A deep dive into the “Prejudice Gap” in Multimodal Large Language Models and why getting the right answer doesn’t mean reasoning for the right reason.
- The Illusion of Understanding: As AI enters high-stakes human roles like interview screening and mental health triage, new research reveals that Multimodal Large Language Models (MLLMs) often rely on superficial pattern matching rather than genuine behavioral understanding to judge personality.
- The “Prejudice Gap” Exposed: Using a novel dataset called MM-OCEAN, researchers discovered that 51% of an AI’s correct personality ratings are essentially lucky guesses lacking any grounded evidence in the subject’s actual behavior.
- A Roadmap for Trustworthy AI: To build reliable social AI, the industry must abandon traditional rating-only evaluations and prioritize Grounded Personality Reasoning (GPR), forcing models to anchor their psychological judgments in observable, real-world cues.
We are standing on the edge of a new era in artificial intelligence. Multimodal Large Language Models (MLLMs) are no longer confined to generating text; they are rapidly entering high-stakes, human-centric applications. Today, AI-powered systems are screening job applicants, triaging mental health patients through facial and vocal cues, adapting to users via companion digital humans, and driving intelligent non-player characters (NPCs) in gaming.
At the core of all these technologies is a shared, deeply complex requirement: personality perception. For an AI to interact naturally with a human, it must infer stable psychological traits from observable behavior, typically targeting the widely accepted Big Five (OCEAN) personality model.
But a critical question remains: how well do current MLLMs actually understand the people they are observing?
The Problem with “Guessing Right”
Historically, we have measured an AI’s ability to read people through Apparent Personality Recognition (APR) benchmarks, such as ChaLearn First Impressions. These traditional evaluations frame the task as a simple math problem: numerical regression on Big Five trait scores.
However, this formulation has a massive blind spot. It cannot distinguish a model that genuinely understands human behavior from one that merely exploits superficial correlations. For instance, a model might notice a smiling face and automatically predict “high agreeableness.” If it gets the score right, traditional benchmarks reward it. But this is the equivalent of getting the right answer for the wrong reason. It is not social cognition; it is prejudice fueled by pattern matching.
Introducing Grounded Personality Reasoning (GPR)
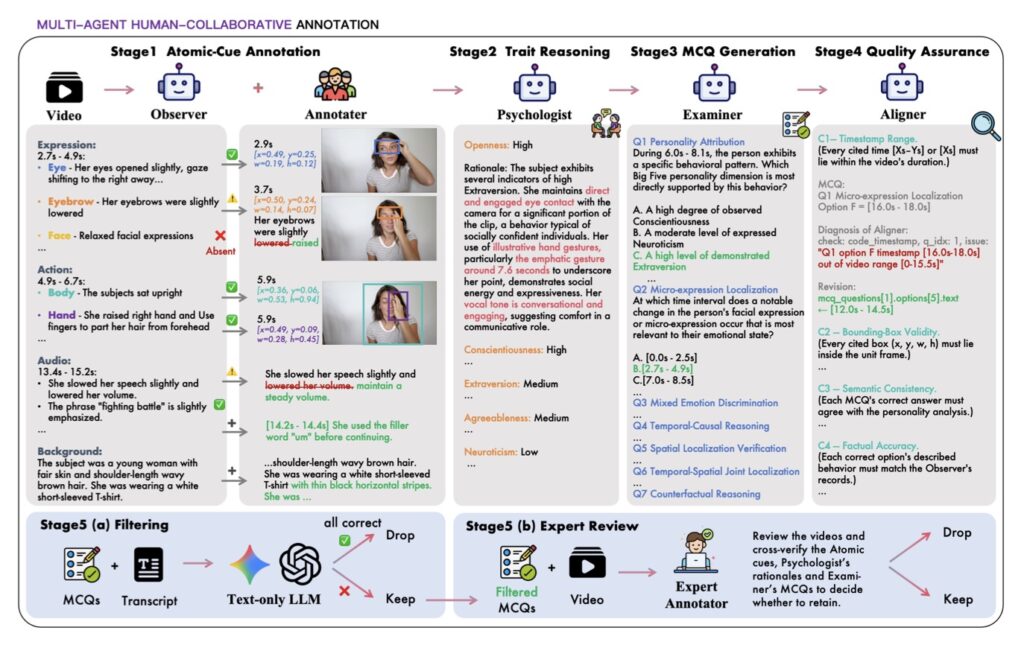
To address this glaring gap, researchers have formalized a new task called Grounded Personality Reasoning (GPR). Instead of just spitting out a score, GPR requires MLLMs to anchor every single Big Five rating in observable, irrefutable evidence through a strict chain of rating, reasoning, and grounding.
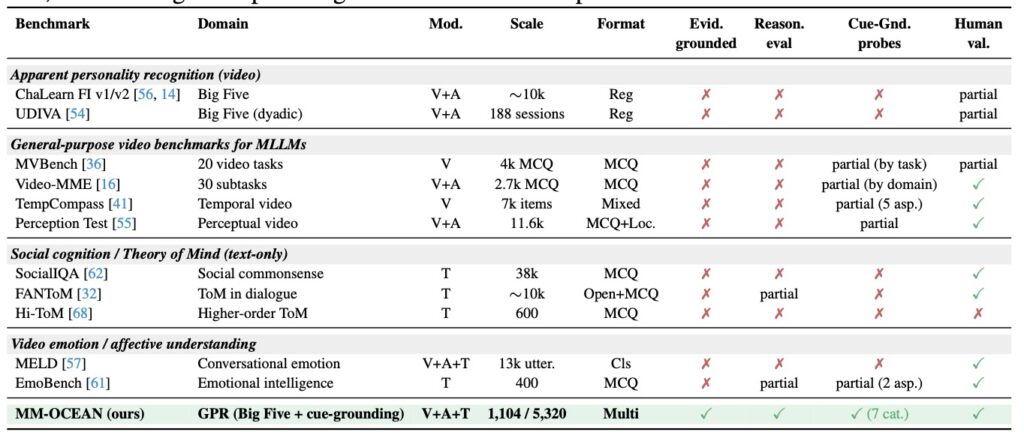
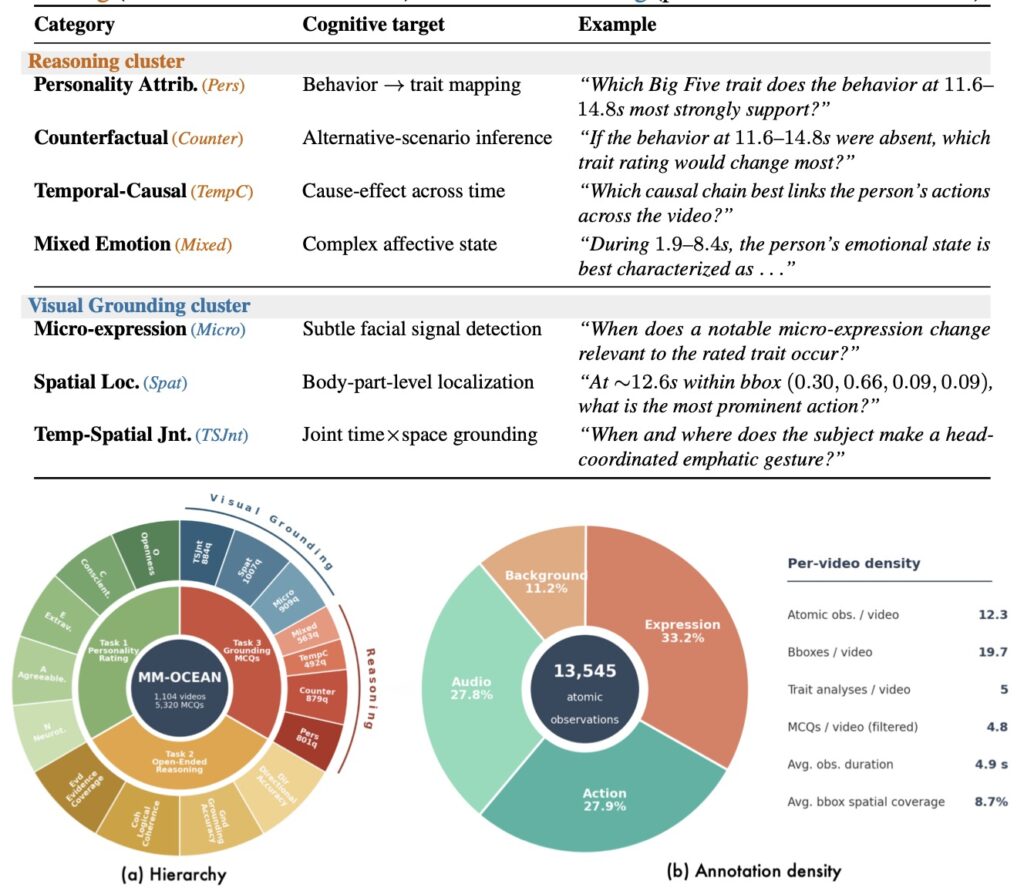
To test this, the researchers released MM-OCEAN, a multi-granularity benchmark dataset produced via a sophisticated multi-agent pipeline with human verification. MM-OCEAN is comprehensive, featuring:
- 1,104 video clips
- 5,320 multiple-choice questions (MCQs)
- Timestamped behavioral observations
- Evidence-grounded trait analyses
- Seven distinct categories of cue-grounding MCQs
Uncovering the Prejudice Gap
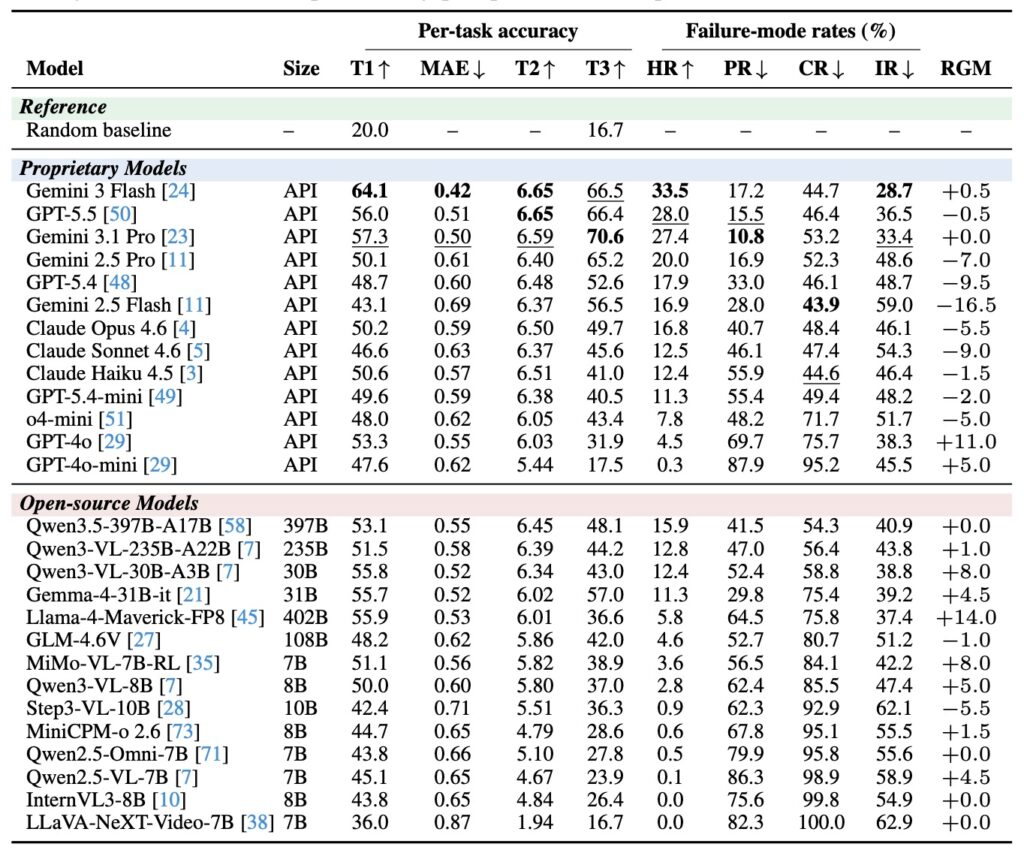
By running 27 different MLLMs (13 closed, 14 open-source) through a rigorous three-tier evaluation—assessing their rating, reasoning, and grounding capabilities—researchers unearthed a deeply concerning reality across the AI landscape.
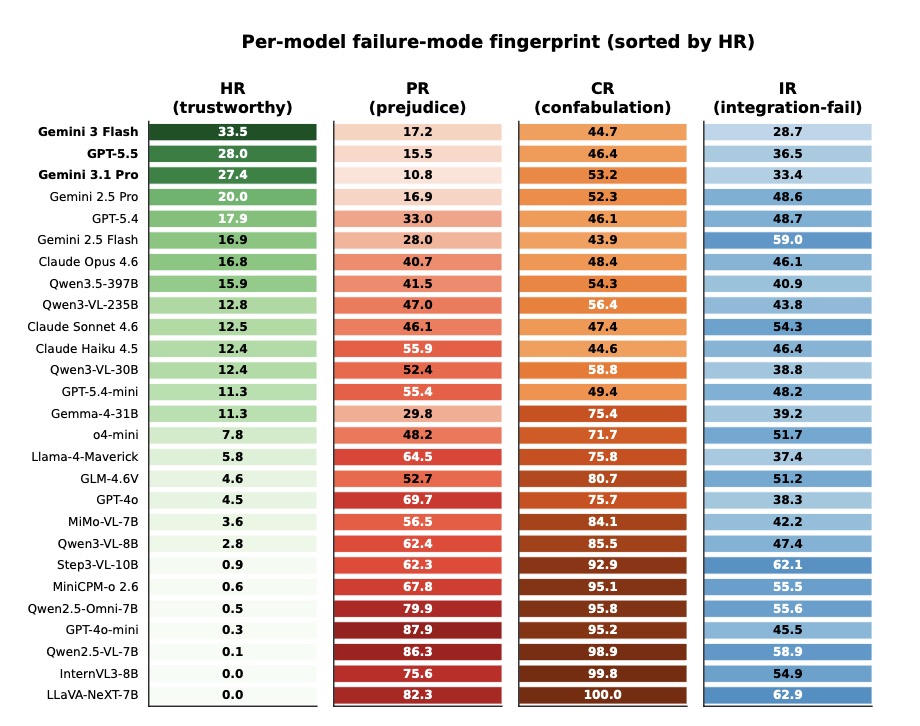
The analysis introduced four sample-level failure-mode metrics to diagnose exactly where the models fall short: Prejudice Rate (PR), Confabulation Rate (CR), Integration-failure Rate (IR), and Holistic-grounding Rate (HR).
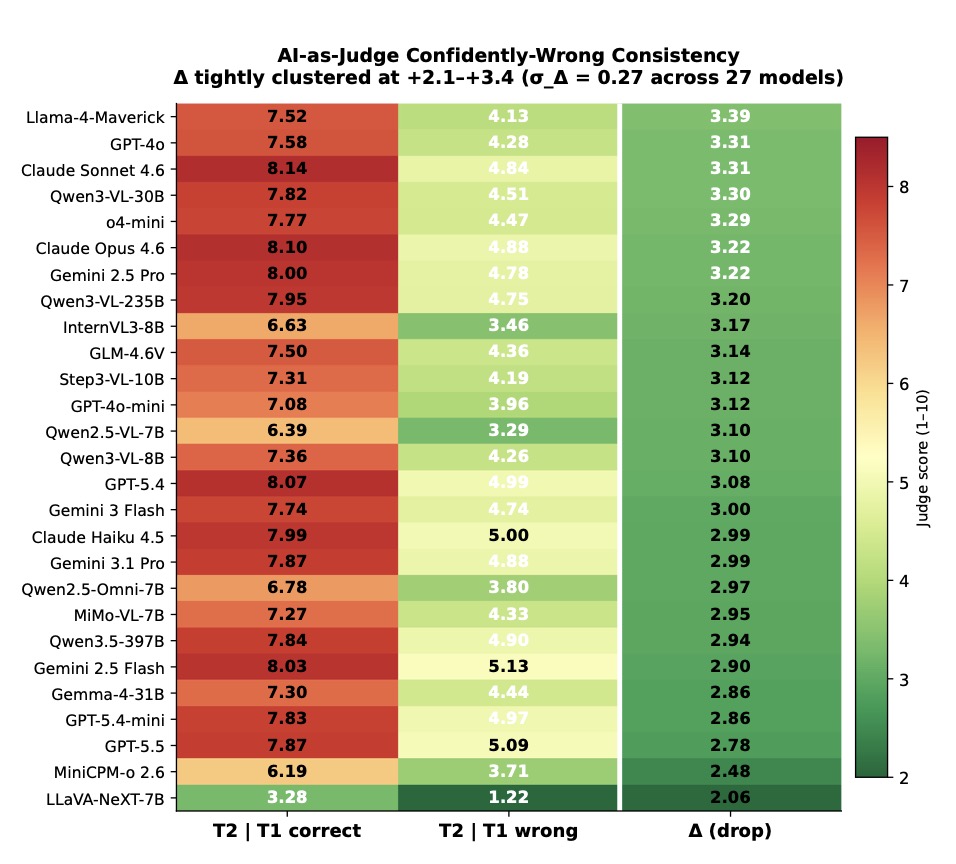
The results exposed a striking Prejudice Gap. Across the entire field of tested models, a staggering 51% of correct personality ratings were completely ungrounded in retrieved visual or audio cues. Furthermore, the mean Holistic-Grounding Rate (HR) sat at a dismal 10.4%, with the absolute best models only achieving between 0% and 33.5%.
These numbers paint a clear picture: traditional, rating-only evaluations are systematically overestimating AI competence. They are crediting ungrounded predictions and masking the fact that models are frequently relying on bias over observation.
Interestingly, while proprietary and open-source models perform similarly when it comes to basic rating and explanation (with a difference of less than 6%), there is a massive 26.6% gap in actual cue retrieval. The highly discriminative HR metric proves that reasoning-intensive models are leading the pack, but even they have a long way to go.
Charting the Future of Social Cognition in AI
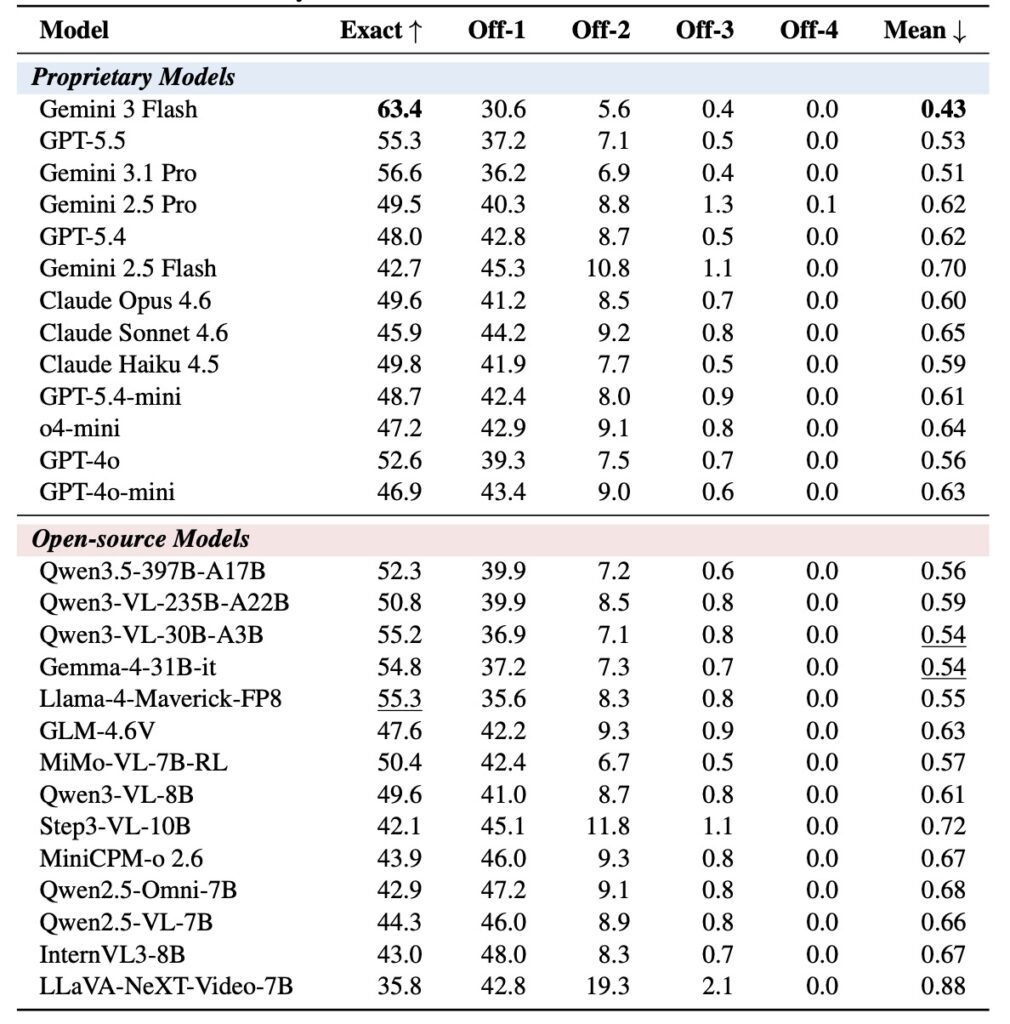
The findings from MM-OCEAN serve as a vital wake-up call for AI developers. If we are going to deploy MLLMs in sensitive, human-facing roles, prioritizing fine-grained spatiotemporal grounding during post-training is no longer optional—it is essential for building trustworthy systems.
While MM-OCEAN is a massive leap forward, it is only the beginning. Currently, the dataset focuses on apparent personality from short, single-speaker English video clips. Moving forward, the industry must expand these benchmarks to include cross-cultural and multilingual contexts, employ multi-judge AI ensembles for enhanced reliability, and develop even richer operationalizations of evidence beyond MCQ-based retrieval.
The goal is not to build models that can superficially judge us. The goal is to cultivate an artificial intelligence that genuinely understands the complex, behavioral tapestry of human personality. By closing the Prejudice Gap, we take a vital step toward AI systems that see us for who we truly are.