Packing massive AI capabilities into a sub-500MB footprint, Liquid’s newly upgraded 350M-parameter model brings high-speed data extraction, reliable tool use, and agentic workflows directly to the edge.
- Massive Power, Micro Footprint: Quantized at under 500MB and running on less than 1GB of memory, the model leverages extended pre-training (28T tokens) to deliver high-quality AI in environments where compute, memory, and latency are severely constrained.
- Unrivaled Task Specialization: It consistently outperforms models more than twice its size in core capabilities like data extraction, instruction following, and tool use, achieving unprecedented accuracy for a model of its scale.
- Universal Hardware Ecosystem: With robust day-one support across AMD, Qualcomm, Intel, and Apple Silicon, LFM2.5-350M runs blazingly fast on everything from cloud GPUs to smartphones and sub-$300 edge devices like the Raspberry Pi 5.
The AI industry often equates bigger with better, but the reality of enterprise and edge computing demands a different approach. Enter LFM2.5-350M, a model purpose-built for the real world where compute, memory, and latency are at a premium. Liquid AI’s latest release proves that you don’t need a massive hardware footprint to achieve production-grade reliability. Designed specifically for reliable data extraction and tool use—areas where models of this size traditionally struggle—LFM2.5-350M is bringing agentic loops to the edge.
Under the Hood: Scaled Training and Throughput
Built on the highly efficient LFM2 architecture, the LFM2.5-350M is a massive leap forward from its predecessor. The development team extended its pre-training from 10 trillion to a staggering 28 trillion tokens, complemented by large-scale, multi-stage reinforcement learning. This hybrid model architecture pays immediate dividends in speed.
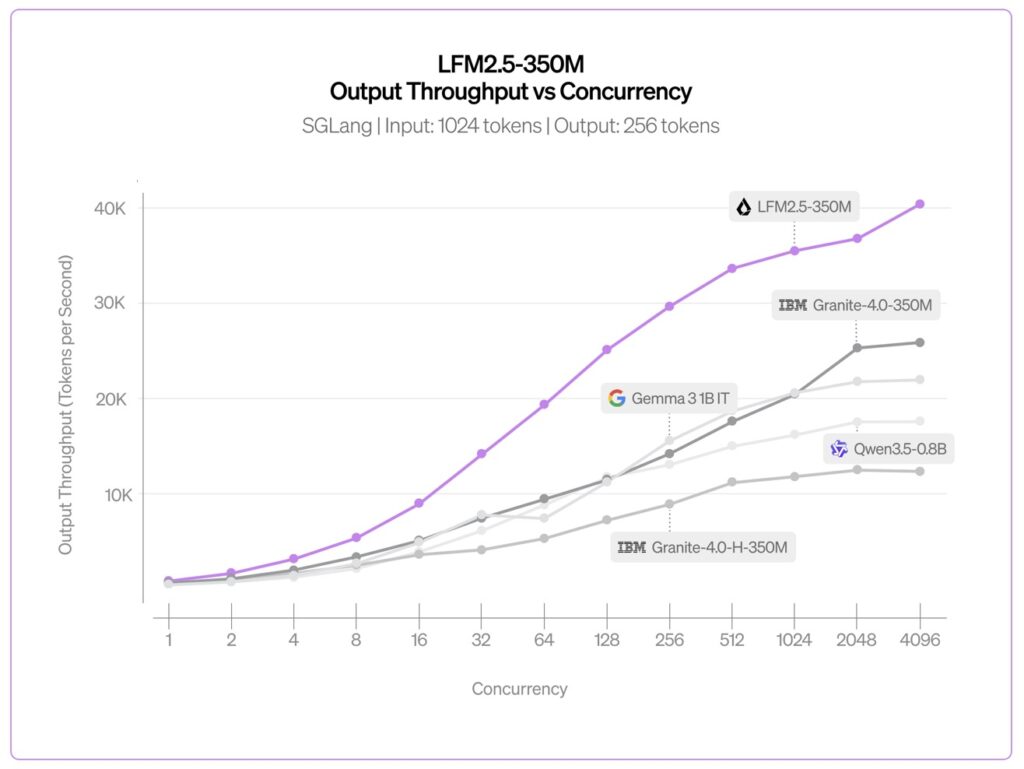
For big data processing and high-throughput environments, the results are striking. When benchmarked using SGLang on a single NVIDIA H100 SXM5 GPU at high concurrency, LFM2.5-350M achieved a peak throughput of 40.4K output tokens per second. To put that in perspective, that is the equivalent of generating over 3.5 billion tokens per day on just one H100. It is significantly faster than similar-sized competitors, including SSM hybrids like Granite-4.0-H-1B and Gated Delta Networks like Qwen3.5-0.8B.
Punching Above Its Weight Class
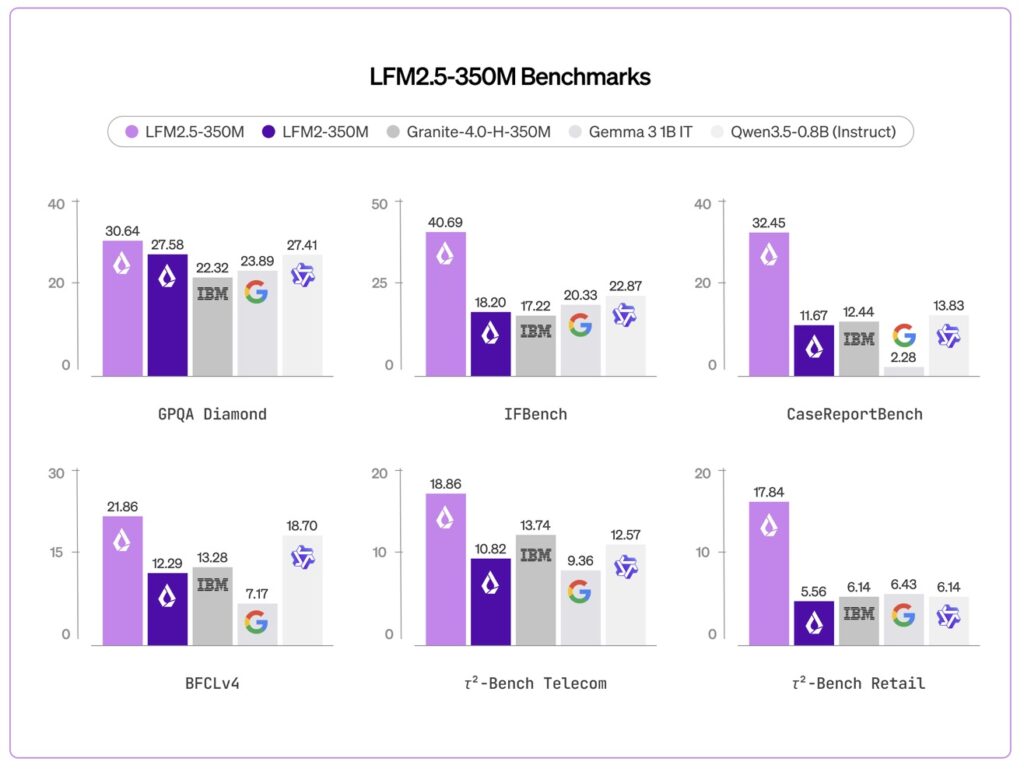
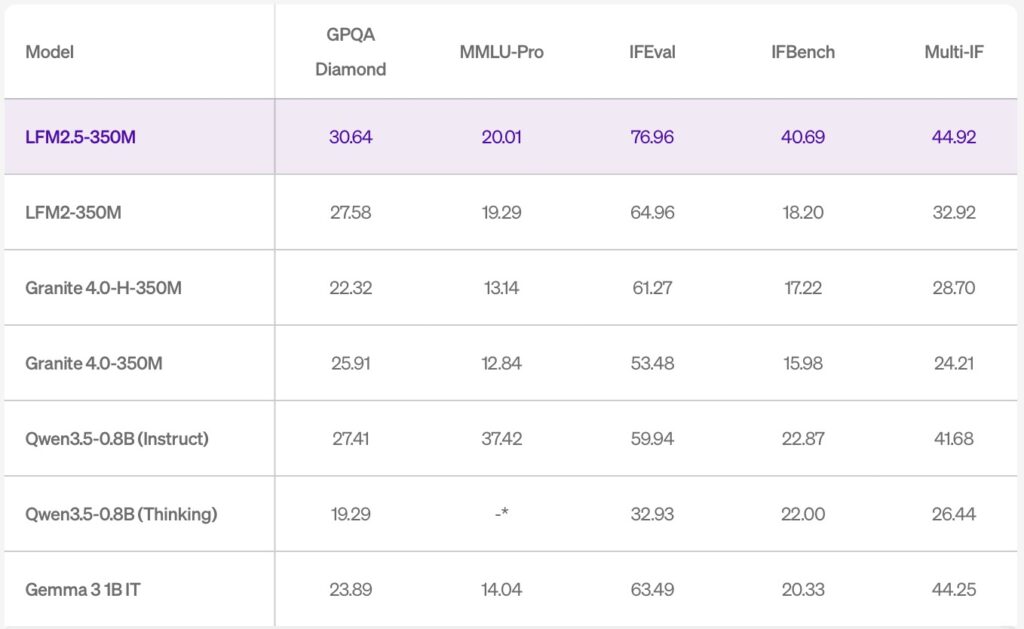
The true test of any compact model is how it handles complex instructions. Evaluated across ten rigorous benchmarks spanning core capabilities and applied tasks, LFM2.5-350M doesn’t just compete; it dominates. It actively outperforms models more than twice its size in foundational knowledge (GPQA Diamond, MMLU-Pro) and instruction following (IFEval, IFBench, Multi-IF).
When compared to the previous LFM2-350M model, the generational leap is undeniable:
- Instruction Following: Jumped from 18.20 to 40.69 (IFBench).
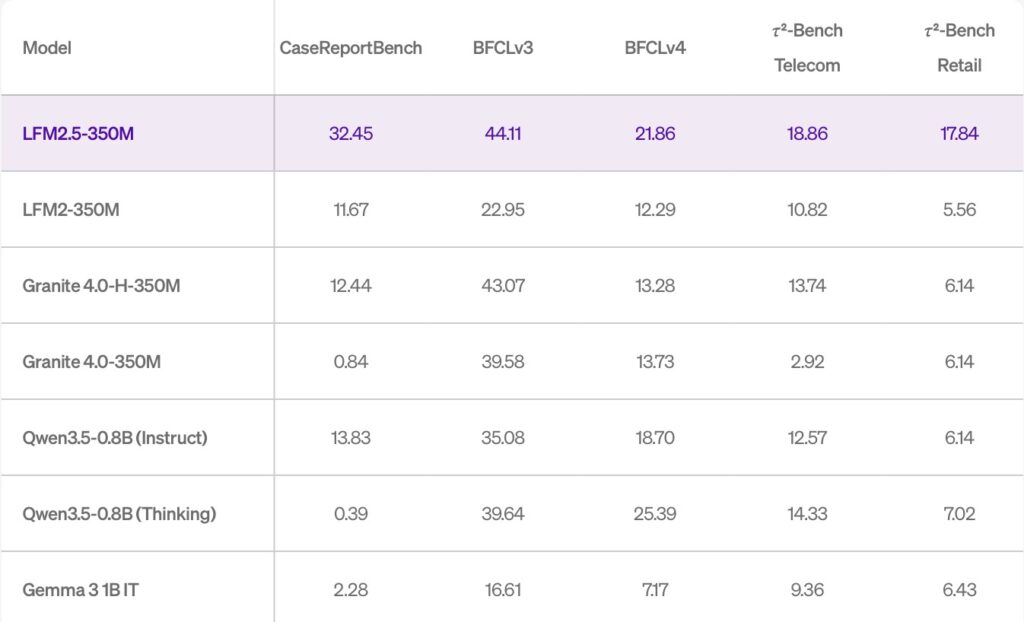
- Data Extraction: Surged from 11.67 to 32.45 (CaseReportBench).
- Tool Use: Improved from 22.95 to 44.11 (BFCLv3).
This makes it the ideal engine for large-scale data extraction pipelines or lightweight, on-device AI agents. It is worth noting, however, that the model is purpose-built for these specific workflows and is not recommended for heavy math, coding, or creative writing tasks.
Production-Ready Agentic Workflows
To ensure LFM2.5-350M was ready for the demands of real-world production, Liquid partnered with Distil Labs. By fine-tuning the model using just model traces, Distil Labs tested it on multi-turn interactions across smart home, banking, and terminal-based use cases. The results were highly impressive: the model achieved over 95% accuracy in tool-calling reliability throughout the dialogue. This proves that LFM2.5 is not just fast, but highly capable of managing the complex back-and-forth required for sophisticated AI agents.
A Rapidly Expanding Edge Ecosystem
To meet developers exactly where they are, Liquid is ensuring LFM2.5-350M runs seamlessly across preferred inference engines and hardware. The model ships with day-one support across a massive array of software, including LEAP (Liquid’s Edge AI Platform for iOS/Android), llama.cpp for GGUF checkpoints, MLX for Apple Silicon, vLLM and SGLang for GPU-accelerated serving, ONNX, and OpenVino.
Liquid has partnered with major silicon leaders to optimize performance across the board:
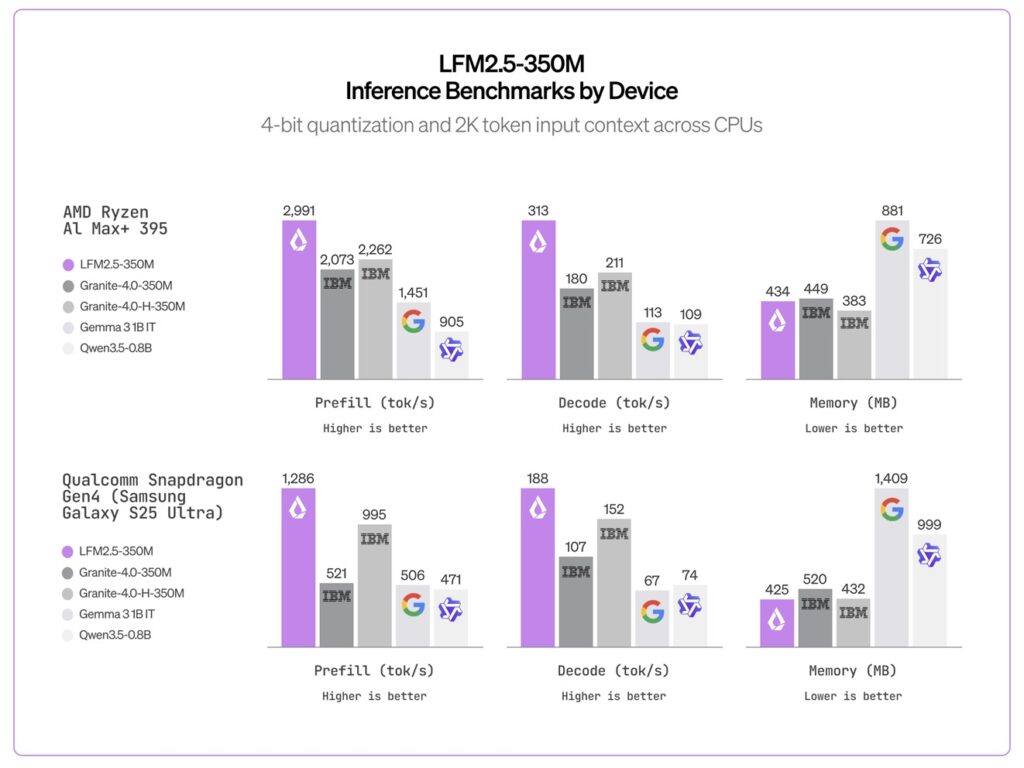
- AMD: Full optimization for Ryzen™ AI hardware, delivering a high-efficiency local experience (hitting 313 tokens/second decode on AMD CPUs).
- Qualcomm Technologies: Partnering with Zetic (Melange execution layer) and RunAnywhere to deliver Day 0 support for Snapdragon® devices, resulting in low-latency, low-memory execution on the Hexagon architecture (188 tokens/second on Snapdragon Gen4).
- Intel: Native OpenVINO optimization maximizes inference speeds and memory management across Intel-powered edge and AI PC environments.
- Apple Silicon: Powered by the Mirai engine, the model delivers blazing-fast inference from the mobile A18 Pro chip all the way to M5 Max processors.
- Constrained Edge: Cactus Compute heavily optimized RAM usage to run the model on sub-$300 devices, proving that the iPhone 13 Mini, Google Pixel 6a, and Raspberry Pi 5 can handle capable AI.
- Universal Deployment: LM Studio offers seamless integration via their headless daemon, llmster, making local deployment effortless.
The base (LFM2.5-350M-Base) and post-trained (LFM2.5-350M) models are officially live today. Developers can access them on Hugging Face, LEAP, and the Liquid Playground, proving definitively that when it comes to edge AI, no size is left behind.