With revolutionary attention mechanisms and a massive reduction in KV cache, DeepSeek-V4 makes 1M-context agentic workflows fast, highly efficient, and fiercely competitive.
- The 1M Context Standard: DeepSeek-V4 introduces two powerhouse MoE models—V4-Pro (1.6T total / 49B active) and V4-Flash (284B total / 13B active)—making a massive 1-million-token context length the default across all official services.
- Architectural Breakthroughs: By intelligently interleaving Compressed Sparse Attention (CSA) and Heavily Compressed Attention (HCA), V4 slashes KV cache memory usage to a mere 2% of traditional models, permanently solving the long-horizon agent bottleneck.
- Agent-First Engineering: Features like cross-turn interleaved thinking, an XML-based tool-call schema (
|DSML|), and robust RL training in the massive DSec sandbox propel V4 to perform on par with top-tier closed models in complex coding and agentic benchmarks.
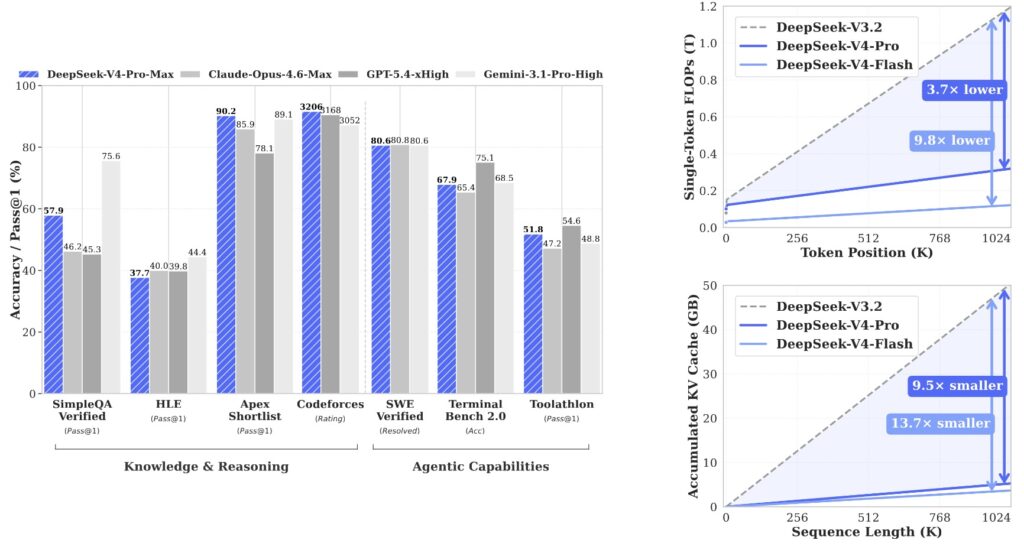
Welcome to the era of cost-effective, million-token context intelligence. Today, DeepSeek has officially open-sourced V4, marking a monumental leap in how large language models handle immense, long-running workloads. While recent attention has swirled around the company, DeepSeek remains grounded in its longtermism, advancing steadily toward the ultimate goal of AGI. With the release of V4, they have proven that the open-source community can not only match but structurally out-innovate the world’s top closed-source models in agentic capabilities.
The Lineup: Pro Power and Flash Efficiency
DeepSeek-V4 arrives with two primary Mixture-of-Experts (MoE) checkpoints, both boasting a 1M-token context window. The flagship, DeepSeek-V4-Pro, features 1.6 trillion total parameters with 49 billion active. It delivers world-class reasoning, beating all current open models in Math, STEM, and Coding, and trailing only Gemini-3.1-Pro in Rich World Knowledge.
For developers prioritizing speed and API cost-effectiveness, DeepSeek-V4-Flash operates at 284 billion total parameters with 13 billion active. Both models are available on the Hub as base and instruct variants, heavily utilizing FP8 storage alongside an ultra-efficient FP4 precision for MoE expert weights.
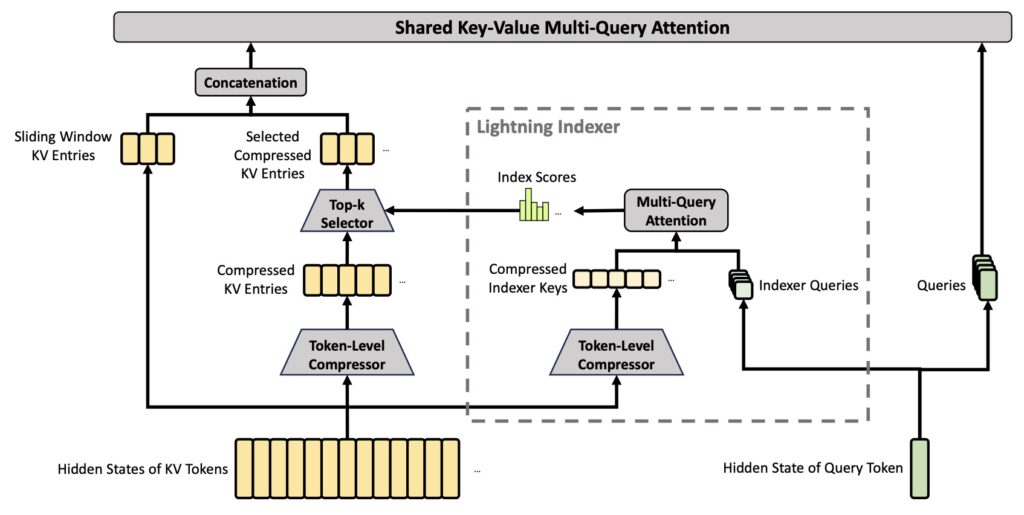
Curing the KV Cache Headache
A 1-million-token context window is just raw capacity; its true value depends on the cost of running it. Historically, running a frontier open model as an agent breaks in predictable ways: as the tool-use trajectory grows, the KV cache fills the GPU, compute costs skyrocket, and the model grinds to a halt.

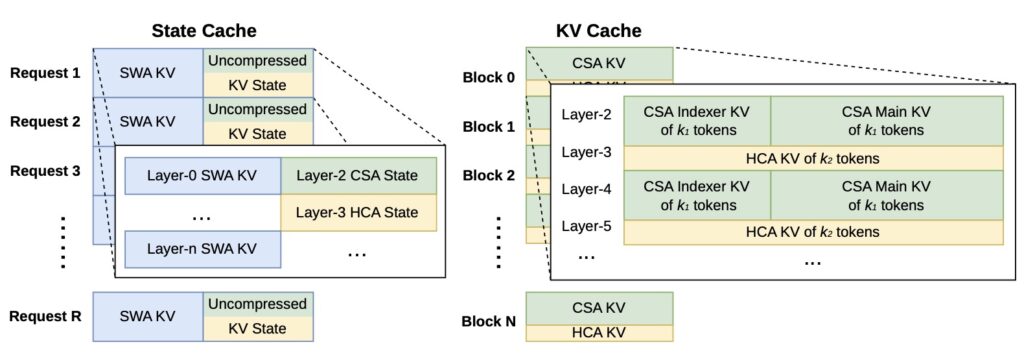
V4 was engineered from the ground up to fix these failures. DeepSeek-V4-Pro requires just 27% of the single-token inference FLOPs and a staggering 10% of the KV cache memory compared to V3.2. V4-Flash pushes this even further, dropping to 10% of the FLOPs and 7% of the KV cache. When compared to an established grouped query attention architecture (8 heads, bfloat16), V4 requires roughly 2% of the traditional cache size.
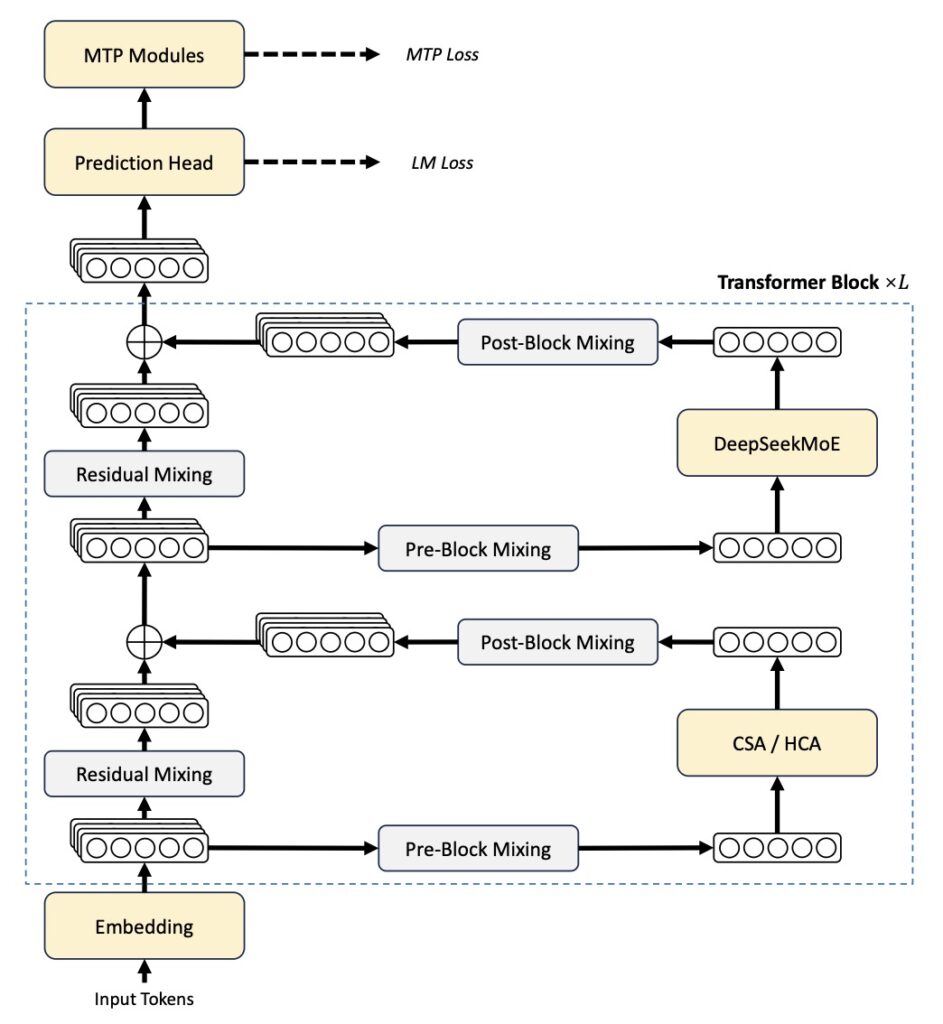
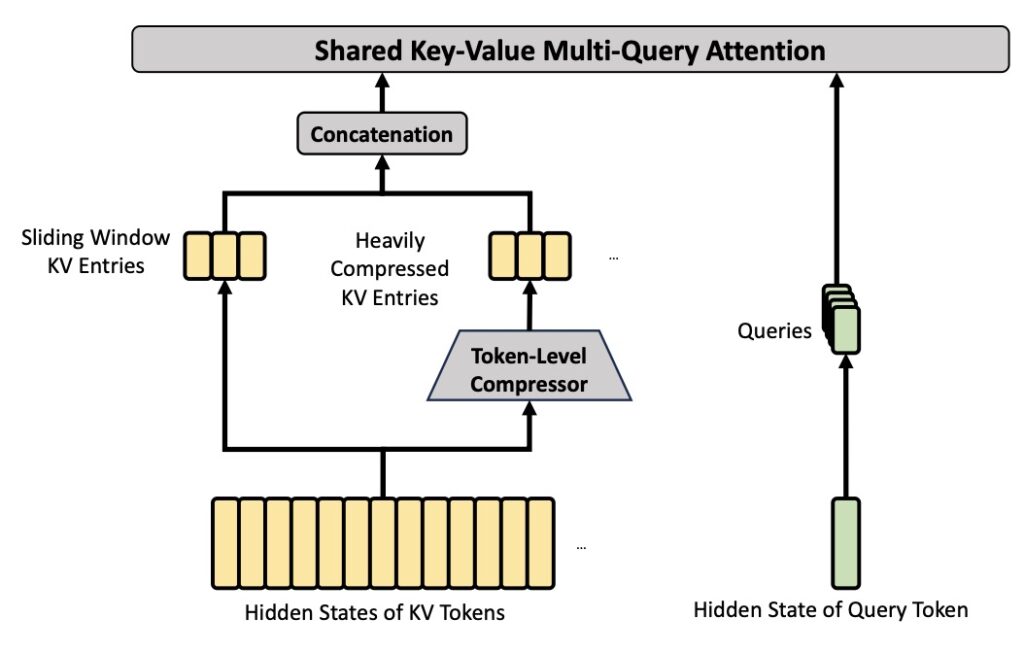
Hybrid Attention: CSA and HCA
This unprecedented efficiency is achieved by splitting attention into two novel mechanisms and interleaving them across the model’s layers:
- Compressed Sparse Attention (CSA): Compresses KV entries by 4x using softmax-gated pooling with a learned positional bias. A lightning-fast FP4 indexer picks the top-k compressed blocks per query, shrinking the search space drastically.
- Heavily Compressed Attention (HCA): Compresses KV entries by 128x, allowing every query to cheaply and densely attend to every compressed block.
By alternating these paths—for instance, in V4-Pro’s 61-layer stack, layers 0–1 use HCA, layers 2–60 alternate CSA and HCA, and a final MTP block runs sliding-window only—the model preserves capacity exactly where it is needed without wasting compute.
Purpose-Built for Agents
Efficient long-context attention is necessary, but post-training is where V4 truly becomes an agentic powerhouse. V4 is seamlessly integrated with leading AI agents like Claude Code, OpenClaw, and OpenCode, driven by three massive improvements:
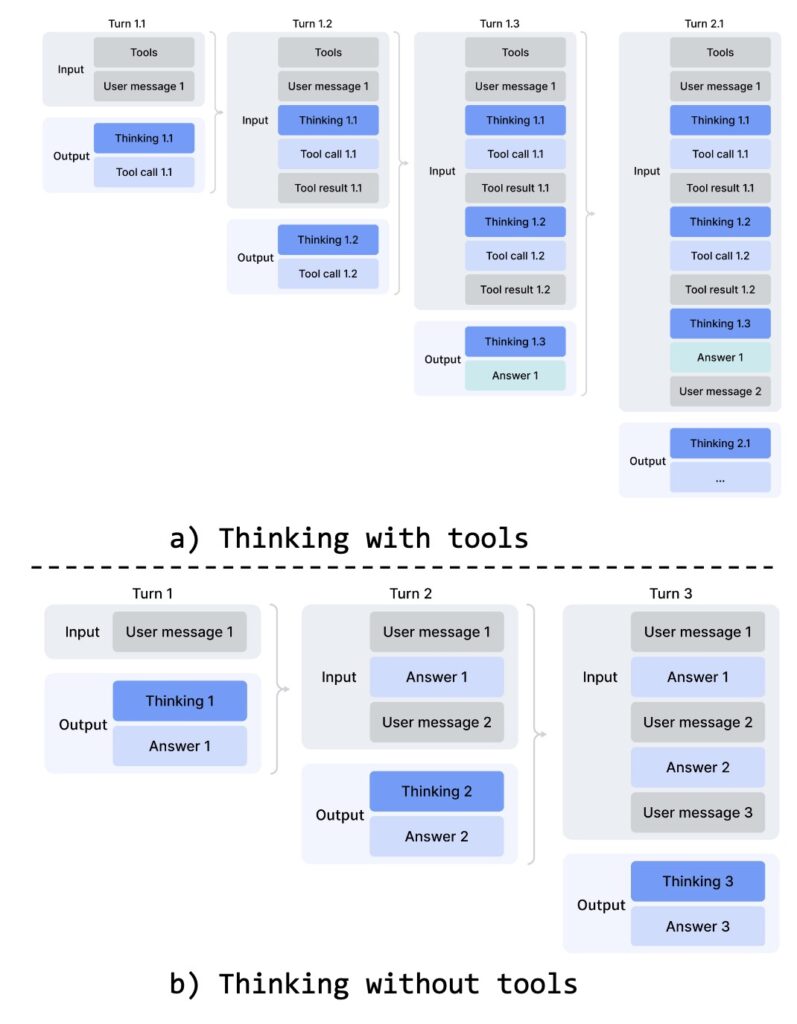
- Interleaved Thinking Across Tool Calls: Previous models lost their accumulated reasoning states when a new user message arrived. V4 preserves the complete reasoning history across all rounds and user turns when tool calls are involved, allowing for a coherent, cumulative chain of thought over long-horizon tasks.
- Dedicated XML Tool-Call Schema: V4 introduces the
|DSML|special token and an XML-based format that separates string parameters from structured JSON. This eliminates the frustrating escaping errors and parsing failures common when models emit nested quoted content. - The DSec Sandbox: V4’s agent behavior was honed via Reinforcement Learning (RL) inside DeepSeek Elastic Compute (DSec)—a massive Rust platform running hundreds of thousands of concurrent sandboxes across containers, microVMs, and full VMs. Features like fast image loading via 3FS storage and preemption-safe trajectory replay ensured highly robust training.
Benchmarks that Rival the Best
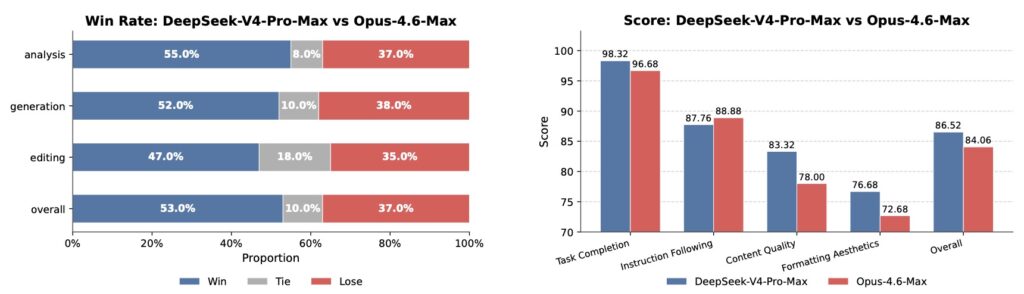
The architectural and post-training investments have paid off spectacularly. In agent benchmarks, V4-Pro-Max separates itself from the open-source field:
- SWE Verified: 80.6 resolved, sitting within a single point of Opus-4.6-Max (80.8) and Gemini-3.1-Pro (80.6).
- Terminal Bench 2.0: Scores 67.9, ahead of GLM-5.1 and K2.6.
- MCPAtlas Public: 73.6, second only to Opus-4.6-Max.
- Toolathlon: 51.8, leading its direct competitors.
Internally, DeepSeek tested V4-Pro on an R&D coding benchmark across PyTorch, CUDA, Rust, and C++, hitting a 67% pass rate. Among DeepSeek’s own developers using V4-Pro daily, 52% report it is ready to replace their primary coding model entirely. Furthermore, long-context retrieval remains exceptional, with MRCR 8-needle accuracy holding at 0.82 through 256K tokens and a respectable 0.59 at a full 1M tokens.
DeepSeek-V4 is a masterclass in AI engineering. By rethinking how models manage memory and reasoning over extended interactions, it provides a blueprint for the future of agentic AI. The instruct models support three distinct reasoning modes—Non-think, Think High, and Think Max (the latter requiring a 384K context buffer)—optimized for a temperature of 1.0 and top_p of 1.0.
As the community adopts the new |DSML| schema and leverages V4’s interleaved thinking, the gap between open-source models and frontier closed models hasn’t just narrowed; in the realm of complex agent tasks, it has officially closed.