New approach offloads attention computation to a single k-nearest-neighbor index, enabling extremely long input sequences
- Unlimiformer can wrap any existing pretrained encoder-decoder transformer, allowing it to handle unlimited length input.
- The approach is demonstrated to be effective on several long-document and multi-document summarization benchmarks, without any input truncation at test time.
- Unlimiformer improves pretrained models like BART and Longformer without additional learned weights or code modification.
Researchers have proposed a groundbreaking approach called Unlimiformer, which enables transformer-based models to handle unlimited length input. Traditional transformer-based models have a predefined bound to their input length due to their need to attend to every token in the input. Unlimiformer overcomes this limitation by offloading attention computation across all layers to a single k-nearest-neighbor index, which can be kept on either GPU or CPU memory and queried in sub-linear time.
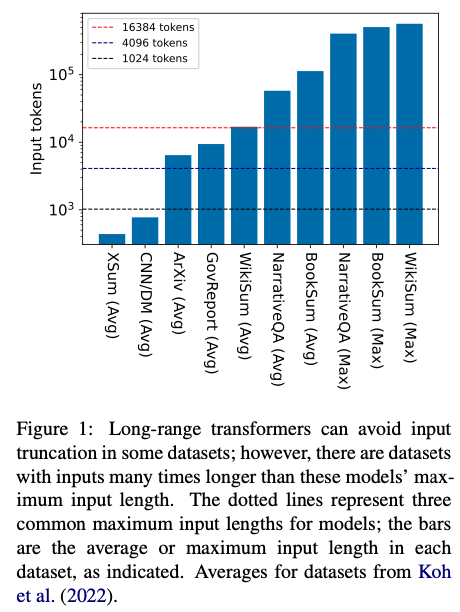
The approach allows for the indexing of extremely long input sequences while enabling every attention head in every decoder layer to retrieve its top-k keys instead of attending to every key. Unlimiformer has been demonstrated to be effective on several long-document and multi-document summarization benchmarks, even summarizing 350k token-long inputs from the BookSum dataset without any input truncation at test time.
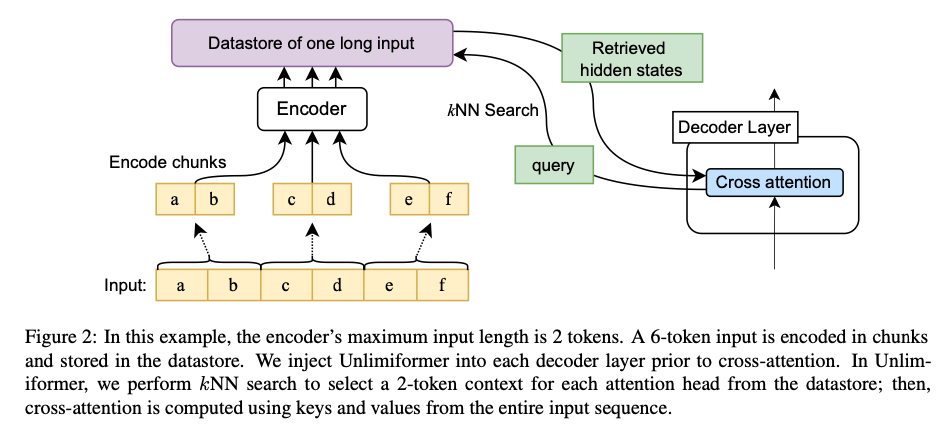
Unlimiformer can improve pretrained models, such as BART and Longformer, by extending them to unlimited inputs without additional learned weights and without modifying their code. The researchers have made their code and models publicly available to encourage further development and improvements.
Despite its remarkable capabilities, Unlimiformer does have some limitations. The approach has only been tested on English-language datasets, and its effectiveness in other languages may depend on the quality of the indexed embeddings and availability of strong pretrained models. Interpretability is also a concern, as the retrieved embeddings at each step are difficult to interpret, warranting further research.
Unlimiformer’s input length is theoretically bounded by the memory limitations of the computer used. While researchers were able to use a GPU datastore for input examples exceeding 500k tokens, there may be concerns when using smaller GPUs or even larger inputs. Future work may explore methods to further improve the performance of retrieval-augmented LLMs on challenging downstream tasks.