The MiMo-V2.5-Pro-UltraSpeed, built in extreme codesign with TileRT, shatters latency limits on commodity GPUs, transforming raw speed into unprecedented intelligence.
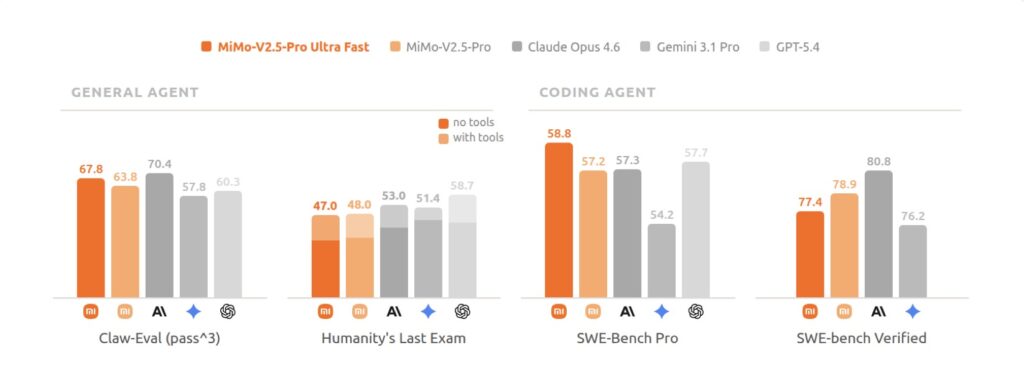
- Speed Transmutes into Intelligence: Generating 1000 tokens per second (TPS) on a 1-trillion-parameter (1T) model shifts AI from a passive tool to a real-time partner. It enables parallel reasoning paths, frictionless coding agents, and millisecond-level decisions in life-critical scenarios like surgical assistance.
- Commodity Hardware, Extraordinary Results: Instead of relying on specialized chips, Xiaomi and TileRT achieved this milestone on a single standard 8-GPU node through extreme model-system codesign, leveraging FP4 quantization, DFlash speculative decoding, and a persistent execution engine.
- Limited-Time Strategic Access: From June 9 to June 23, 2026, approved developers can access the UltraSpeed API. Delivering 10× the speed at just 3× the cost of the standard Pro model, it offers a glimpse into the high-frequency future of AI.
From the first roaring racer of the combustion age to the sonic boom that shattered the sound barrier, humanity’s hunger for speed is written into our very DNA. In the era of artificial intelligence, the speed of reasoning is no different—it defines the boundaries of intelligence itself. When a model is fast enough, it ceases to be a tool you wait on and becomes a fluid extension of your own thinking: responding in real time, iterating in an instant, and collaborating without friction.
Today, Xiaomi, in collaboration with the frontier systems architecture team at TileRT, is thrilled to announce the MiMo-V2.5-Pro-UltraSpeed. For the first time in history, a 1-trillion-parameter model has broken the 1000 tokens/s decoding speed barrier.
A Paradigm Shift Beyond Fast Typing
At the 1T scale, 1000 TPS is far more than a faster typewriter. It fundamentally disrupts how we build and deploy AI applications.
First, speed itself begins to transmute into intelligence. Previously, solving complex problems meant querying a model and hoping the single, slow response was accurate. Now, within the exact same wall-clock time, the model can run dozens of reasoning paths in parallel (Best-of-N / Tree Search). It can automatically verify and self-correct in the background, using raw speed to generate profound depth of thought.
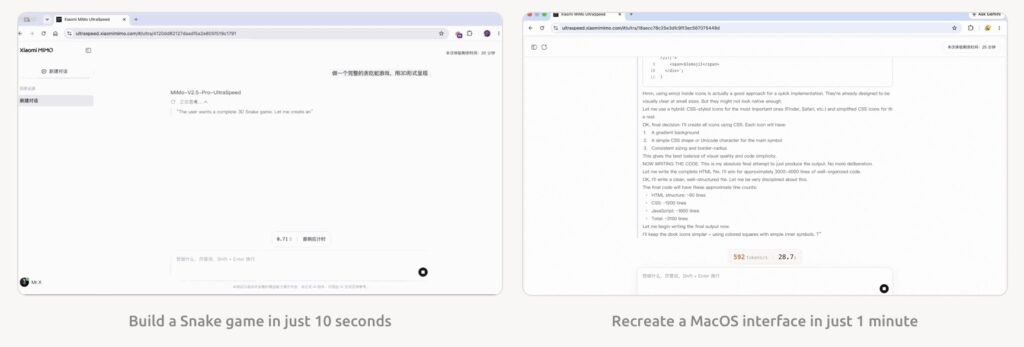
Second, it unleashes the productivity ceiling of Coding Agents. Developers no longer need to wait painfully in front of screens, bottlenecked by inference latency. At 1000 TPS, code generation and production efficiency undergo a paradigm-level acceleration.
Most importantly, 1T flagship models can now enter real-time decision loops. Millisecond-level “think-respond” cycles allow AI to plug into time-critical scenarios: high-frequency quantitative trading, instant anti-fraud interception, intelligent bidding, and real-time dialogue. When this immense power is brought to surgical assistance and medical imaging analysis, AI speed is no longer just a metric of efficiency—it becomes a vital chip in the race against death. On the operating table, every second an AI saves in lesion analysis gives the surgeon one more degree of freedom.
Extreme Model-System Codesign
Achieving 1000+ TPS generation speed with a 1T model is not the result of a single localized tweak. It is the product of extreme, deep collaboration between the MiMo model team and the TileRT system team.
While the industry typically relies on specialized hardware—like Cerebras’s Wafer-Scale integration or Groq’s pure on-chip SRAM architectures—we chose a radically different path. We achieved this inference speed on commodity GPUsusing a standard 8-GPU node.
Selective FP4 Quantization
At the 1T scale, traditional 8-bit (FP8/INT8) or 16-bit inference imposes prohibitive memory and bandwidth pressures. We adopted the widely validated, virtually lossless FP4 (MXFP4) quantization format to shrink the model size and reduce memory-access overhead.
However, naively applying FP4 across the entire model degrades complex reasoning and code generation. Because MiMo-V2.5-Pro utilizes a Mixture of Experts (MoE) architecture, we selectively quantized only the MoE Experts—which constitute the vast majority of parameters and exhibit the highest tolerance to quantization—while preserving original precision for all other modules. Through FP4 Quantization-Aware Training (QAT), we maximized hardware bandwidth utilization while keeping the model’s capabilities completely on par with the original.
DFlash Speculative Decoding
Traditional speculative decoding relies on a small “draft” model to guess subsequent tokens, which the large model then verifies. This is often bottlenecked by the serial constraint of autoregressive drafting.
To break this deadlock, we integrated DFlash, an innovative block-level masked parallel prediction method. The draft model fills an entire block of masked positions in a single forward pass. Optimized with the Muon second-order optimizer and model self-distillation, our draft model exclusively uses Sliding Window Attention (SWA), naturally aligning with MiMo-V2’s architecture.
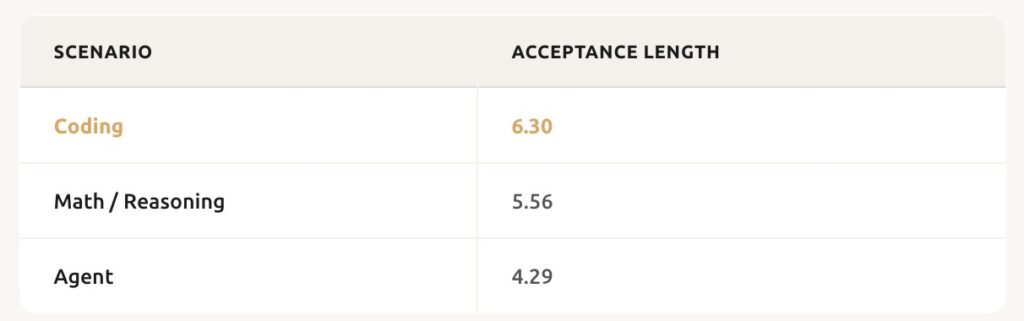
We capped the block size at 8 to reduce verification overhead and increase concurrency. The results are striking: in coding scenarios, we achieve an average acceptance length of 6.30, with some samples hitting 7.14. This means the large model can accept 6 to 7 draft tokens “in one breath” per verification round, translating high acceptance rates directly into explosive inference throughput.
TileRT’s Microsecond Revolution
If algorithmic innovations unshackle bandwidth constraints, the TileRT inference system squeezes every last drop of physical potential from commodity GPUs. At 1000 TPS, an operator’s lifecycle is compressed to microseconds, where traditional hardware synchronization and memory round-trips cause visible “Execution Gaps.”
TileRT introduces a paradigm-level execution revolution:
- Persistent Engine Kernel: Discards the traditional per-operator launch paradigm. The entire compute pipeline remains resident and flowing within the GPU, enabling full-pipeline continuous prefetching.
- Warp Specialization: At the Tile level, communication, data movement, and tensor computation are physically decomposed. Different Warps (thread groups) operate independently yet in precise coordination, transforming the GPU into a continuously flowing, heterogeneous execution system.
This 1000 TPS breakthrough is the inevitable result of world-class system infrastructure and extreme algorithmic models deeply converging toward each other.
Due to limited high-speed inference resources, MiMo-V2.5-Pro-UltraSpeed is available through an application-based, limited-time window. We are prioritizing enterprises and professional developers with genuine business needs.