Harnessing speculative decoding to deliver up to 3x faster performance across edge devices and local workstations—without sacrificing a drop of intelligence.
- Massive Speed Gains: By utilizing a specialized speculative decoding architecture, the newly released Multi-Token Prediction (MTP) drafters accelerate Gemma 4 inference by up to 3x, directly targeting the memory-bandwidth bottleneck.
- Uncompromised Quality: The innovative system separates token prediction from final verification, ensuring developers receive lightning-fast generation while retaining the exact same frontier-class reasoning and accuracy.
- Universal Deployment: Whether supercharging complex coding workflows on consumer GPUs or preserving battery life on edge devices, these open-source drafters are available today across major platforms and frameworks.
Just a few short weeks ago, the AI community welcomed Gemma 4, our most capable suite of open models to date. The response was staggering, with over 60 million downloads occurring in the first few weeks alone. This rapid adoption was fueled by Gemma 4’s ability to deliver unprecedented intelligence-per-parameter directly to developer workstations, mobile devices, and the cloud. However, raw intelligence is only half the battle in modern AI deployment. Today, we are pushing the boundaries of efficiency even further by releasing Multi-Token Prediction (MTP) drafters for the entire Gemma 4 family.

The driving force behind this update is a fundamental technical reality: standard large language model (LLM) inference is severely bound by memory bandwidth. In traditional setups, a processor spends the vast majority of its time simply shuffling billions of parameters from VRAM to compute units just to generate a single token. This paradigm leads to vastly under-utilized compute power and frustratingly high latency, particularly on consumer-grade hardware. Standard models generate text autoregressively, meaning they painstakingly produce exactly one token at a time. This process is inherently inefficient because it dedicates the exact same amount of heavy computation to predicting an obvious continuation—such as guessing the word “words” after the phrase “Actions speak louder than…”—as it does to untangling a highly complex logic puzzle.
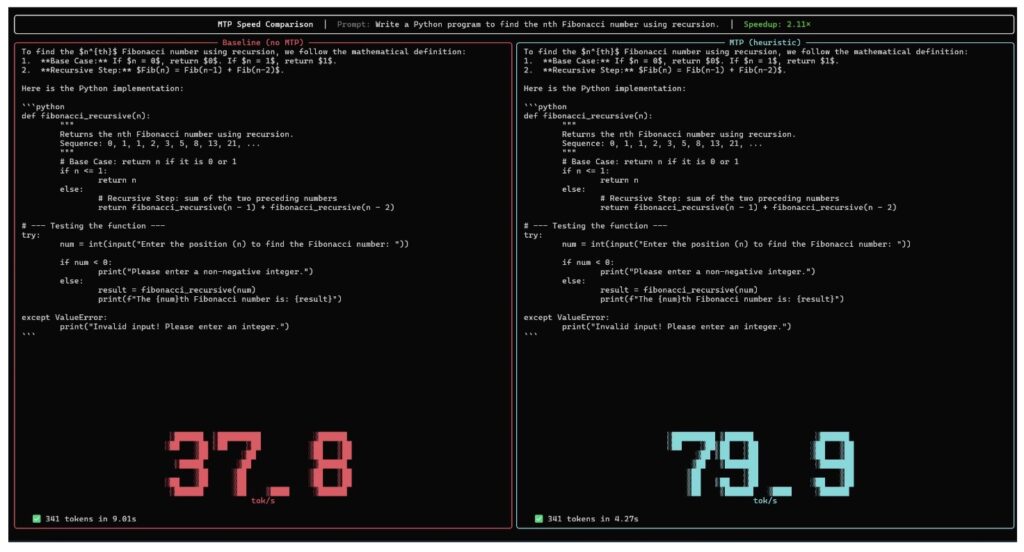
To shatter this latency bottleneck, we turned to a technique pioneered by Google researchers: speculative decoding. MTP mitigates traditional inefficiencies by fundamentally decoupling the generation of tokens from their verification. The architecture pairs a heavy target model, such as the powerful Gemma 4 31B, with a highly lightweight drafter, known as the MTP model. Because the primary processor compute is often idling while waiting for memory transfers, the nimble drafter steps in to “predict” several future tokens at once. It accomplishes this in less time than it takes the massive target model to process just a single token. The target model then receives these drafted suggestions and verifies all of them simultaneously in parallel. If the target model agrees with the draft, it accepts the entire sequence in a single, highly efficient forward pass, and even generates an additional token of its own during the process. Ultimately, your application can output a full sequence of text plus an extra token in the exact same time it usually takes to generate just one.
For developers, this breakthrough translates to unlocking vastly faster AI from the edge all the way to the workstation. Inference speed is frequently the primary hurdle for production deployment, and when building near real-time chat applications, immersive voice agents, or autonomous workflows that require rapid multi-step planning, every millisecond counts. By simply pairing a Gemma 4 model with its corresponding drafter, developers instantly achieve improved responsiveness. Furthermore, it supercharges local development, allowing robust models like our 26B mixture-of-experts (MoE) and 31B Dense models to run seamlessly on personal computers and consumer GPUs. On mobile platforms, it maximizes the utility of our E2B and E4B edge models by generating outputs significantly faster, which dramatically reduces compute time and preserves valuable battery life. Crucially, this all comes with zero quality degradation. Because the primary Gemma 4 model retains absolute authority over the final verification, the output maintains identical logic and accuracy, just delivered at breakneck speeds.
To make these MTP drafters exceptionally fast and highly accurate, we engineered several sophisticated architectural enhancements under the hood. The draft models are designed to seamlessly utilize the target model’s activations and share its KV cache. This shared architecture means the drafter doesn’t waste precious milliseconds recalculating context that the larger model has already figured out. For our smaller E2B and E4B edge models, where the final logit calculation typically emerges as a major bottleneck, we implemented a highly efficient clustering technique within the embedder to accelerate generation even further.
We have also rigorously analyzed and applied hardware-specific optimizations to ensure these gains translate to the real world. For instance, while the complex routing of the 26B MoE model presents unique challenges at a batch size of 1 on Apple Silicon, increasing the batch size to process multiple requests simultaneously—such as sizes of 4 to 8—unlocks up to a ~2.2x speedup locally. We have observed similar, highly scalable gains on Nvidia A100 setups when leveraging increased batch sizes. For those eager to dive into the exact visual architecture, KV cache sharing mechanics, and efficient embedders powering this technology, our newly published in-depth technical explainer unpacks every detail.
The MTP drafters for the Gemma 4 family are ready for deployment today, released under the exact same open-source Apache 2.0 license as the base models. Developers can read the official documentation to seamlessly integrate MTP with Gemma 4, and the model weights are available right now for download on Hugging Face and Kaggle. Whether you want to experiment using popular frameworks like Transformers, MLX, VLLM, SGLang, and Ollama, or try them directly on the Google AI Edge Gallery for Android and iOS, the tools to build faster, more efficient AI are entirely in your hands.