By eliminating memory overhead and compressing key-value caches to just 3 bits, this new suite of algorithms makes massive AI models and vector search faster and leaner than ever.
- Massive Compression with Zero Accuracy Loss: TurboQuant drastically reduces AI model size, shrinking key-value memory by over 6x (down to 3 bits) without sacrificing performance on complex, long-context tasks.
- Eliminating Hidden Overhead: By leveraging two novel algorithms—PolarQuant and QJL—the system bypasses the memory costs of traditional quantization using polar coordinates and a brilliant 1-bit mathematical error-checker.
- Unlocking High-Speed Search at Scale: Delivering up to an 8x speedup on H100 GPUs, these theoretically proven methods pave the way for faster, more efficient large language models and global-scale semantic search engines.
Vectors are the fundamental language of artificial intelligence. They are how AI models understand and process the world. While small vectors might describe simple data points, “high-dimensional” vectors capture highly complex information, from the intricate features of an image to the nuanced meaning of a word. However, this power comes at a steep price: high-dimensional vectors consume enormous amounts of memory. This appetite for data frequently leads to bottlenecks in the key-value (KV) cache—the high-speed “digital cheat sheet” AI uses to instantly retrieve frequently used information without scanning a slow, massive database.
Traditionally, engineers have relied on vector quantization to solve this problem. As a classic data compression technique, quantization reduces the size of high-dimensional vectors to enhance high-speed vector search and unclog KV cache bottlenecks. The catch? Traditional quantization usually introduces its own “memory overhead.” Most methods require the system to calculate and store full-precision quantization constants for every tiny block of data. This overhead can easily add 1 or 2 extra bits per number, frustratingly defeating the purpose of compressing the data in the first place.
Enter TurboQuant (slated for presentation at ICLR 2026), a revolutionary compression algorithm that optimally solves this memory overhead challenge. TurboQuant doesn’t work alone; it achieves its extreme compression by relying on two newly developed methods: Quantized Johnson-Lindenstrauss (QJL) and PolarQuant (both to be presented at AISTATS 2026). Together, this trio promises to drastically reduce key-value bottlenecks without compromising a model’s intelligence or accuracy.
To understand the magic of TurboQuant, you have to look at the two steps it uses to compress model size while maintaining perfect accuracy.
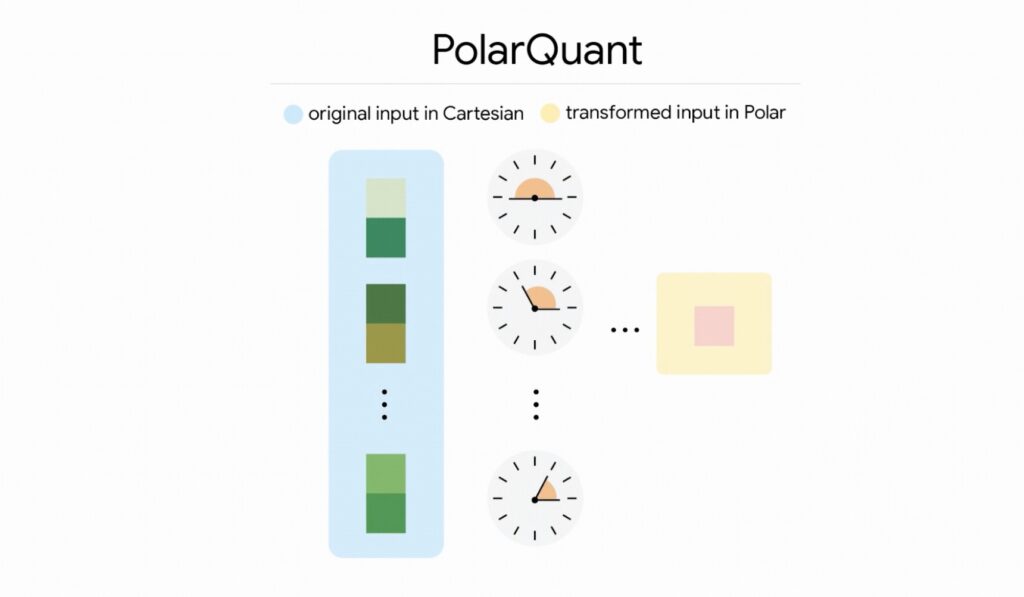
First, it relies on PolarQuant for high-quality compression. PolarQuant tackles memory overhead from a completely new angle. Instead of looking at a memory vector using standard Cartesian coordinates (X, Y, Z), it converts the vector into polar coordinates. Think of it like replacing the instruction “Go 3 blocks East and 4 blocks North” with “Go 5 blocks total at a 37-degree angle.” This yields two simple metrics: a radius (showing the strength of the core data) and an angle (indicating direction or meaning). TurboQuant randomly rotates the data vectors to simplify their geometry, mapping them onto a predictable “circular” grid rather than a constantly shifting square one. This allows the model to apply a standard quantizer to each part of the vector individually while entirely skipping the expensive data normalization step. This first stage uses the majority of the compression power to capture the core concept of the original vector.
The second step is eliminating hidden errors, which is where QJL comes into play. QJL is a zero-overhead, 1-bit mathematical trick based on the Johnson-Lindenstrauss Transform. After PolarQuant does the heavy lifting, TurboQuant uses just 1 bit of residual compression power to apply QJL to any tiny errors left over. QJL shrinks the complex data while preserving the essential distances between data points, reducing each resulting vector number to a single sign bit (+1 or -1). Using a special estimator to balance high-precision queries with low-precision data, QJL acts as an error-checker. It eliminates bias and ensures the model accurately calculates its attention score—the vital process an AI uses to decide which parts of a prompt are important and which can be ignored.
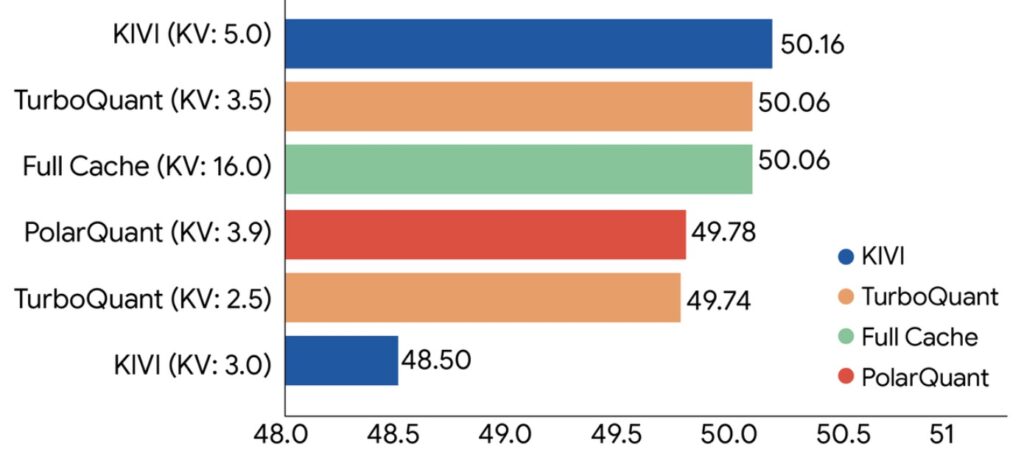
The results of combining these methods are nothing short of transformative. Researchers rigorously tested TurboQuant, QJL, and PolarQuant across standard long-context benchmarks, including LongBench, Needle In A Haystack, ZeroSCROLLS, RULER, and L-Eval, utilizing open-source models like Gemma and Mistral.
The experiments proved that TurboQuant achieves optimal scoring performance in dot product distortion and recall, all while massively shrinking the KV memory footprint. In notoriously difficult long-context “needle-in-haystack” tasks—where a model must find one specific piece of information buried in a massive text—TurboQuant achieved perfect downstream results while reducing the KV memory size by a factor of at least 6x. PolarQuant proved nearly loss-less for these tasks as well.
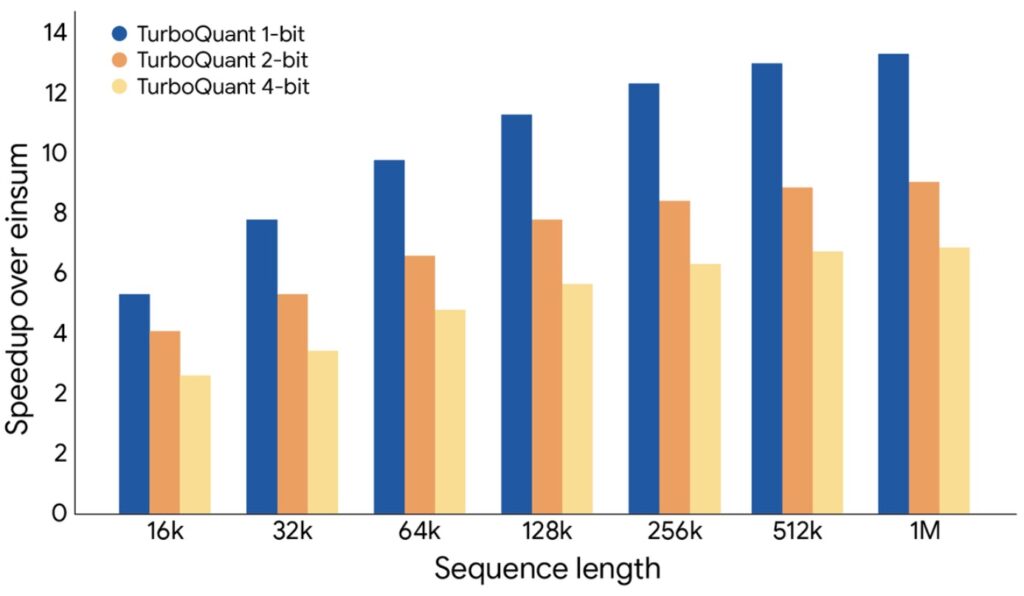
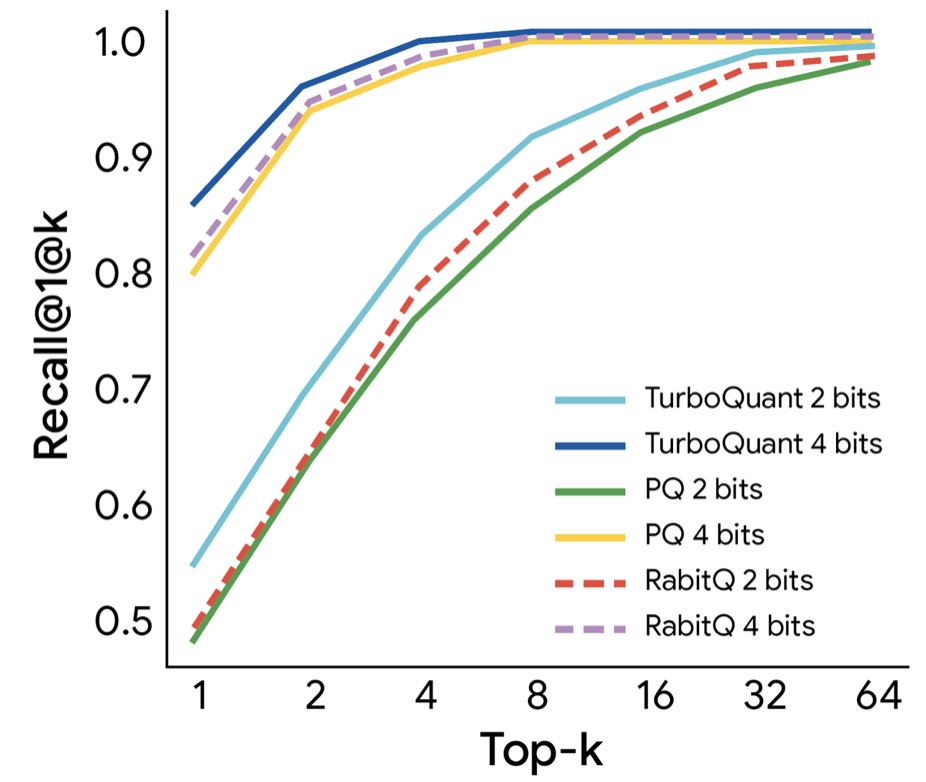
TurboQuant can quantize the KV cache to just 3 bits without requiring any training or fine-tuning, and without causing any compromise in model accuracy. Furthermore, 4-bit TurboQuant achieves up to an 8x performance increase over 32-bit unquantized keys on H100 GPU accelerators. When evaluated in high-dimensional vector search against state-of-the-art methods like PQ and RabbiQ, TurboQuant consistently achieved superior 1@k recall ratios (which measures how frequently the algorithm captures the true top result), despite the baselines using inefficient large codebooks and specific tuning.
Looking ahead, TurboQuant, QJL, and PolarQuant represent more than just clever engineering. They are fundamental algorithmic breakthroughs backed by strong theoretical proofs, operating near theoretical lower bounds of efficiency. While solving the KV cache bottleneck in massive models is an immediate victory, the broader implications are staggering. As modern search evolves beyond keywords to true semantic search—understanding human intent across billions of vectors—techniques like TurboQuant are essential. By allowing engineers to build and query massive vector indices with minimal memory, near-zero preprocessing time, and state-of-the-art accuracy in a data-oblivious manner, TurboQuant is setting a new benchmark for the future of artificial intelligence.