Quantifying Uncertainty in Language Model Responses
- Researchers explore methods to identify when uncertainty in large language model (LLM) responses is high.
- The study distinguishes between epistemic uncertainty (knowledge gaps) and aleatoric uncertainty (randomness).
- A novel information-theoretic metric helps detect unreliable outputs, including hallucinations, in both single- and multi-answer responses.
As large language models (LLMs) continue to revolutionize natural language processing, a significant challenge remains: distinguishing reliable outputs from those with high uncertainty. This uncertainty can stem from knowledge gaps or inherent randomness, and addressing it is crucial for applications where accuracy is paramount. In a recent study, researchers delve into the intricacies of uncertainty quantification in LLMs, aiming to enhance the reliability of these models.

Understanding Uncertainty in LLMs
LLMs generate responses by modeling probability distributions over text. However, not all generated responses are equally reliable. The study identifies two primary sources of uncertainty:
- Epistemic Uncertainty: Arising from a lack of knowledge about the ground truth, such as factual information or language rules, often due to insufficient training data or model limitations.
- Aleatoric Uncertainty: Resulting from irreducible randomness in the prediction process, where multiple valid answers exist for the same query.
The researchers propose that analyzing epistemic uncertainty can serve as a proxy for evaluating the truthfulness of LLM responses. When epistemic uncertainty is low, model predictions are likely close to the ground truth.

A Novel Metric for Detecting Unreliable Outputs
To effectively quantify uncertainty, the study introduces an information-theoretic metric that focuses on epistemic uncertainty. This metric enables the detection of unreliable model outputs by iteratively prompting the model and analyzing the generated responses. This approach is particularly effective in identifying hallucinations—instances where the model produces responses with low truthfulness.
The key innovation lies in the ability to disentangle epistemic uncertainty from aleatoric uncertainty. Traditional methods often treat uncertainty as a monolithic concept, making it difficult to isolate knowledge gaps. By considering joint distributions of multiple answers, the proposed metric provides a more nuanced analysis, significantly improving the detection of hallucinations in both single- and multi-answer scenarios.
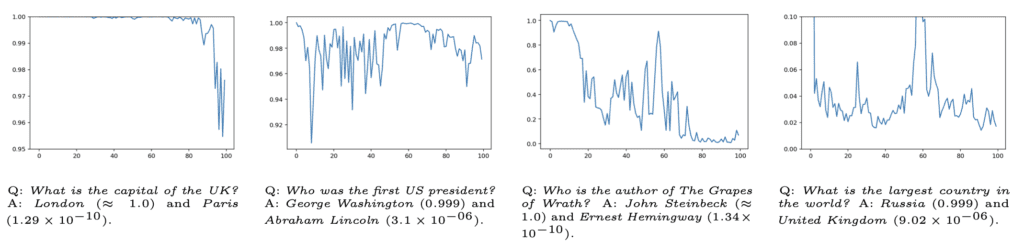
Experimental Validation
The researchers conducted extensive experiments to validate their approach. The results demonstrate that the mutual-information-based uncertainty estimator outperforms existing methods, particularly in mixed single-label/multi-label datasets. Unlike earlier methods that require modified training procedures, this new approach leverages the sequential nature of LLMs, making it more adaptable and less resource-intensive.
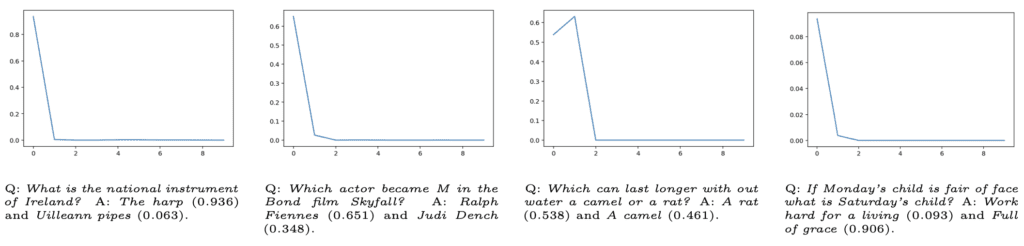
Implications and Future Work
This study offers a promising direction for enhancing the reliability of LLMs, particularly in critical applications where accuracy is crucial. By focusing on epistemic uncertainty, the researchers provide a robust framework for assessing the truthfulness of model outputs and identifying unreliable responses.
Future work will likely explore further refinements to the metric and its application across different LLM architectures. Additionally, integrating this uncertainty quantification method into real-world systems could pave the way for more trustworthy and effective AI applications.
The ability to quantify and address uncertainty in LLM responses is a significant advancement in the field of natural language processing. By distinguishing between epistemic and aleatoric uncertainty, and developing a novel information-theoretic metric, researchers have provided a powerful tool for enhancing the reliability of AI-generated text. As LLMs continue to evolve, such innovations will be crucial in ensuring their safe and effective deployment across various domains.