How Simple Self-Distillation (SSD) allows large language models to dramatically improve their coding skills using nothing but their own raw outputs.
- Self-Taught Mastery: Large language models can significantly boost their own code-generation capabilities without external teachers, verifiers, or complex reinforcement learning simply by training on their own raw outputs.
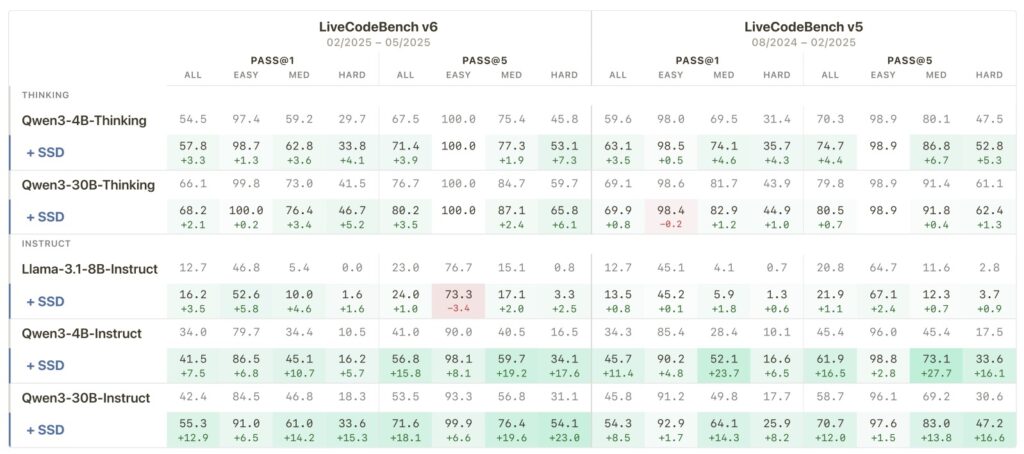
- Massive Performance Leaps: Using Simple Self-Distillation (SSD), models like Qwen3-30B-Instruct jump from a 42.4% to a 55.3% success rate on rigorous coding benchmarks, with the biggest improvements targeting the most difficult problems.
- The Secret is in the Distribution: SSD succeeds not because the generated code is perfectly correct, but because it intelligently reshapes how the AI predicts tokens—balancing the strict need for syntax precision with the creative freedom needed for complex problem-solving.
In the rapidly accelerating world of artificial intelligence, training a large language model (LLM) to write highly complex code usually requires an arsenal of external tools. Developers rely on strict verifiers, superior “teacher” models, or resource-heavy reinforcement learning pipelines to guide the AI toward the right answers. But what if an AI could pull itself up by its own bootstraps? What if it could improve simply by learning from its own unfiltered, raw attempts?
Recent research from Apple answers this with a resounding affirmative, introducing a technique so straightforward they call it “Embarrassingly Simple Self-Distillation” (SSD). By merely sampling solutions from a model using specific temperature and truncation settings, and then applying standard supervised fine-tuning to those very samples, LLMs are achieving staggering leaps in coding proficiency.
The Precision-Exploration Conflict
To understand why SSD is such a breakthrough, we have to look at how LLMs write code. When generating text or code, models constantly face a “precision-exploration conflict.” Writing code is an incredibly delicate balancing act. In some moments, the model needs absolute precision—a misplaced bracket or incorrect variable name will instantly break the program. In other moments, the model needs to explore—brainstorming novel logic, looping structures, or creative algorithms to solve a complex problem.
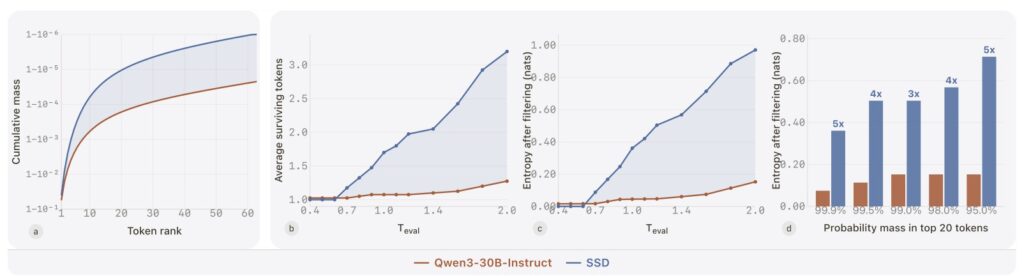
Apple’s research traces the success of SSD directly to its ability to resolve this conflict. The method fundamentally reshapes token distributions in a highly context-dependent way. When precision is paramount, SSD suppresses the “distractor tails”—the low-probability, incorrect guesses that often lead a model to hallucinate bad syntax. Conversely, when exploration is needed, SSD preserves useful diversity, allowing the model to think outside the box.
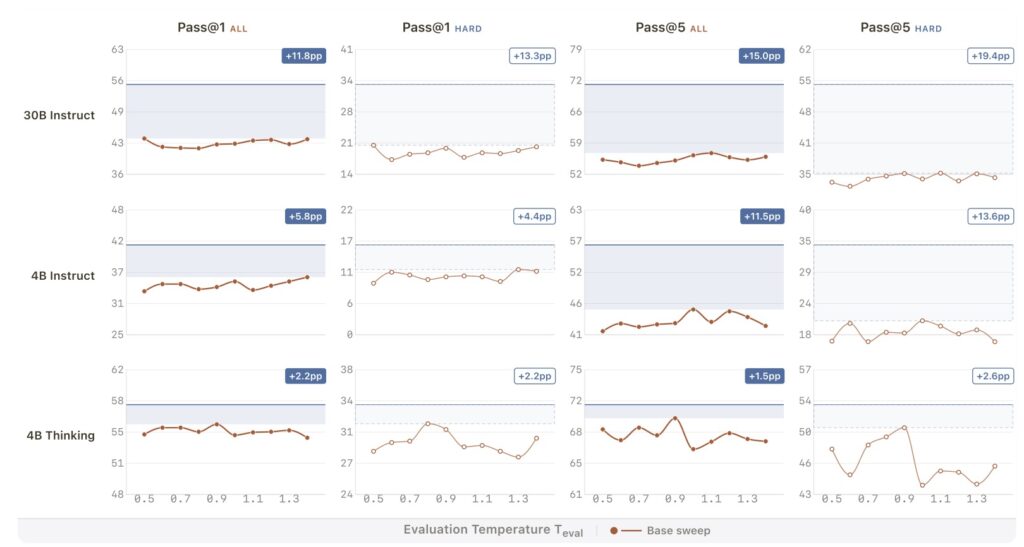
The results speak for themselves. When applied to the Qwen3-30B-Instruct model, SSD pushed its pass@1 rate on the challenging LiveCodeBench v6 from 42.4% up to an impressive 55.3%. Notably, these gains were heavily concentrated on the hardest problems. Furthermore, this isn’t a one-off anomaly; the technique generalizes beautifully across different architectures, including Llama and Qwen models at the 4B, 8B, and 30B scales, working for both standard instruct models and newer “thinking” variants.
The Importance of Boundaries: Finding the “Goldilocks Zone”
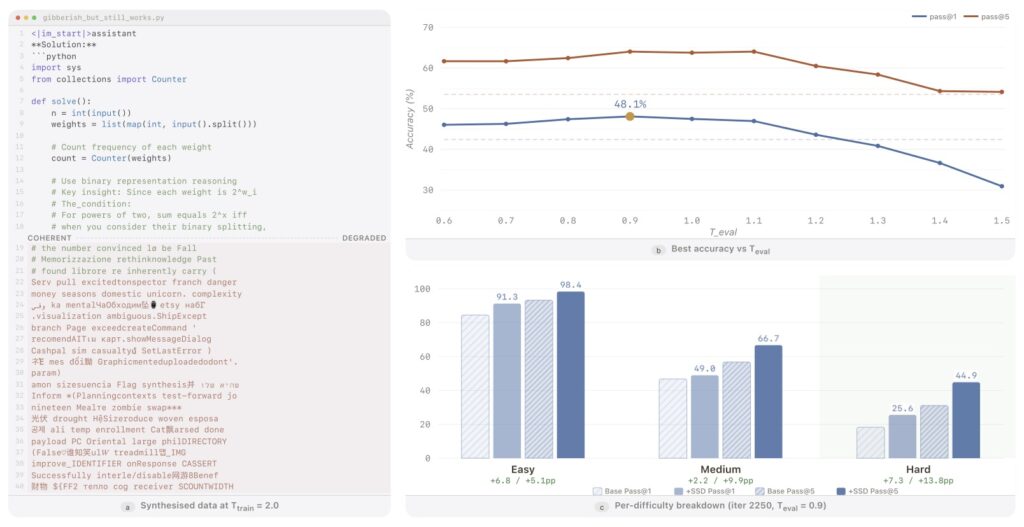
While the method is simple, it is not without its rules. The researchers discovered that the “viable region” for SSD to succeed is sharply bounded, particularly when it comes to the temperature settings used during evaluation (Teval).
Temperature in AI dictates how creative or predictable a model’s outputs are. The research grid shows that performance remains highly competitive when the evaluation-time temperature is kept roughly in the range of [0.6, 1.1]. However, this success is fragile if pushed too far. Once the temperature creeps too high, the AI’s performance degrades rapidly—falling below the original baseline at a Teval of 1.3, and plummeting even further at 1.5.
This behavior perfectly aligns with what the researchers call the “temperature-composition picture.” If a model is trained in a regime that approximates high-temperature reshaping without proper constraints, it will only succeed during evaluation if the temperature remains inside that carefully defined viable band.
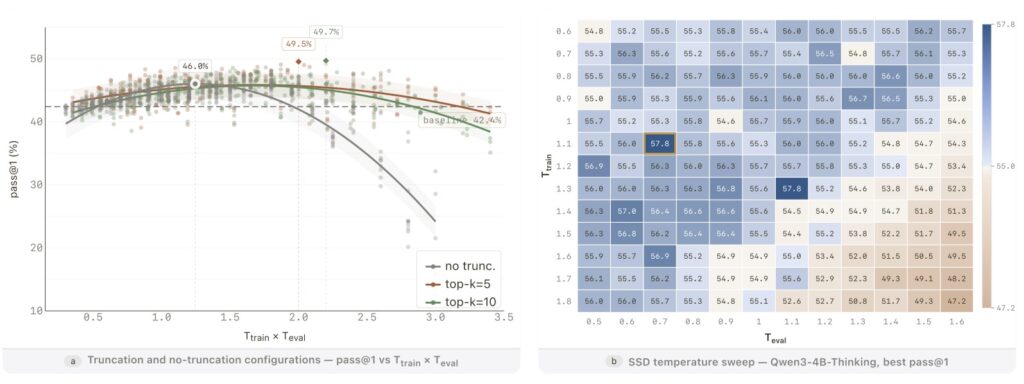
The Truncation Recipe and Why Distribution Matters
The true magic of SSD is best understood when comparing standard training recipes against stress tests. In the standard, highly successful SSD recipe, “truncation” is heavily utilized during the training phase. This active truncation creates what is known as “support compression,” meaning it actively and permanently suppresses those pesky distractor tails (bad coding habits) in the student model right from the start.
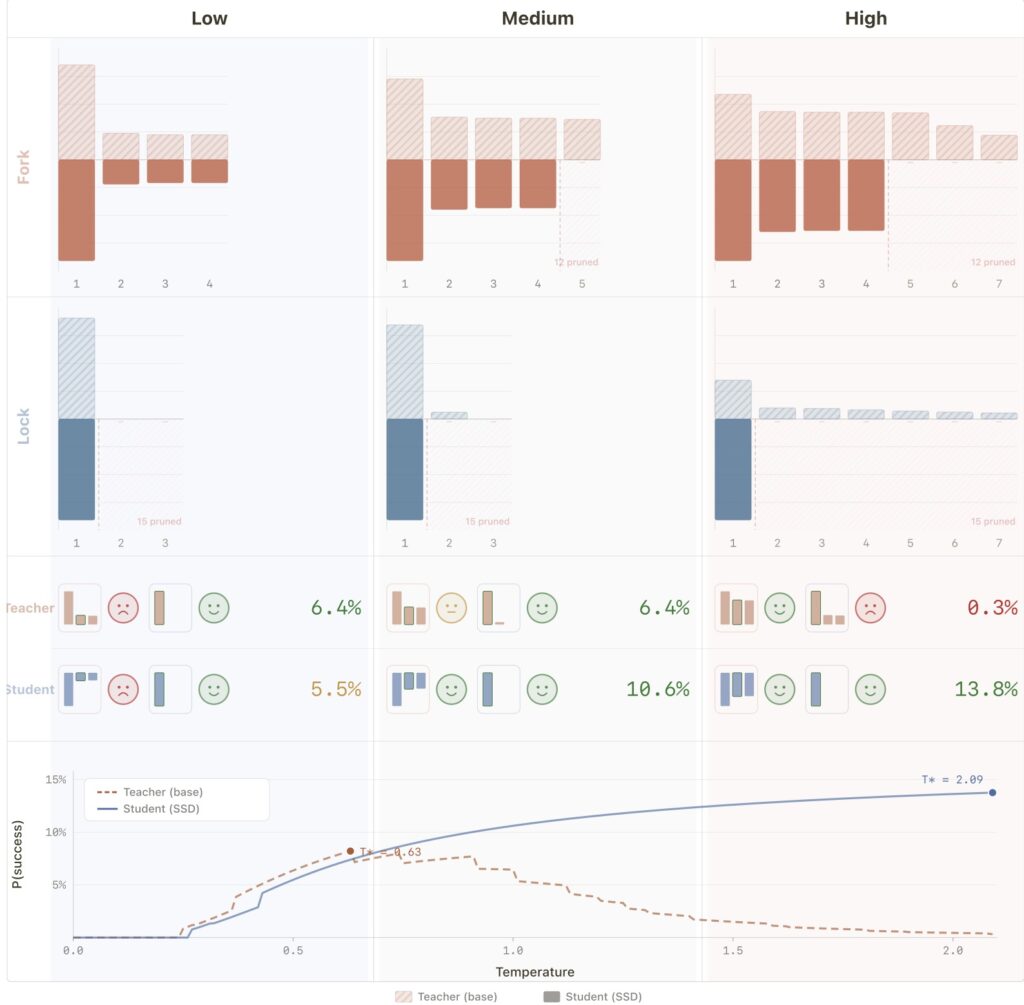
When researchers ran a stress test without this training-time truncation, the results were noticeably weaker. Without support compression during training, those distractor tails survive the learning process. The model is then forced to clean up the mess at evaluation time using top-k or top-p truncation to filter out bad outputs. While the AI still sees real gains in this stress test scenario, those gains are smaller and much more fragile.
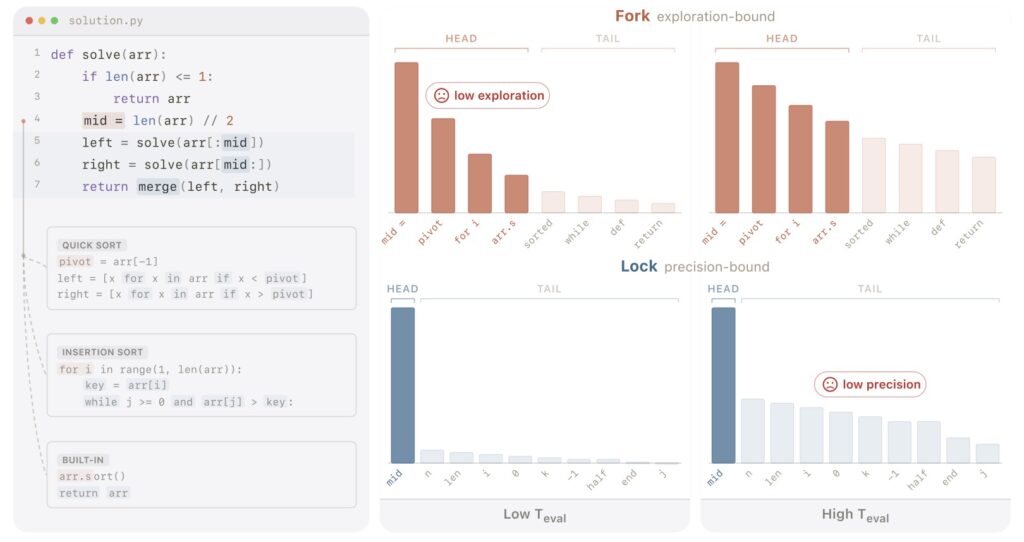
Yet, this exact fragility leads to perhaps the most profound conclusion of the entire study: even when the raw sampled programs the model learns from are mostly poor, SSD still helps. It turns out that the model isn’t just memorizing correct code. The useful learning signal lies in the distributional reshaping itself, rather than in the raw correctness of the programs. By subtly adjusting the mathematical probabilities of which token should come next, Simple Self-Distillation proves to be an incredibly powerful, complementary post-training direction—proving that sometimes, the best way to teach an AI is just to let it learn from itself.