NVIDIA’s Innovative TTA Model Combines Unmatched Efficiency and Faithfulness
- Revolutionary Speed and Quality: TANGOFLUX generates 30 seconds of high-quality 44.1kHz audio in just 3.7 seconds on a single A40 GPU, setting a new benchmark for efficiency.
- Advanced Alignment Framework: The novel CLAP-Ranked Preference Optimization (CRPO) ensures faithful audio alignment with textual prompts, overcoming challenges of preference generation in TTA.
- Practical Applications and Open Access: With state-of-the-art performance and open-sourced resources, TANGOFLUX is poised to transform multimedia content creation workflows.
Audio is a cornerstone of communication, storytelling, and creativity. From podcasts to music and sound effects, high-quality audio enriches user experiences across industries. However, traditional methods of audio creation are time-consuming and resource-intensive. Text-to-audio (TTA) models offer a groundbreaking alternative, enabling automatic, high-fidelity audio generation directly from textual descriptions. Yet, existing models often struggle with controllability and alignment, occasionally generating audio that diverges from user intent.
Enter TANGOFLUX
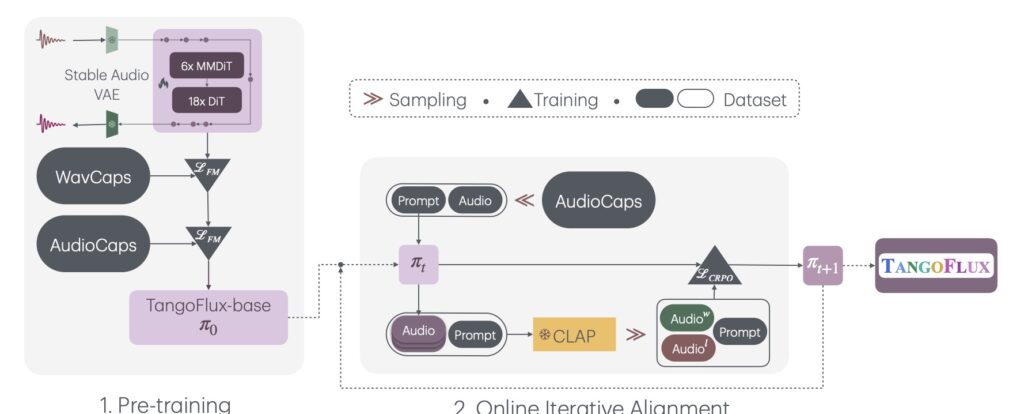
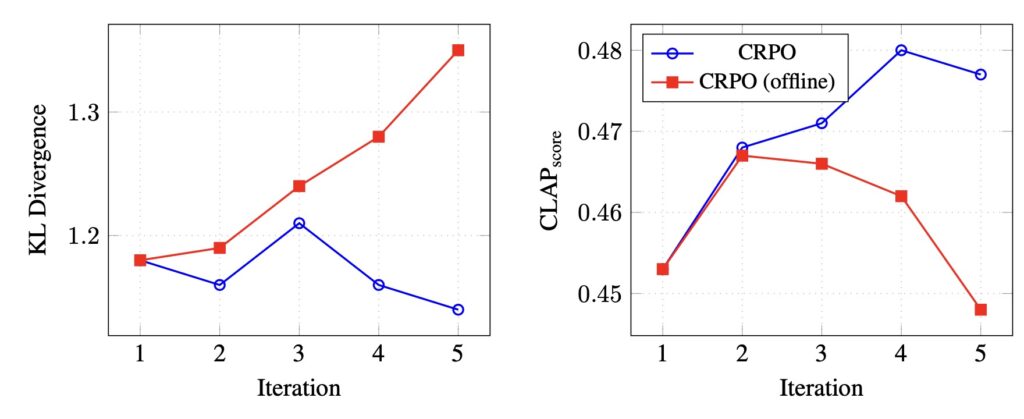
NVIDIA’s TANGOFLUX addresses these challenges with unmatched speed and accuracy. Powered by 515 million parameters, the model can generate up to 30 seconds of high-resolution audio in mere seconds. At its core is CRPO, a framework designed to overcome the limitations of traditional preference generation in TTA. By iteratively creating and optimizing preference data, CRPO ensures that TANGOFLUX aligns closely with user prompts, producing audio that faithfully represents input descriptions.
Performance That Speaks for Itself
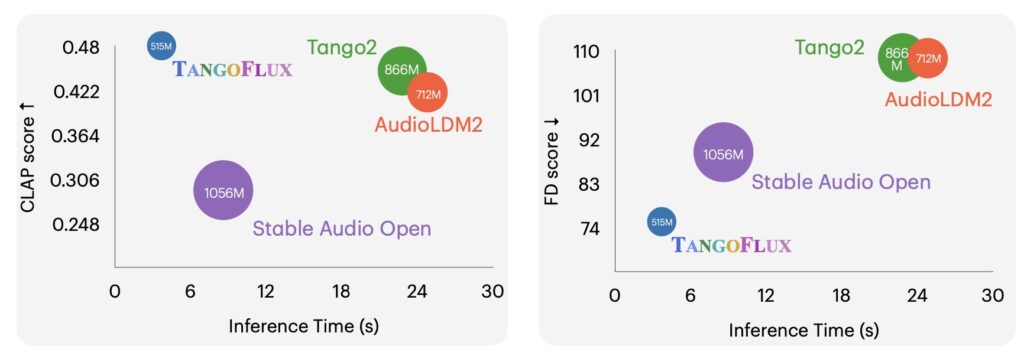
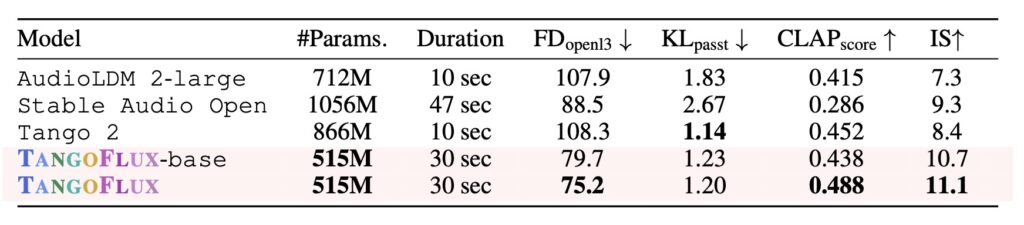
TANGOFLUX achieves state-of-the-art results across both objective and subjective benchmarks. Its robustness shines even when sampling with fewer time steps, demonstrating consistent quality and alignment. Unlike diffusion-based models, TANGOFLUX avoids common pitfalls such as hallucinations or omissions in generated audio, making it a reliable tool for diverse applications.
Unlocking New Possibilities
The implications of TANGOFLUX extend far beyond speed and quality. By streamlining audio production workflows, it empowers creators in industries like gaming, film, and music. Its ability to produce accurate, expressive audio from textual inputs opens doors to new forms of multimedia storytelling. Moreover, the open-sourcing of TANGOFLUX’s code and models fosters collaboration and further innovation in the field.
TANGOFLUX represents a pivotal advancement in text-to-audio technology. By combining cutting-edge speed, precision, and accessibility, it sets a new standard for what TTA models can achieve. As this technology continues to evolve, it promises to revolutionize how audio content is created and experienced, unlocking boundless potential for creativity and efficiency in multimedia industries.