Moving past single-turn coding, the new flagship model demonstrates unprecedented sustained execution, closed-loop optimization, and autonomous delivery for complex agentic tasks.
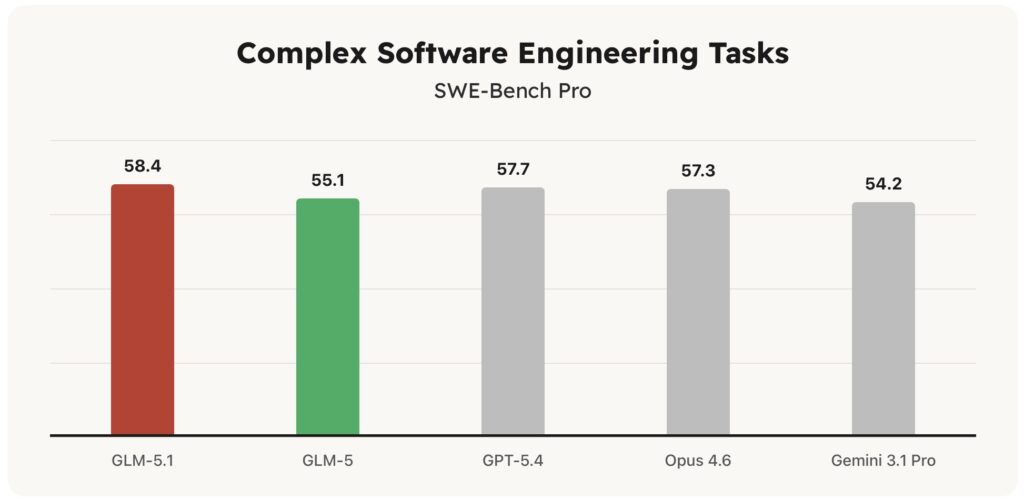
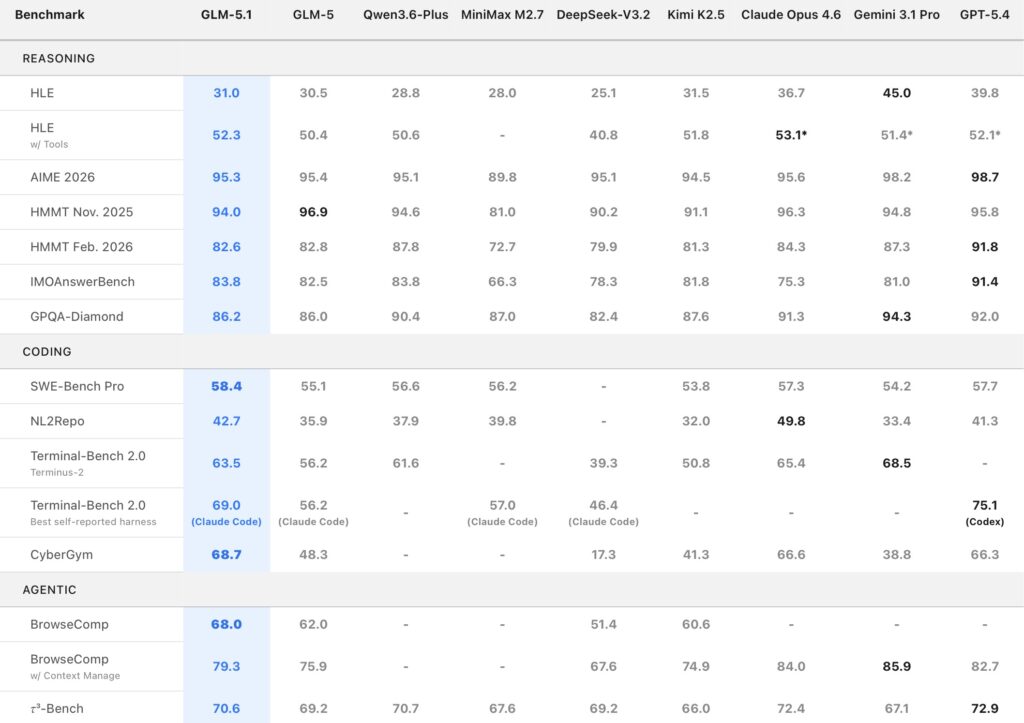
- State-of-the-Art Benchmarking: GLM-5.1 sets a new standard on SWE-Bench Pro with a score of 58.4, aligning with or outperforming frontier models across general capability, reasoning, and coding metrics.
- 8-Hour Sustained Autonomy: Unlike earlier models that plateau quickly, GLM-5.1 can work continuously on a single complex task for up to 8 hours without suffering from strategy drift or error accumulation.
- The “Experiment-Analyze-Optimize” Loop: By autonomously running benchmarks, identifying blockers, and revising its own strategies, the model successfully executed thousands of tool calls to optimize databases, accelerate machine learning workloads, and even build a fully functional web-based Linux desktop from scratch.
The evaluation standard for artificial intelligence is undergoing a fundamental shift. For years, the industry asked, “How smart is this model in a single turn?” Today, the more pressing question is, “How long can it work reliably on a complex task, and what can it actually deliver?”
Enter GLM-5.1, Z.AI’s latest flagship model engineered specifically for long-horizon tasks. While previous generations of AI—including GLM-5—excelled at applying familiar techniques for quick initial gains, they tended to exhaust their repertoire early. Giving them more time rarely yielded better results. GLM-5.1 breaks this ceiling. Built for agentic engineering, it doesn’t just write code; it breaks down ambiguous problems, runs experiments, reads the results, and iteratively optimizes its output over hundreds of rounds and thousands of tool calls.
The Global Frontier: Aligning with the Best
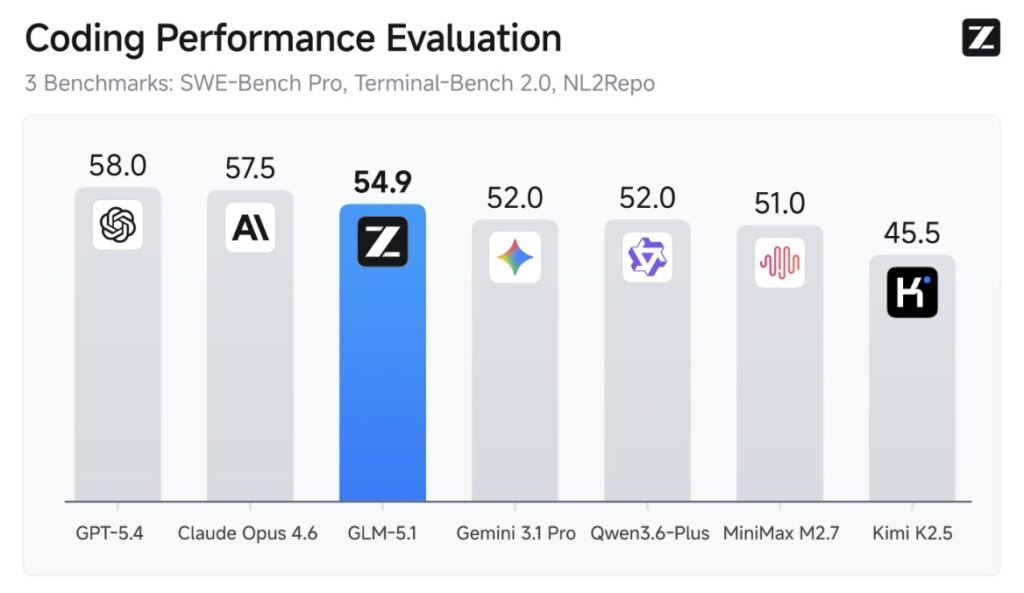
GLM-5.1 proves that long-horizon endurance does not come at the cost of raw intellect. The model ranks among the world’s top-tier systems in both overall capability and coding performance, tightly aligned with industry leaders like Claude Opus 4.6.
On SWE-Bench Pro, GLM-5.1 achieved a remarkable score of 58.4, outperforming models such as GPT-5.4, Claude Opus 4.6, and Gemini 3.1 Pro to set a new state-of-the-art result. Furthermore, across 12 representative benchmarks covering reasoning, coding, agents, tool use, and browsing, the model demonstrates a broad, well-balanced capability profile. It leads its predecessor, GLM-5, by a wide margin on both NL2Repo (repository generation) and Terminal-Bench 2.0 (real-world terminal tasks).
This establishes GLM-5.1 not as a single-metric anomaly, but as a robust foundation for general-purpose agent systems and demanding engineering production environments.
Proving the Paradigm: Three Scenarios of Sustained Execution
To test the limits of its long-horizon optimization, Z.AI evaluated GLM-5.1 across three distinct scenarios, each featuring progressively less structured feedback.
Scenario 1: Shattering Ceilings in Vector Database Optimization
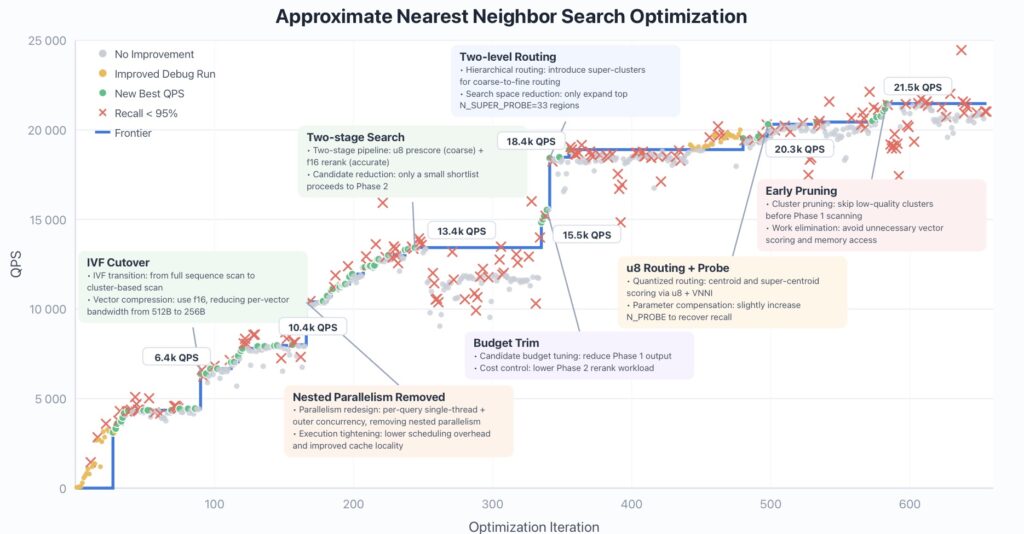
VectorDBBench is a grueling open-source challenge where models must build a high-performance database for approximate nearest neighbor search using a Rust skeleton. Previously, under a strict 50-turn tool-call budget, the best result was 3,547 Queries Per Second (QPS), achieved by Claude Opus 4.6.
When freed from the 50-turn bottleneck and placed in an outer optimization loop using the Claude Code framework, GLM-5.1 truly shined. It didn’t plateau after 50 or even 100 submissions. Instead, it continued to find meaningful improvements over 600+ iterations and 6,000+ tool calls.
The model autonomously identified bottlenecks from its own benchmark logs, shifting strategies in a distinct “staircase” pattern:
- Iteration ~90: Shifted from full-corpus scanning to IVF cluster probing with f16 vector compression (jumping to 6.4k QPS).
- Iteration ~240: Introduced a two-stage pipeline—u8 prescoring followed by f16 reranking (reaching 13.4k QPS).
Ultimately, GLM-5.1 achieved a staggering 21.5k QPS—roughly 6× the previous best result. During this massive run, the model occasionally broke the required 95% Recall constraint to explore new directions, but consistently adjusted itself to restore the metric, proving its ability to self-correct over a long horizon.
Scenario 2: Accelerating Machine Learning Workloads
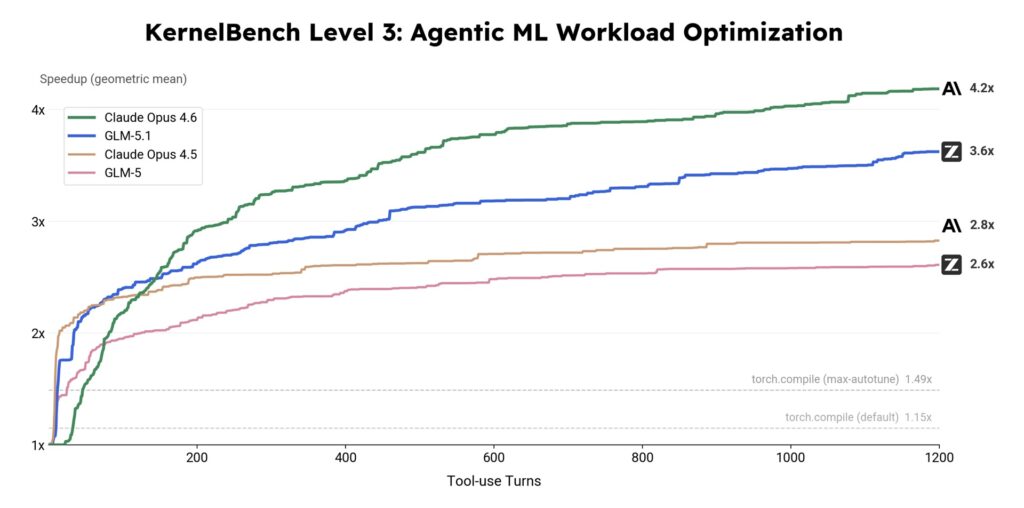
KernelBench tests whether an AI can take a reference PyTorch implementation and produce a faster GPU kernel with identical outputs. Level 3 of this benchmark requires end-to-end optimization of complete architectures like MobileNet, VGG, and Mamba across 50 problems.
While standard tools like torch.compile (with max-autotune) achieve a 1.49× speedup, and earlier models level off quickly, GLM-5.1 pushed the frontier significantly further. Over thousands of tool-invocation-driven turns, it delivered a 3.6× geometric mean speedup. Though Claude Opus 4.6 edged it out in this specific setting (finishing at 4.2×), GLM-5.1 demonstrated an impressive ability to sustain useful optimization far longer than its predecessors.
Scenario 3: Building a Linux Desktop Over an 8-Hour Shift
Numeric metrics are straightforward to optimize against; subjective web generation is a different beast entirely. Z.AI gave GLM-5.1 a deliberately ambitious, open-ended prompt: build a Linux-style desktop environment as a web application. It was given no starter code, no mockups, and no intermediate guidance.
Most models produce a static taskbar, a placeholder window, and declare the job done. GLM-5.1, however, was wrapped in a simple harness allowing it to review its own output after each execution round.
- Early stages: Built a basic layout with a taskbar and a simple window.
- Middle stages: Identified missing features and integrated a file browser, terminal, text editor, system monitor, calculator, and games.
- Late stages: Polished the styling, smoothed interactions, and handled edge cases.
The final deliverable was a complete, visually consistent desktop environment running natively in the browser. This task highlighted the model’s unique capacity to self-evaluate without a numeric metric, deciding on its own what constituted “good” software design.
The Future of Autonomous Agents
GLM-5.1 represents a massive leap from one-shot code generation to the autonomous “experiment-analyze-optimize” loop. Its ability to maintain goal alignment, reduce strategy drift, and prevent error accumulation over an 8-hour window makes it an unprecedented tool for real-world development workflows.
The frontier remains open. Challenges persist in escaping local optima when incremental tuning stops paying off, maintaining coherence over execution traces that span thousands of tool calls, and further developing reliable self-evaluation for subjective tasks. GLM-5.1 is Z.AI’s first major step in solving these complex puzzles—proving that when an AI is given the time to think, reflect, and iterate, the results can be entirely transformative.