Moving beyond static benchmarks, a new state-verifiable browser game sandbox exposes the true capabilities—and severe limitations—of today’s leading AI agents.
- The Challenge: Multimodal Large Language Models (MLLMs) struggle with real-time, real-world interactions. Current benchmarks fail to reliably measure their progress due to latency issues and messy, heuristic evaluation metrics.
- The Solution: GameWorld introduces a standardized, reproducible benchmark using 34 browser games and 170 tasks, featuring a unique execution-pausing sandbox and outcome-based, state-verifiable evaluation.
- The Reality Check: Extensive testing across 18 model-interface pairs reveals that while AI agents can make partial progress, they are still fundamentally far from achieving human-level performance or reliable task completion.
The quest to build embodied artificial intelligence—agents capable of generalist, real-world interaction—is one of the defining challenges of modern computer science. While Multimodal Large Language Models (MLLMs) have shown incredible promise in static environments, they consistently stumble when deployed into dynamic scenarios. They suffer from crippling latency, struggle to learn from sparse feedback, and frequently make irreversible mistakes. To solve these problems, researchers need an environment that mimics the complexities of the real world without the physical risks and overhead.
As legendary designer Sid Meier famously stated, “A game is a series of interesting choices.” This philosophy makes video games the ultimate crucible for intelligent agents. Games tightly couple visual perception, strategic planning, precise timing, and sustained action over long horizons. Unlike static visual QA tests or single-turn tool applications, games demand that an AI repeatedly interpret a shifting visual scene, commit to actions with real consequences, and dynamically recover from errors. Within this domain, lightweight and mechanically diverse browser games have emerged as highly scalable alternatives to heavyweight game engines.
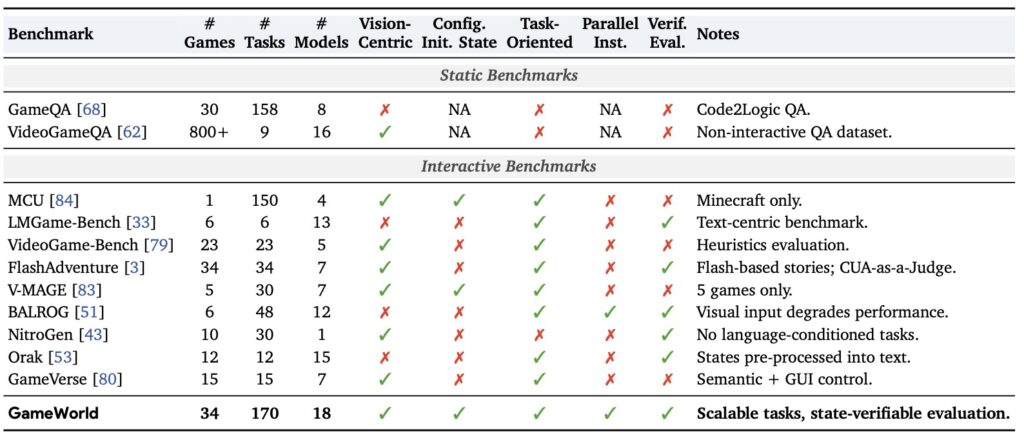
While the AI research community has recently embraced game-based evaluation, systematic challenges have held the field back. Previous and parallel efforts—such as LMGame-Bench, BALROG, VideoGame-Bench, Orak, and OSWorld—have certainly pushed the boundaries of realism and scale. Yet, these frameworks are often hindered by heterogeneous action interfaces and the messy coupling of inference latency with real-time gameplay. Furthermore, many rely on heuristics, OCR, or “VLM-as-judge” methods for evaluation. These subjective, noisy metrics make it incredibly difficult to verify, reproduce, and accurately diagnose an agent’s true capabilities.
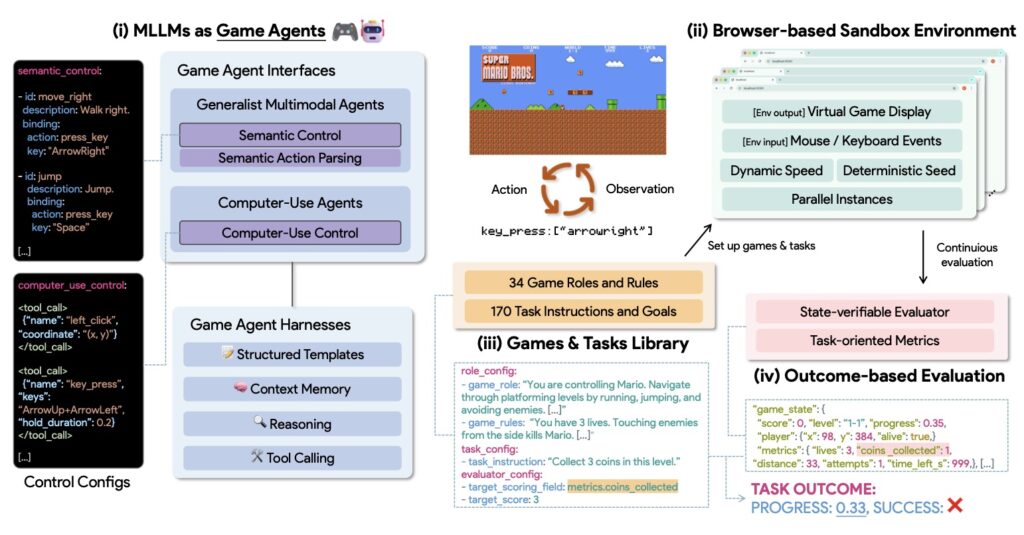
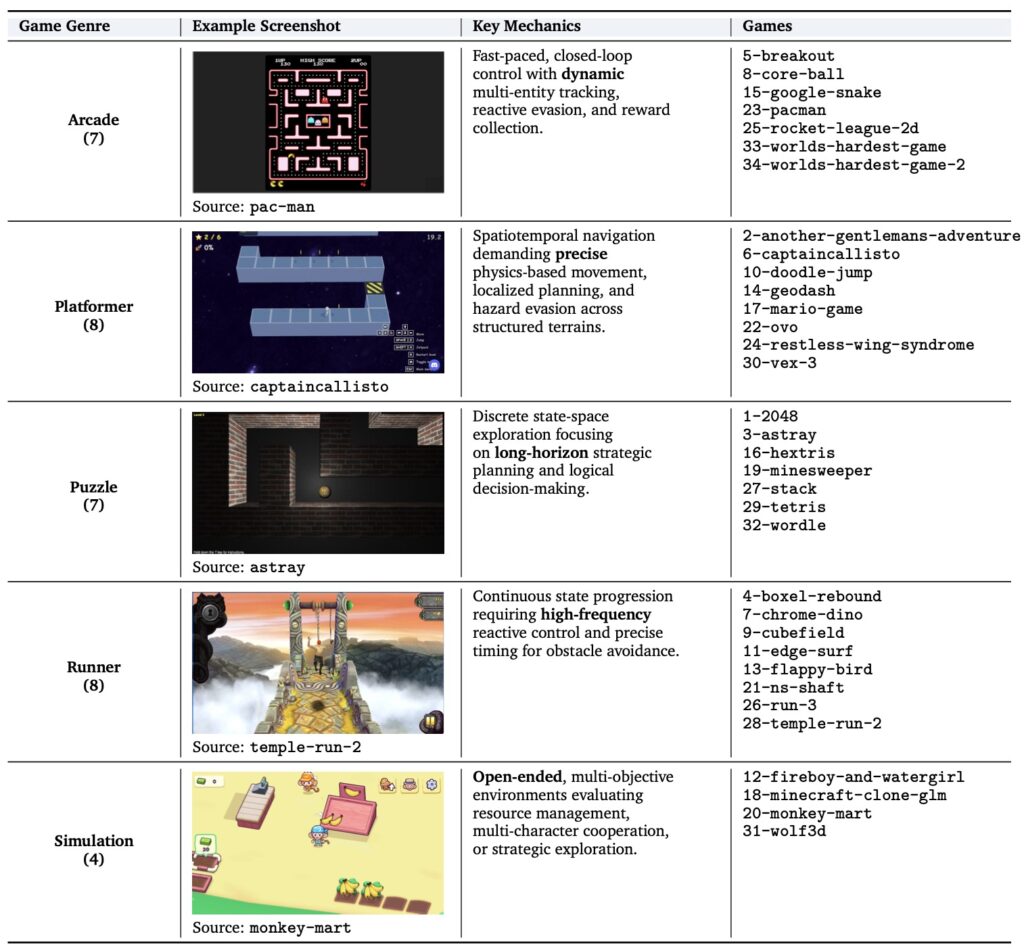
Enter GameWorld, a benchmark designed to strip away the noise and provide standardized, verifiable evaluation of MLLMs. GameWorld comprises 34 diverse browser games spanning five distinct genres—Runner, Arcade, Platformer, Puzzle, and Simulation—encompassing 170 unique tasks.
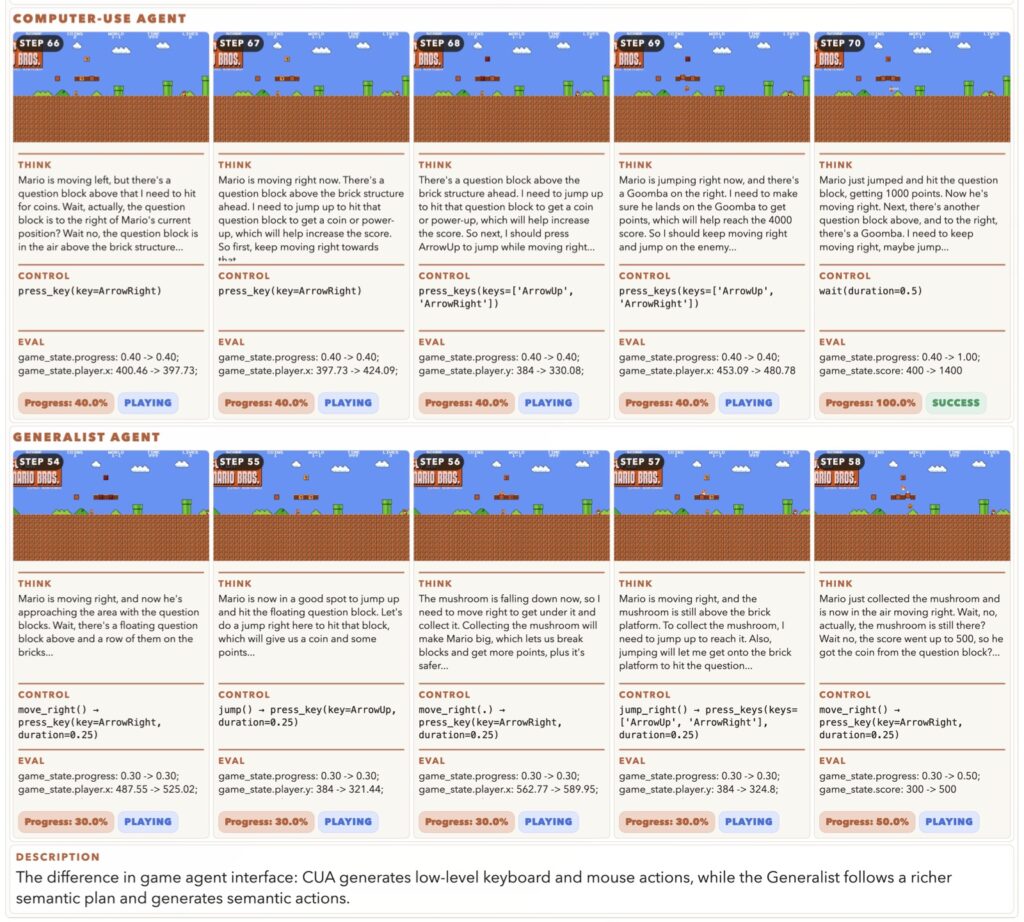
What sets GameWorld apart is its ingenious browser-based sandbox approach. To ensure fairness and accuracy, the sandbox actually pauses game execution during the model’s inference phase. This perfectly decouples processing latency from gameplay, ensuring that an agent’s score reflects its actual decision-making quality rather than its mere response speed. Furthermore, GameWorld abandons fuzzy evaluation methods in favor of outcome-based, state-verifiable evaluators. By tapping directly into serialized game API states, the benchmark produces deterministic progress and success signals completely free of perceptual noise.
Under this shared, standardized runtime, GameWorld evaluates two distinct approaches to AI interaction:
- Computer-Use Agents (CUAs): Agents that directly emit raw keyboard and mouse controls, simulating human physical input.
- Generalist Multimodal Agents: Agents that operate within a semantic action space via deterministic Semantic Action Parsing, allowing for higher-level strategic commands.
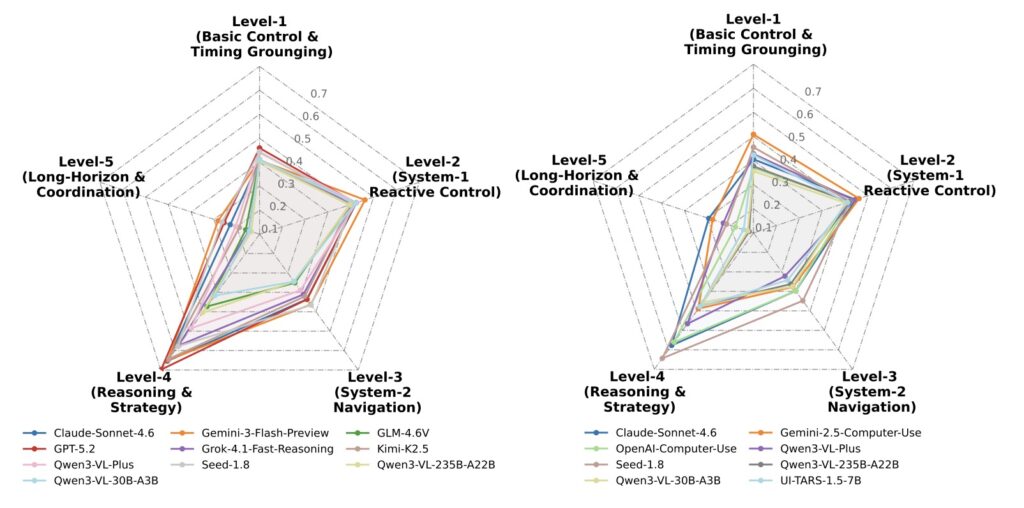
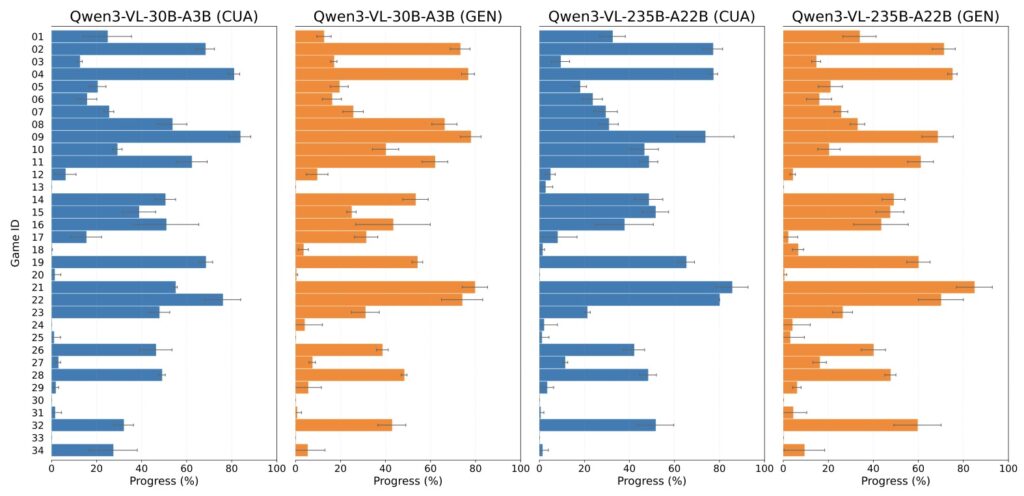
The results of GameWorld’s initial evaluations are both a testament to AI’s progress and a sobering reality check. Across 18 different model-interface pairs, the benchmark revealed that even the most advanced agents are far from achieving human capabilities. While current multimodal game agents can often make meaningful partial progress, they struggle immensely to convert that progress into reliable task completion across diverse environments.

By putting these models through repeated full-benchmark reruns, GameWorld exposed critical, interface-conditioned weaknesses. Today’s agents falter when faced with real-time interaction demands, show extreme sensitivity to context-memory limitations, and frequently struggle with action validity. The data makes one thing abundantly clear: building stronger game agents will require far more than just better reasoning. It will demand more reliable action grounding, highly useful trajectory memory, and an ironclad robustness to latency.
GameWorld’s primary limitation lies in its scalability; the benchmark requires the manual design of unique instruction sets for each new environment, which tightly couples the action space to specific tasks. Future work will focus on automating the production and alignment of Semantic Action Parsing through MLLM-powered exploration.
GameWorld provides a necessary mirror for the AI industry. By offering a reproducible, standardized, and verifiable evaluation framework, it cuts through the hype of static benchmarks and lays a robust, unshakeable foundation for advancing the next generation of multimodal agents.
