Blending a lightweight hybrid architecture with profound emotional intelligence, Voxtral TTS clones voices from just three seconds of audio and speaks nine languages with native authenticity.
- Instant, Expressive Voice Cloning: Voxtral TTS requires only three seconds of reference audio to generate highly realistic speech that captures a speaker’s unique personality, emotional dexterity, and natural rhythm.
- Multilingual Mastery and Superior Naturalness: Supporting nine global languages and zero-shot cross-lingual adaptation, the model achieved a 68.4% win rate over ElevenLabs Flash v2.5 in blind human evaluations for naturalness and expressivity.
- Enterprise-Ready Hybrid Architecture: Built on a lightweight 4-billion-parameter framework with ultra-low latency (70ms), it combines autoregressive semantic token generation with flow-matching acoustic tokens, and is available under a CC BY-NC license.

Audio is rapidly becoming the ultimate user interface. As human-computer interactions evolve past screens and keyboards, the demand for natural, expressive text-to-speech (TTS) systems has skyrocketed. Applications spanning virtual assistants, immersive audiobooks, and vital accessibility tools all rely on voice generation. However, while recent neural models have achieved strong intelligibility, they have historically struggled to cross the “uncanny valley” of robotic cadence. Capturing the true nuances, emotional context, and expressivity of human speech—especially in a zero-shot voice cloning setting—has remained a massive industry challenge. Enter Mistral.ai’s Voxtral TTS, a transformative multilingual text-to-speech model that fundamentally redefines what synthetic audio can sound like.
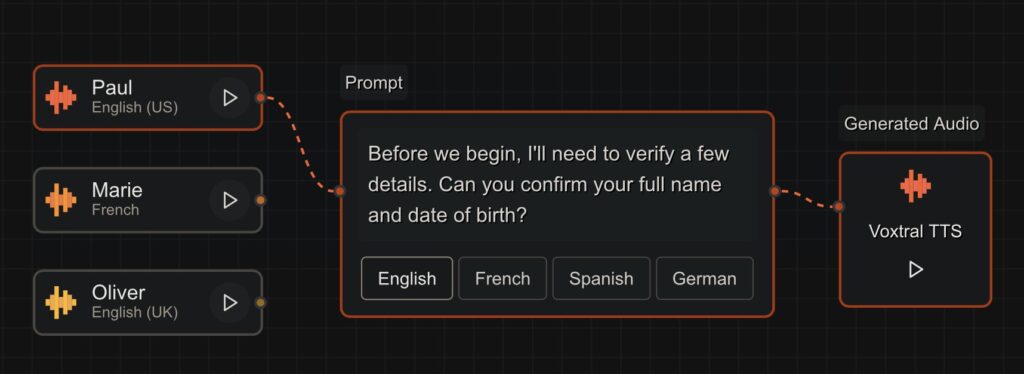
A truly natural voice generation system hinges on a model’s ability to interpret text, rather than simply recite it. Contextual understanding dictates whether a sentence should be delivered with a neutral tone, a joyful lilt, or a sarcastic bite. Voxtral TTS excels at this contextual interpretation while simultaneously mastering speaker modeling. With as little as three seconds of reference audio, the model does not just mimic a voice; it captures a speaker’s distinct personality. This includes their natural pauses, rhythm, intonations, and even human disfluencies. Whether an enterprise wants to maintain a conversational, casual brand voice or a formal, neutral tone, Voxtral TTS offers instant customizability, allowing developers to extend beyond Mistral’s preset API voices to build out highly personalized, in-house voice libraries.
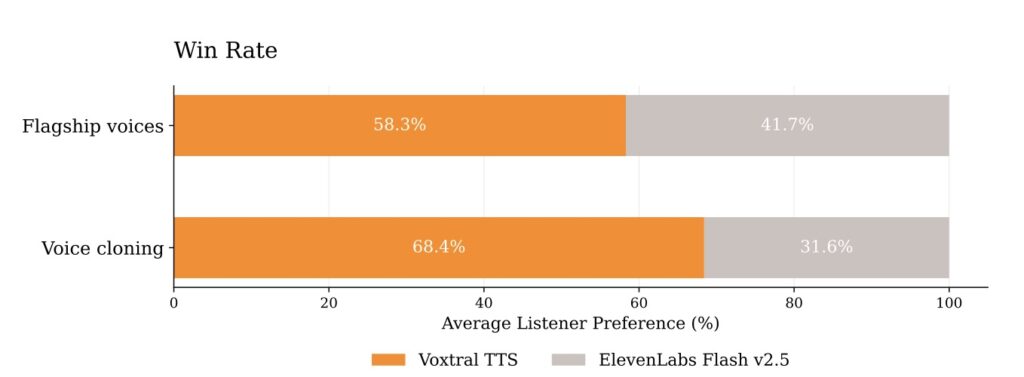
To prove its efficacy, Mistral.ai bypassed easily manipulated automated metrics like word-error-rate, which often fail to measure true naturalness. Instead, they relied on comparative human evaluations conducted by native speakers. What makes speech natural is incredibly nuanced, requiring a deep understanding of cultural differences and typical speaking patterns. In a zero-shot multilingual custom voice setting, human annotators evaluated naturalness, accent adherence, and acoustic similarity to original references. The results were decisive: Voxtral TTS achieved a 68.4% win rate over ElevenLabs Flash v2.5 while maintaining a similar Time-to-First-Audio (TTFA). Furthermore, it performed at parity with the heavyweight ElevenLabs v3 model, successfully supporting complex emotion-steering for exceptionally lifelike interactions.
Trained on a massive speech dataset, Voxtral TTS is built for global deployment, boasting state-of-the-art performance across nine languages: English, French, German, Spanish, Dutch, Portuguese, Italian, Hindi, and Arabic. Beyond standard translation, the model exhibits remarkable zero-shot cross-lingual voice adaptation. For instance, a user can provide a French voice prompt alongside English text, and the model will generate natural-sounding English speech delivered with an authentic French accent. This inherent flexibility makes Voxtral TTS an invaluable asset for building sophisticated cascaded speech-to-speech translation systems that preserve the original speaker’s vocal identity across language barriers.
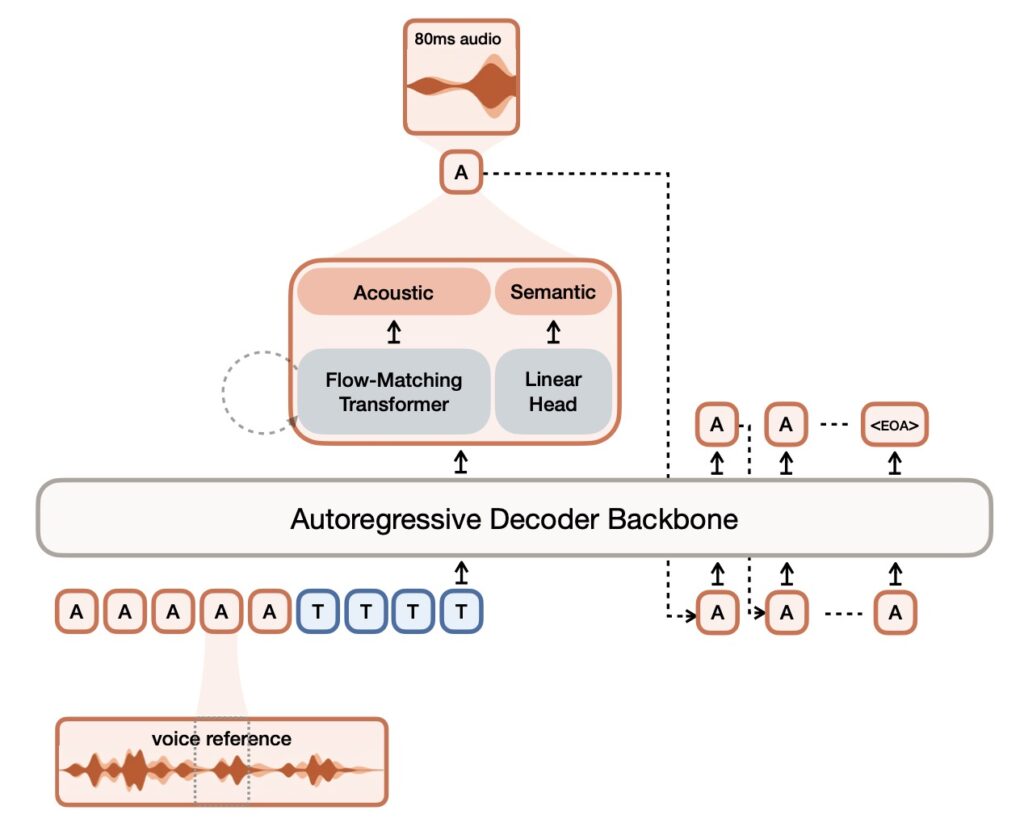
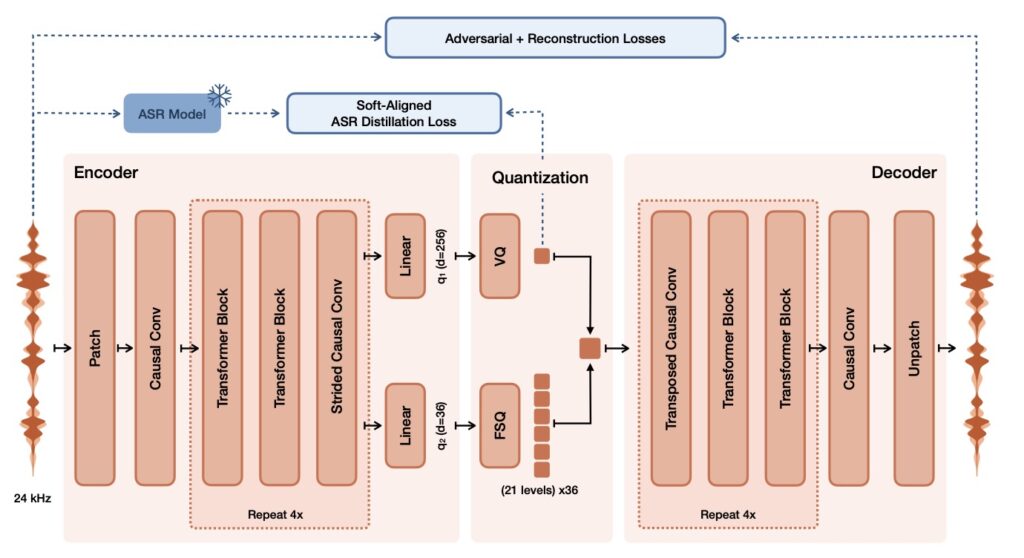
Beneath its expressive output lies a highly optimized, transformer-based hybrid architecture built upon the Ministral 3B foundation. The 4-billion-parameter model is brilliantly segmented: a 3.4B parameter transformer decoder backbone handles the autoregressive generation of semantic tokens, while a 390M parameter flow-matching acoustic transformer runs 16 function evaluations (NFEs) to produce acoustic latents. All of this is tied together by the proprietary 300M parameter Voxtral Codec, a neural audio tokenizer trained from scratch. This codec processes audio causally using a semantic VQ (with an 8192 vocabulary) and an acoustic FSQ (36 dimensions and 21 levels) latent, producing them at a highly efficient 12.5Hz frame rate.
For enterprise voice agents, the tension between high-quality audio and low latency is a constant battle. Voxtral TTS solves this by achieving a staggering model latency of just 70ms for a typical 10-second, 500-character input, alongside a real-time factor (RTF) of roughly 9.7x. The model natively generates up to two minutes of continuous audio, while the Mistral API leverages smart interleaving to handle arbitrarily long generations without breaking a sweat. By releasing the model weights under a CC BY-NC license and making it available in Mistral Studio, Mistral.ai is closing the loop on audio intelligence. Whether working alongside Voxtral Transcribe for full speech-to-speech pipelines or integrating into existing LLM stacks, Voxtral TTS provides a lightweight, cost-effective, and deeply human output layer for the next generation of voice AI.