between the AI model and its system harness.
The landscape of artificial intelligence is undergoing a profound transformation. We are witnessing a rapid shift from models that simply understand language to agents capable of real-world interaction. This evolution opens up massive opportunities for productivity gains across knowledge work, software engineering, and complex tasks requiring graphical user interface (GUI) navigation. However, for a general-purpose AI agent to truly succeed, it needs more than just advanced textual intelligence. It must be able to natively process a messy, heterogeneous world of images, videos, documents, and web pages, fusing them into a unified stream of perception and decision-making.
Enter GLM-5V-Turbo, a significant leap toward creating native foundation models for multimodal agents. Rather than treating vision as an auxiliary add-on to a language model, GLM-5V-Turbo embeds multimodal perception directly into the core of the AI’s reasoning, planning, and execution processes.
The Engine Under the Hood: Building a Native Multimodal Mind
To achieve this level of native integration, GLM-5V-Turbo relies on a suite of coordinated advancements spanning model design, training, and infrastructure.
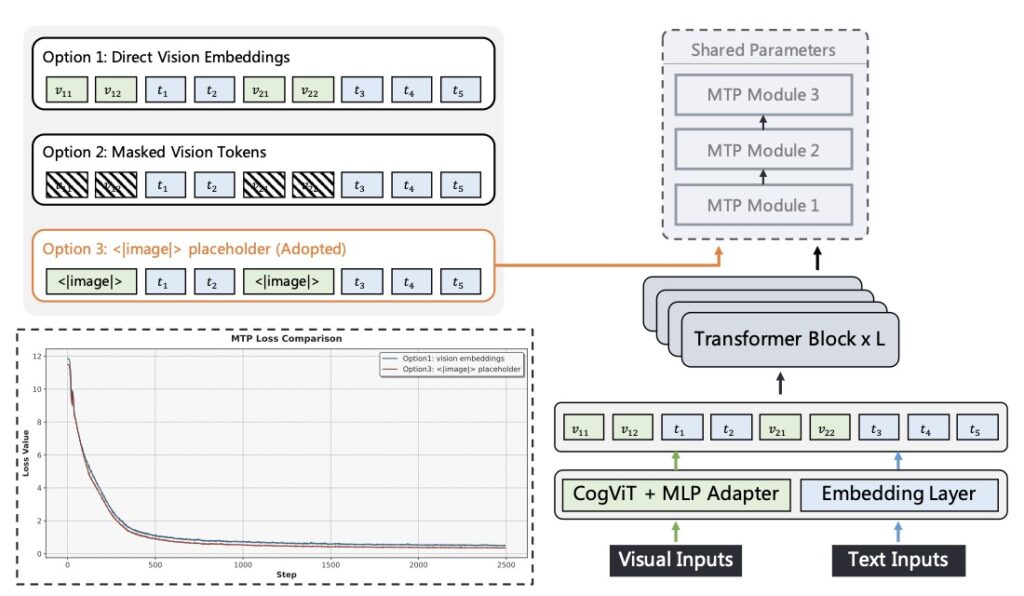
At the architectural level, the development team introduced CogViT, a novel vision encoder specifically tailored for fine-grained multimodal understanding. This is paired with Multimodal Multi-Token Prediction, an innovation that supports both text-only and complex multimodal inputs while remaining highly efficient for large-scale infrastructure.
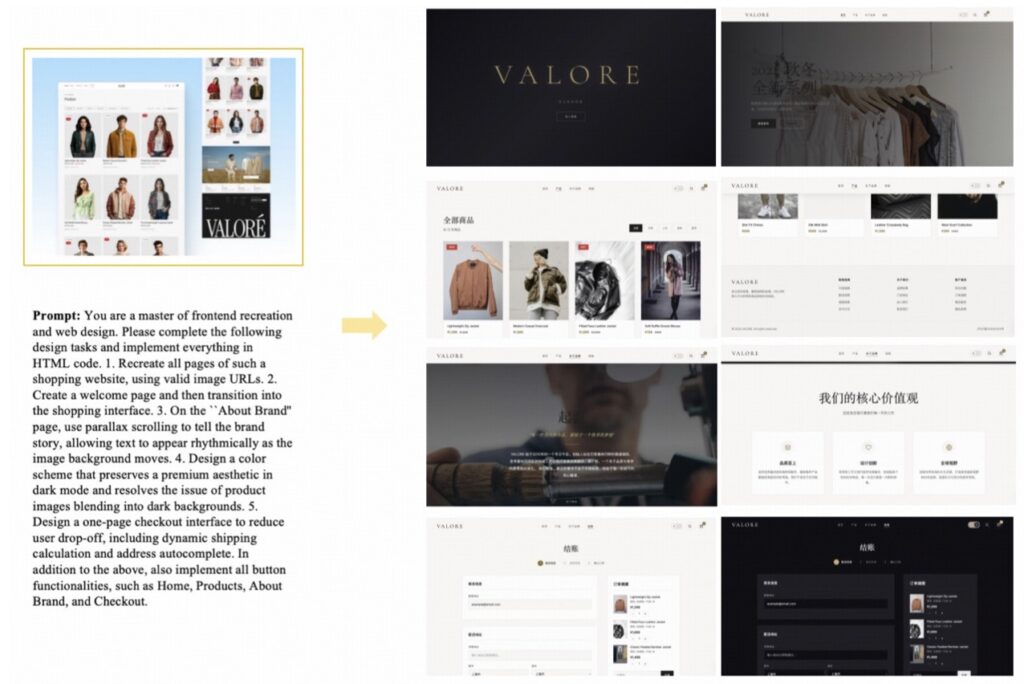
But architecture is only half the battle; the training pipeline is equally critical. Vision and language are deeply interwoven throughout the model’s pre-training and supervised fine-tuning phases. GLM-5V-Turbo was further refined using joint reinforcement learning (RL) across more than 30 distinct task categories. By optimizing infrastructure for large-scale multimodal RL, the model masters a wide spectrum of perception, reasoning, and agentic capabilities.
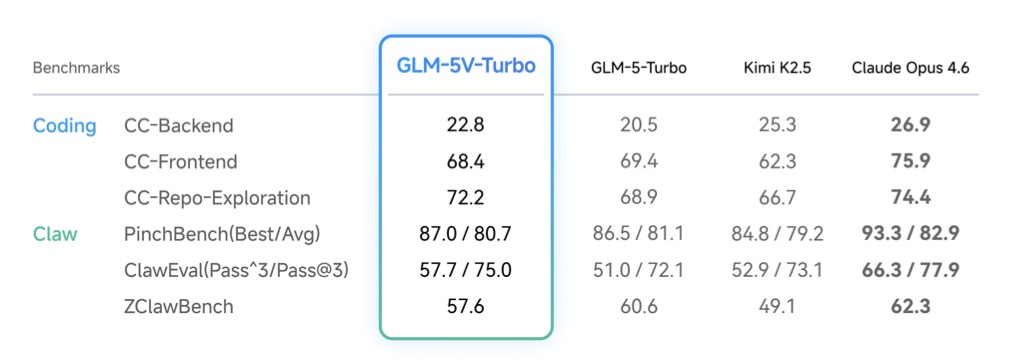
The result is a highly capable foundation model that seamlessly handles multimodal coding and visual tool use, all while preserving its highly competitive text-only coding skills. To push the boundaries of testing, the developers also introduced ImageMining, a vision-centric deep search benchmark designed to rigorously evaluate a model’s ability to “think and deep search” using image-based context.

Three Open Challenges for Future Agents
Despite the impressive milestones achieved by GLM-5V-Turbo, the journey toward autonomous, long-horizon multimodal agents is far from over. The most difficult open problems no longer lie in isolated capability improvements, but rather in the complex dynamics of strategy emergence, memory management, and system design.
1. Enabling the Emergence of Agentic Strategies Currently, training AI agents relies heavily on human-crafted or heavily filtered “cold-start” trajectories. While this successfully initializes the model, it restricts the AI to familiar patterns, preventing it from discovering genuinely novel or superior ways to solve problems. It becomes exceptionally good at walking the paths we show it, but struggles to forge its own. Experiments show that injecting diverse trajectories during the cold-start phase helps the model uncover improved variants through RL. Ultimately, the goal is to build models that can independently discover better reasoning strategies and organic organizational structures—such as sub-agent decomposition or multi-agent collaboration—rather than being confined to variations of human logic.
2. Mastering Multimodal Context Management As agents tackle longer, more complex tasks, context management becomes a severe bottleneck. Visual data, especially video, consumes a system’s “context budget” far more aggressively than text. Currently, many systems compromise by dropping older visual observations as the context window fills up. In text-only settings (like Claude Code), older histories can be easily compressed or summarized. But faithful compression of visual data is incredibly difficult. You aren’t just summarizing semantic meaning; you have to preserve visual details like layout, spatial relationships, and temporal changes that might suddenly become crucial later in a task. Current memory mechanisms are fundamentally text-centric, highlighting an urgent need for a native, multimodal approach to memory.
3. The Co-Evolution of Model and Harness An AI model does not operate in a vacuum. Its effective capability is jointly shaped by the core model itself and the “harness” surrounding it—the task decomposition frameworks, tool-use policies, memory loops, and verification systems. This relationship is deeply symbiotic. The same AI can behave entirely differently under different harness designs. What might look like a limitation in the model could actually be a flaw in the harness. Conversely, a specific harness design might be useless until the underlying model crosses a specific threshold of intelligence, at which point it becomes critical. Moving forward, AI development cannot be viewed as just training a better brain; it must be an integrated effort to co-evolve the mind and the tools it uses to interact with the world.
GLM-5V-Turbo proves that the future of AI is undeniably multimodal. By bringing perception into the core of AI reasoning, we are stepping closer to agents that don’t just chat with us, but can actually see, navigate, and shape the digital world alongside us.