Researchers from Shanghai Jiao Tong University, HKUST, and Microsoft Research have recently unveiled Make-It-3D, an innovative approach that transforms single images into high-fidelity 3D models with remarkable precision and visual quality. This groundbreaking method overcomes the inherent challenge of estimating 3D geometry and filling in unseen textures by leveraging the prior knowledge from pretrained 2D diffusion models.
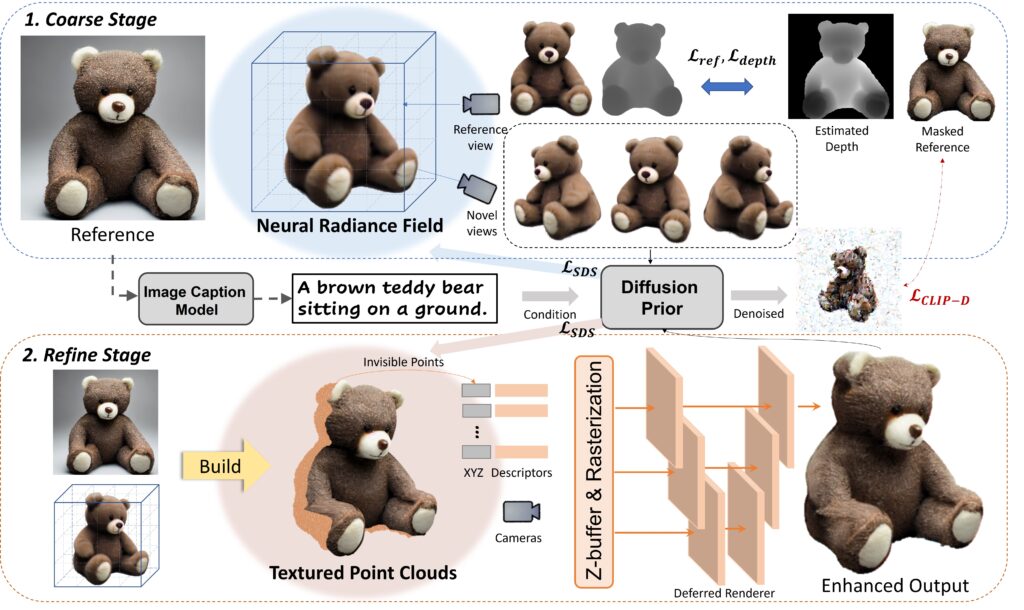
Make-It-3D utilizes a two-stage optimization pipeline. In the first stage, a neural radiance field (NeRF) is optimized, integrating constraints from the reference image at the frontal view and diffusion prior at novel views. The second stage transforms the coarse model into textured point clouds, enhancing realism with diffusion prior and utilizing the high-quality textures from the reference image.
This groundbreaking method significantly outperforms previous approaches, resulting in faithful reconstructions and visually impressive 3D models. Make-It-3D marks the first attempt to achieve high-quality 3D creation from single images for general objects, paving the way for various applications, including text-to-3D creation and texture editing.
One of the standout features of Make-It-3D is its ability to generate a diverse range of visually stunning 3D models based solely on text descriptions. Furthermore, Make-It-3D allows for 3D-aware texture modifications such as tattoo drawing and stylization, opening up new possibilities in 3D content creation and editing.

The collaboration between researchers at Shanghai Jiao Tong University, HKUST, and Microsoft Research has led to a truly groundbreaking approach in the field of 3D modeling. Make-It-3D has the potential to revolutionize industries such as gaming, film, architecture, and design by streamlining the process of creating high-quality 3D content from single images. The method’s ability to generate accurate and visually impressive 3D models could have a profound impact on how artists and designers approach their work, enabling them to achieve more in less time and with greater flexibility.
The research team’s innovative use of pretrained 2D diffusion models and a two-stage optimization pipeline has demonstrated the immense potential of integrating artificial intelligence and computer vision technologies in the realm of 3D modeling. As Make-It-3D continues to evolve, we can expect further advancements in the capabilities of this pioneering approach.
With the growing demand for immersive and realistic 3D content in various industries, Make-It-3D could become an essential tool for creators and developers worldwide. Its ability to efficiently generate high-quality 3D models from single images has the potential to streamline workflows and inspire new forms of creativity in the rapidly evolving digital landscape.
As researchers continue to refine and expand Make-It-3D’s capabilities, we look forward to witnessing the broader implications of this groundbreaking project and the transformative impact it could have on the future of 3D content creation and editing.
Project: https://make-it-3d.github.io