Automating AI Planning with LLMs: Exploring the Potential and Future Directions
- Framework for Evaluation: Introducing an automated evaluation framework for LLM-generated planning domains.
- Empirical Analysis: Analysis of seven large language models across nine planning domains reveals moderate proficiency.
- Future Directions: Deeper investigation into LLM capabilities, re-prompting techniques, and robust evaluation metrics.
The field of AI planning involves the creation of domain models, which traditionally requires significant human effort. A recent study explores the potential of large language models (LLMs) to automate the generation of these domain models from simple textual descriptions. The research introduces a framework for the automated evaluation of LLM-generated domains by comparing the sets of plans for domain instances, offering a promising step toward making AI planning more accessible.
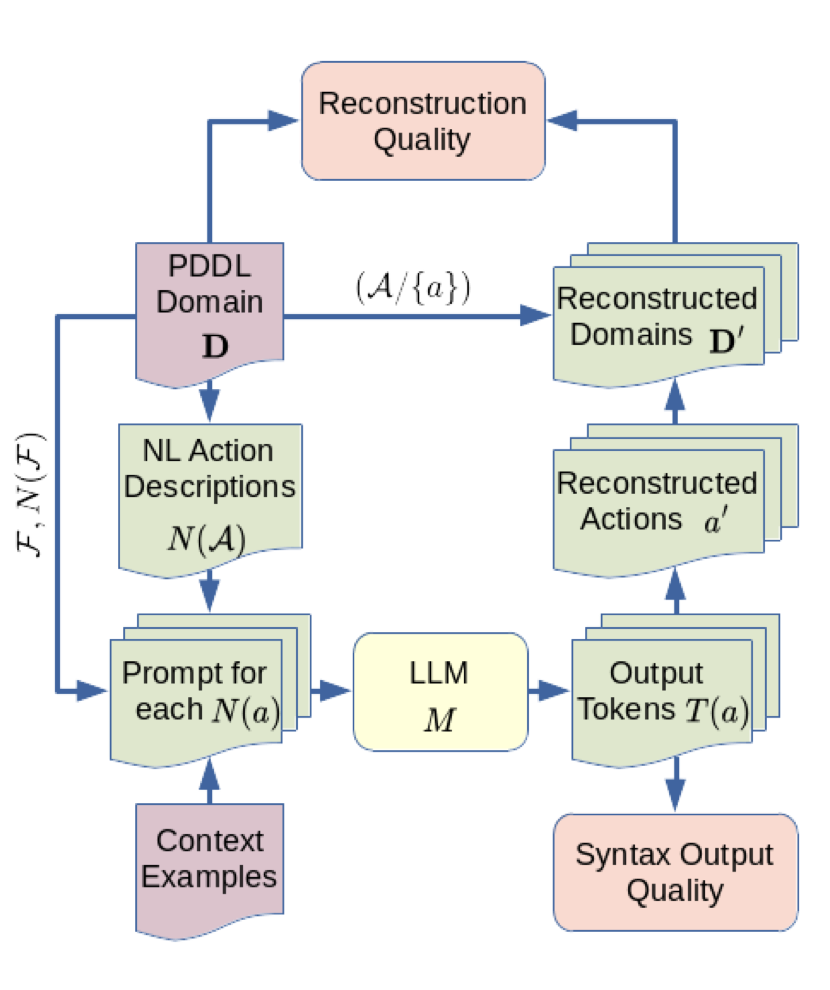
Framework for Automated Evaluation
The core of the study is the development of a framework that automatically evaluates the planning domains generated by LLMs. This evaluation compares sets of plans for domain instances, providing a metric to assess the accuracy and completeness of the generated models. This framework is crucial for understanding how well LLM-generated domains align with those created manually, ensuring that the automation process maintains high standards of reliability and effectiveness.
Empirical Analysis
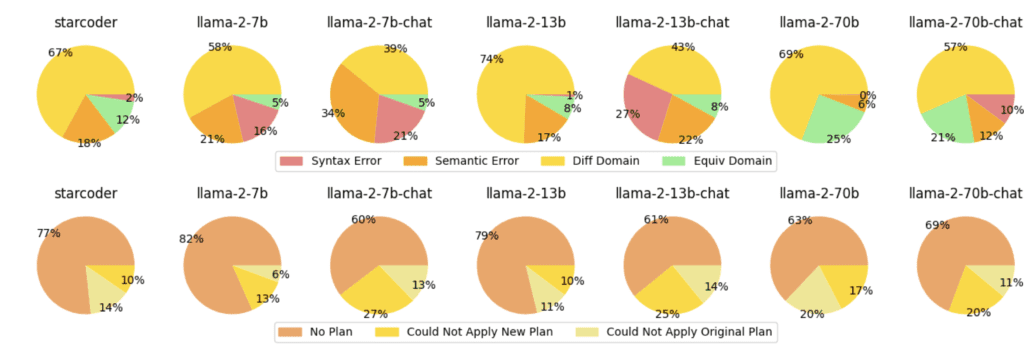
The empirical analysis conducted in the study covers seven large language models, including both coding and chat models, across nine diverse planning domains. These domains vary in complexity and type, providing a comprehensive test bed for the models. The analysis categorizes natural language descriptions into three classes:
- Simple Descriptions: Basic and straightforward, lacking detailed predicates or actions.
- Intermediate Descriptions: Containing some predicates and detailed actions.
- Detailed Descriptions: Highly detailed with all necessary predicates and actions.
Results indicate that larger models, such as GPT-4 and LLaMA-70b, exhibit better performance in generating correct planning domains from natural language descriptions. Coding models like StarCoder show particular promise when additional predicate information is included, suggesting the need for further investigation into these models’ capabilities.
Future Directions
The study identifies several promising directions for future research and development:
- Deeper Investigations into LLM Capabilities:
- Evaluating larger models and exploring their proficiency in PDDL construction.
- Examining the performance of models like Bloom, which have not yet been thoroughly tested in this context.
- LLM Tuning Approaches:
- Fine-tuning and prompt tuning can enhance the performance of smaller models on specific tasks.
- Chat-based LLMs with large context windows can be re-prompted to provide corrective feedback, improving the accuracy of generated domains.
- Robust Evaluation Metrics:
- Evaluating domains where all actions are generated is a desirable target for future assessments.
- Implementing iterative domain completion tasks, where previously generated actions are used as prompts, can help construct a full action schema for the domain.
The use of large language models to generate planning domain models represents a significant advancement in the field of AI planning. By automating this traditionally labor-intensive task, LLMs can make AI planning more accessible and efficient. The study’s framework for automated evaluation, combined with its empirical analysis, provides a strong foundation for future research. Further exploration into the capabilities of large language models, fine-tuning approaches, and robust evaluation metrics will continue to enhance the accuracy and applicability of LLM-generated planning domains, paving the way for more sophisticated and user-friendly AI planning systems.