How a revolutionary diffusion framework is breaking the rigid boundaries of AI-generated expressions, enabling subtle, continuous, and identity-preserving portrait manipulation.
- The Problem with Current AI: Existing diffusion models struggle to generate subtle, overlapping facial expressions (like fear versus surprise) because they rely on rigid, discrete emotion categories, often resulting in altered facial identities and structural confusion.
- The PixelSmile Solution: Powered by the new Flex Facial Expression (FFE) dataset, the PixelSmile framework shifts AI from discrete emotional boundaries to a continuous emotional spectrum using a novel symmetric joint training approach.
- The Result: By combining intensity supervision with contrastive learning, PixelSmile achieves unprecedented linear control over expression intensity, allowing for smooth emotion blending and pinpoint accuracy while perfectly preserving the subject’s original identity.
The landscape of digital art and photography has been radically transformed by recent advances in diffusion-based image editing models and identity-consistent generation techniques. Today, manipulating a personal portrait using simple natural language prompts is easier than ever. Yet, despite these monumental leaps forward, one incredibly nuanced challenge has remained stubbornly difficult for artificial intelligence to master: fine-grained facial expression editing.



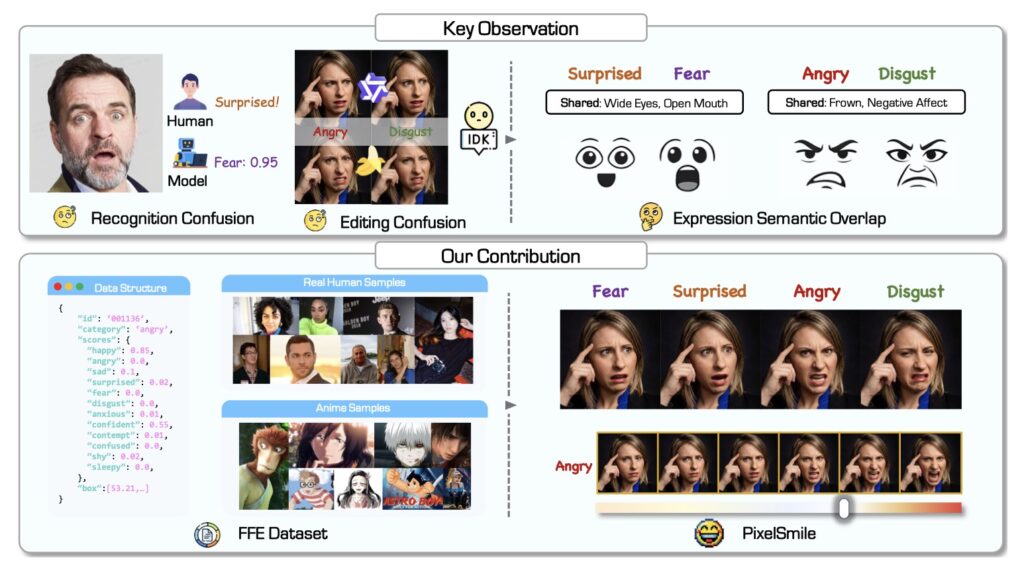
The human face is a canvas of infinite, continuous emotional micro-shifts. While current AI models can easily distinguish and generate broad, distinct expressions—such as a joyful smile versus a deep frown—they heavily struggle when asked to delineate highly correlated, semantically overlapping emotions. When tasked with editing a face to show fear rather than surprise, or anger instead of disgust, standard image generators frequently stumble. This intrinsic semantic overlap leads to structural cross-category confusion, ultimately degrading the quality of the image.
The root of this problem lies in how AI has historically been taught to understand emotion. Most existing methods rely on discrete expression categories. They force the inherently continuous and fluid spectrum of human expressions into rigid, pre-defined class boundaries. Because of this structural limitation, these models fail to capture subtle expression thresholds. As a result, users experience limited control over expression intensity, and the subject’s core identity often warp or shifts entirely during the editing process.
To solve this semantic entanglement, researchers have introduced PixelSmile, a groundbreaking diffusion framework that approaches facial expression editing from a fundamentally different angle. Instead of relying on discrete, boxed-in supervision, PixelSmile shifts the paradigm toward a continuous expression manifold.
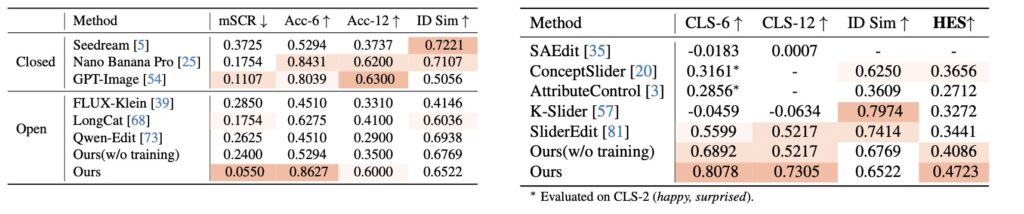
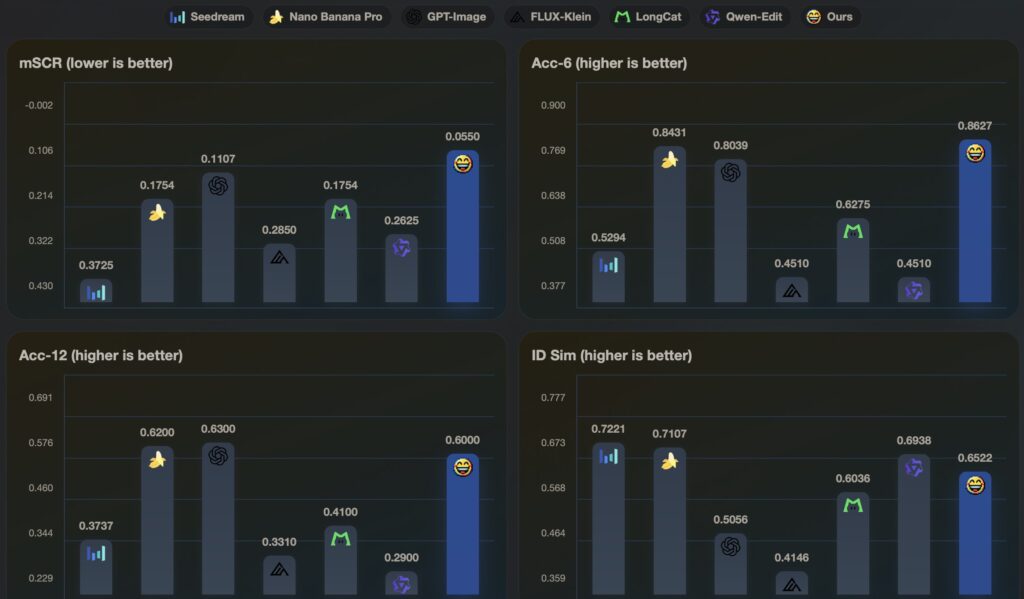
This innovation is built upon the foundation of the newly constructed Flex Facial Expression (FFE) dataset, which is equipped with continuous affective annotations. To ensure the framework’s reliability, the creators also established FFE-Bench, a rigorous evaluation system designed to test models across four critical dimensions: structural confusion, overall editing accuracy, linear controllability, and the delicate trade-off between effectively editing an expression and preserving the subject’s identity.
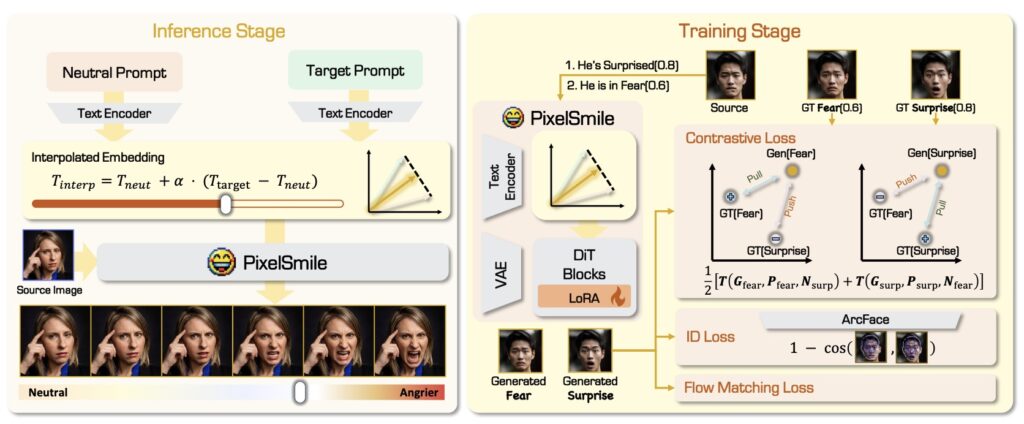
PixelSmile stands out by disentangling expression semantics through a process called fully symmetric joint training. The framework ingeniously combines intensity supervision with contrastive learning. By doing so, it produces expressions that are not only stronger but vastly more distinguishable from one another. This allows the AI to finally understand the minute differences between an angry scowl and a disgusted grimace.
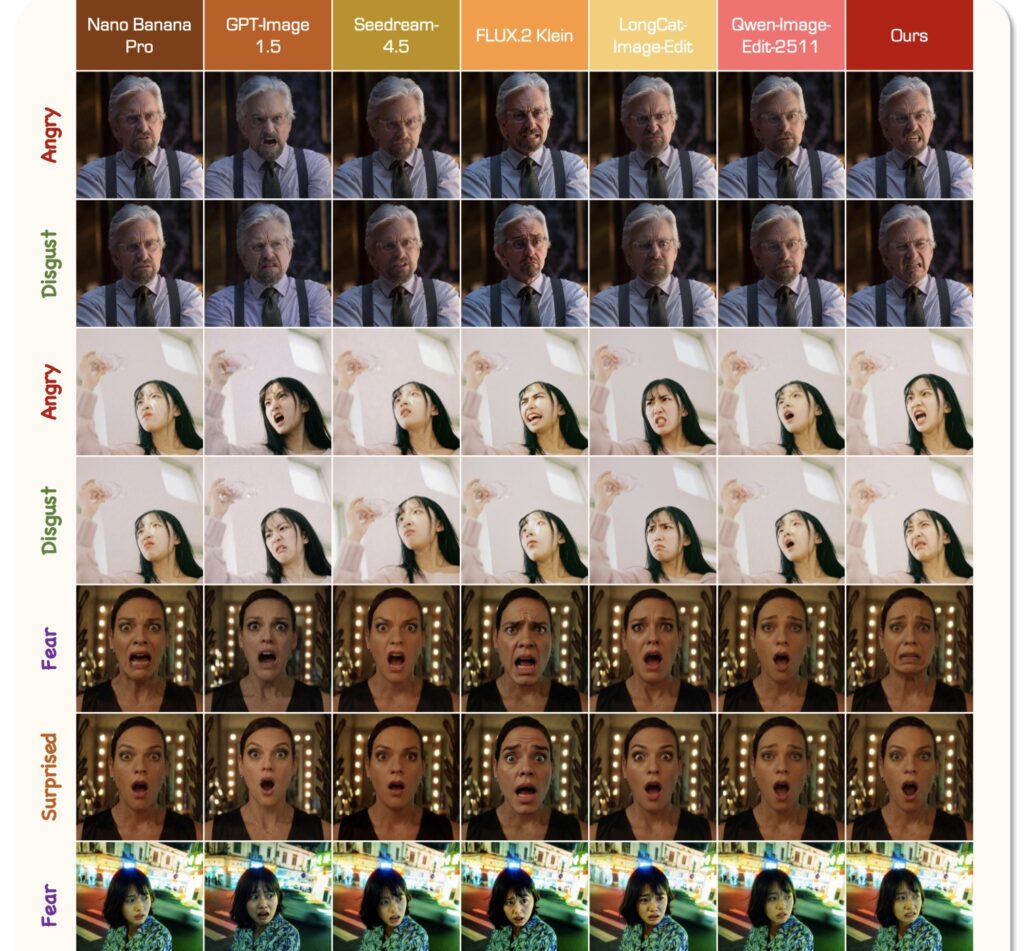
Furthermore, PixelSmile introduces an unprecedented level of control through textual latent interpolation. In practical terms, this means users can achieve precise and stable linear control over an expression. You are no longer limited to choosing between “not smiling” and “grinning”; you can smoothly dial the intensity of a smile up or down along a continuous slider. Extensive experiments on FFE-Bench have demonstrated that PixelSmile achieves superior disentanglement and robust identity preservation, effectively putting an end to the days of AI losing a subject’s likeness just to change their mood.


PixelSmile establishes a much-needed standardized framework for fine-grained facial expression editing. By moving away from rigid emotional categories and embracing the continuous, fluid nature of human affect, it naturally supports smooth expression blending and compositional manipulation. It is a major step forward, not just for image editing, but for capturing the true, nuanced essence of human emotion through artificial intelligence.