Strategic “Budget” Models Deliver Near-Flagship Reasoning with Ultra-Low Latency for Developers and Enterprise Workflows
- Optimized for Speed and Scale: The new GPT-5.4 mini and nano models are engineered to solve the “latency tax” in complex AI workflows, offering up to 2X the speed of previous mini iterations while maintaining high reasoning quality.
- Architected for Agentic Design: These models enable a “multi-model” approach where large models (like GPT-5.4 Thinking) act as planners, while mini and nano variants execute subtasks, tool calls, and UI interactions at a fraction of the cost.
- Disruptive Price-to-Performance: With pricing as low as $0.20 per million input tokens for GPT-5.4 nano, OpenAI is making high-performance multimodal and coding capabilities accessible for high-volume, real-time applications.
The evolution of artificial intelligence has long been a race toward “bigger and more powerful.” As developers begin building sophisticated research agents and autonomous assistants, a new hurdle has emerged: latency. In an environment where an agent must retrieve documents, call multiple APIs, and summarize findings across several turns, the cumulative delay of a massive flagship model can stall the user experience.
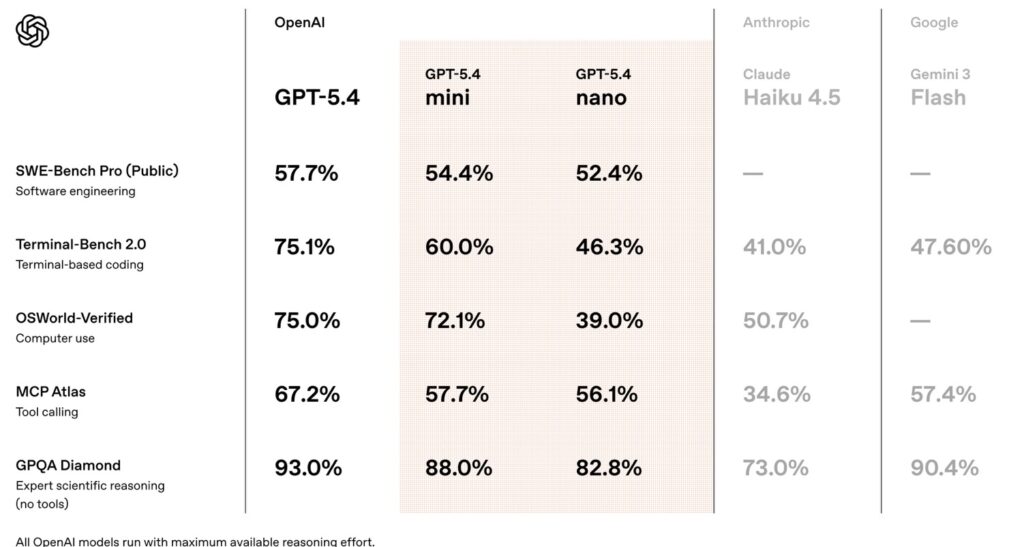
To address this, OpenAI has officially launched GPT-5.4 mini and GPT-5.4 nano. These models represent a strategic shift, providing “budget” language offerings that don’t compromise on the intelligence required for professional-grade work.
GPT-5.4 Mini: The New Workhorse for Production
GPT-5.4 mini is designed to be the primary executor for production workflows. It distills the strengths of the flagship GPT-5.4 into a leaner architecture that is significantly more capable than the older GPT-5 mini in coding, reasoning, and multimodal understanding.
Key features include:
- Multimodal Fluency: Developers can build experiences that interpret screenshots or UI states in real-time.
- Reliable Tool Use: The model is optimized for function calling, making it a dependable “sub-agent” for navigating software or searching enterprise databases.
- Speed: It runs roughly twice as fast as its predecessor, making it ideal for developer copilots where fast iteration loops are critical.
Early testers are already seeing the benefits. Notion, the popular productivity platform, has utilized these models to handle complex page formatting. According to Abhisek Modi, AI engineering lead at Notion, GPT-5.4 mini handles focused tasks with impressive precision, matching or exceeding much larger models like GPT-5.2 at a fraction of the compute cost.
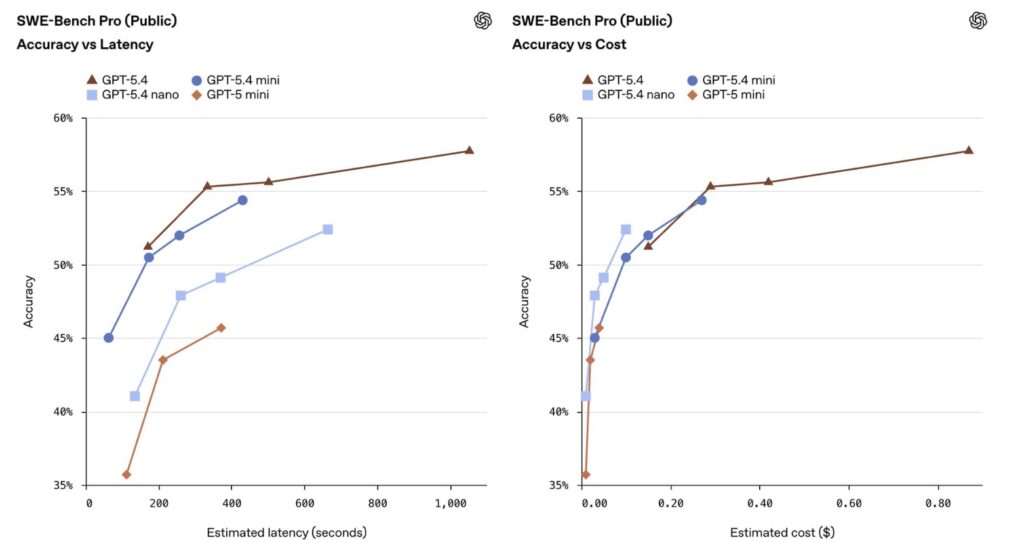
GPT-5.4 Nano: Automation at Scale
For tasks where speed and cost are the only true priorities, OpenAI introduced GPT-5.4 nano. This is the smallest and fastest model in the lineup, specifically tuned for short-turn tasks like classification, data extraction, and ranking.
While it doesn’t possess the deep multi-step reasoning of the “Thinking” models, its performance remains formidable. It scores 52.39% on SWE-bench Pro, outclassing previous mini models. It thrives as a “guardrail” model—performing safety checks or routing requests to larger models—ensuring that high-volume pipelines remain both safe and inexpensive.
A Tiered Approach to Intelligence
The release of these models highlights a growing trend in AI development: the senior-junior engineer dynamic. In this ecosystem, a high-performance model like GPT-5.4 Thinking acts as the “Senior Engineer,” planning the overarching strategy. It then delegates granular tasks—such as reviewing a specific file or normalizing a dataset—to “Junior” models like GPT-5.4 mini or nano.

This tiered architecture is already proving successful for firms like Hebbia. CTO Aabhas Sharma noted that GPT-5.4 mini actually achieved stronger source attribution and citation recall than the larger flagship model in certain evaluations, proving that “bigger” isn’t always “better” for specific utility tasks.
Accessibility and Pricing
The economic argument for these smaller models is undeniable. While the flagship GPT-5.4 costs $2.50 per million input tokens, GPT-5.4 mini sits at $0.75, and GPT-5.4 nano drops to a mere $0.20. For developers using the Codex platform, the mini model uses only 30% of the standard GPT-5.4 quota.
By providing a spectrum of models ranging from “Thinking” to “Nano,” OpenAI is giving developers the surgical tools needed to build responsive, cost-effective AI agents that can finally keep up with the speed of human thought.