From simple renders to strategic design, OpenAI’s newest model brings unprecedented precision, multilingual text rendering, and reasoning capabilities to AI image generation.
- Unmatched Precision and Text Rendering: ChatGPT Images 2.0 flawlessly integrates dense text, UI elements, and complex compositions, with massive leaps in non-Latin language support.
- The First Visual Thought Partner: Equipped with new “thinking” capabilities, the model can search the web, fact-check its own outputs, and generate up to eight continuous, distinct images in a single prompt.
- Built for Professional Workflows: With flexible aspect ratios, real-world intelligence, and seamless integration into Codex and the API, it transforms AI image generation from a novelty into a comprehensive visual system.
Images are a language, not mere decoration. A good image does exactly what a good sentence does—it selects, arranges, and reveals. It can elegantly explain a mechanism, set a distinct mood, test an abstract idea, or make a compelling argument. A year ago, the release of ChatGPT Images proved that AI-generated visuals could be both beautiful and useful. Today, ChatGPT Images 2.0 takes the next monumental step.
ChatGPT Images 2.0 is a state-of-the-art model engineered to take on complex visual tasks and produce precise, immediately usable assets. It represents a massive step change in detailed instruction following, spatial relationship accuracy, and dense text rendering. Its refined sense of composition and visual taste ensures that results feel less “AI-generated” and more intentionally designed. By utilizing expanded visual and world knowledge, the model intelligently fills in the gaps, delivering smarter images with significantly less prompting required.

Greater Precision and Control
Images 2.0 brings an unprecedented level of specificity and fidelity to the creation process. It doesn’t just conceptualize sophisticated images; it brings those visions to life by rigorously following instructions and preserving requested details. It easily renders fine-grained elements that traditionally break image models, such as small text, iconography, user interface elements, and subtle stylistic constraints.
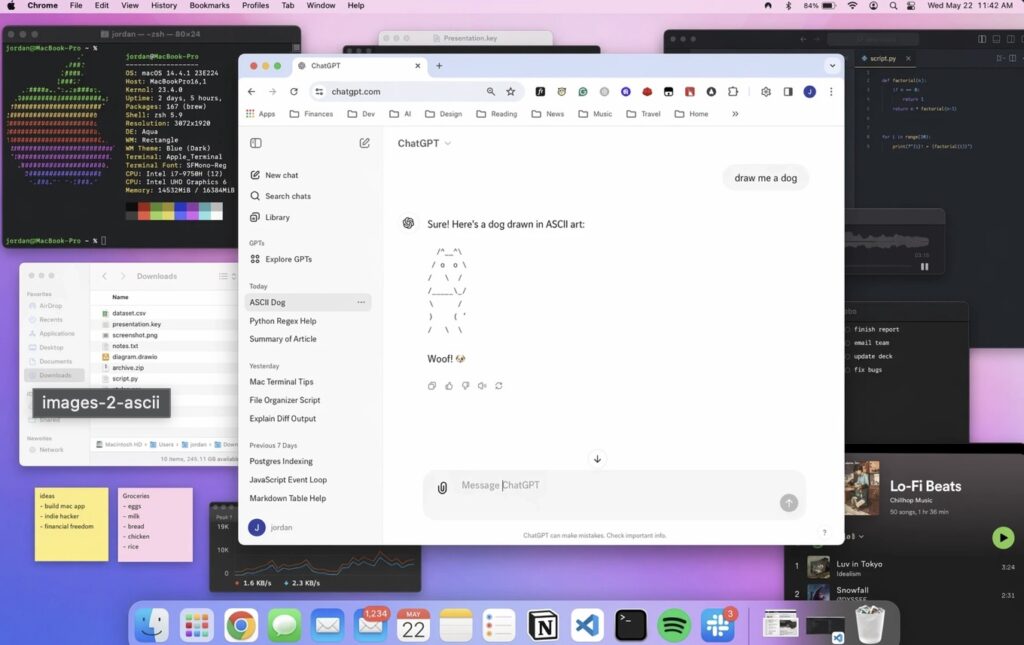
Instead of receiving something only vaguely resembling your request, you get a usable asset. For instance, if you request a macOS browser screenshot of ChatGPT drawing an ASCII dog, set against a cluttered desktop background filled with terminal windows, the model executes the complex layering and specific UI details flawlessly.

Breaking the Language Barrier
Historically, image generation models have been highly reliable in English and other Latin-script languages, but stumbled when tasked with non-Latin text or dense typography. Images 2.0 shatters this barrier with robust multilingual understanding and significant gains in generating text for Japanese, Korean, Chinese, Hindi, and Bengali.
The model goes beyond simply translating a label; it generates visually coherent outputs where language acts as a core part of the design. You can now prompt the model to create a dramatic, colorized Japanese shonen manga page about a character finding the magical “Quill of GPT Image.” The model will carefully split the panels, render the OpenAI logo on the pen, format the page to look like a physical photograph in a 1440×2560 portrait ratio, and most importantly, populate the story with perfectly flowing Japanese text.

Stylistic Sophistication and Realism
Whether you are game prototyping, storyboarding, or developing marketing creative, stylistic fidelity is paramount. Images 2.0 captures the defining characteristics of distinctive visual languages—including the tiny, beautiful flaws that add realism to photography.
You can request a photorealistic candid of a person standing by a coastal road on an overcast morning, shot on 35mm film, and the model will deliver natural imperfect framing, visible grain, and the feeling of a lived-in documentary photograph. Alternatively, ask for a snapshot of friends outside a nightclub, and it will render the crisp foreground detail, deep shadow falloff, and slightly raw spontaneous energy unmistakable to an early-2000s compact point-and-shoot camera with a direct flash.

Flexible Formats and Real-World Intelligence
To meet modern design needs, Images 2.0 introduces highly flexible aspect ratios, supporting everything from ultra-wide 3:1 panoramas to tall 1:3 vertical banners. If you need a “Japanese-manga-style disassembly” of a basketball dunk told purely through visuals in a 3:1 ultrawide ratio, the model adapts effortlessly. You can simply specify your desired dimensions in the prompt or use preset options to regenerate existing images.
Furthermore, the model operates with an updated knowledge cutoff of December 2025. This real-world intelligence is crucial for educational graphics, visual summaries, and explainers where correctness is just as vital as aesthetics. It expertly handles end-to-end tasks, synthesizing up-to-date information, writing the narrative, and laying it out with intentional whitespace and clean visual flow.
A True Visual Thought Partner
To tackle the most complex challenges, Images 2.0 is OpenAI’s first image model equipped with thinking capabilities. When a thinking or pro model is selected in ChatGPT, the AI acts agentically behind the scenes. It can search the web for real-time information, transform uploaded documents into visual explainers, and logically reason through an image’s structure before rendering.
In this mode, the model functions as a visual thought partner. It can even generate up to eight distinct images at once. This unlocks entirely new workflows: you can ask for a sequence of manga pages, a family of poster concepts, or a multi-platform social media campaign. For example, you can prompt an advertisement for a new Brooklyn Heights matcha shop called “Kizuki,” requesting a streetwear aesthetic and multiple aspect ratios for Twitter, Instagram Stories, and LinkedIn. The model delivers a cohesive suite of assets with perfect continuity, saving hours of manual stitching and iteration.
Empowering Developers and Businesses
This visual revolution extends seamlessly into professional workspaces. In Codex, Images 2.0 allows users to generate multiple UI directions, compare prototypes, and turn ideas into live products without ever leaving the app.
For developers and businesses, these capabilities are available via the API through gpt-image-2. With support for up to 2K resolution (currently in beta), businesses can build high-quality image generation into their own workflows, ranging from localized advertising and educational content to creative platforms. A fashion brand, for instance, can programmatically generate premium, luxury-style advertisements for a new makeup glow lip balm, perfectly tailored and styled for a trendy Gen Z demographic.
Understanding the Limitations
While ChatGPT Images 2.0 is a massive leap forward, important frontiers remain. The model can still struggle with tasks requiring a flawless physical world model—such as complex origami folding guides or solving spatial puzzles like Rubik’s Cubes. Fine, repetitive details (like grains of sand) or intricate diagrams requiring precise arrow placements may still require human review. Additionally, API outputs over 2K resolution may occasionally produce inconsistent results while in beta.
The Future of Visual Systems
ChatGPT Images 2.0 is available starting today for all ChatGPT and Codex users, with advanced thinking outputs reserved for Plus, Pro, and Business tiers. The gpt-image-2 model is also live in the API, with pricing tiered by quality and resolution.
By combining the intelligence of OpenAI’s reasoning models with a vast understanding of the visual world, ChatGPT Images 2.0 successfully transitions AI image generation from a simple rendering tool into a comprehensive strategic design system. It is built to be useful, creative, and safe, helping users globally turn their boldest ideas into assets they can share, teach with, and build upon.