Expanding Context Windows in Open-Source Code Models
- IBM introduces Granite code models supporting up to 128K token context windows.
- Lightweight continual pretraining and instruction tuning enhance long-context performance.
- Open-sourced under Apache 2.0 license, these models bridge gaps in long-context tasks without degrading short-context capabilities.
IBM has unveiled a groundbreaking advancement in open-source code language models with the introduction of long-context Granite code models. These models support effective context windows of up to 128K tokens, significantly expanding the capabilities of code models in handling extensive and complex coding tasks.
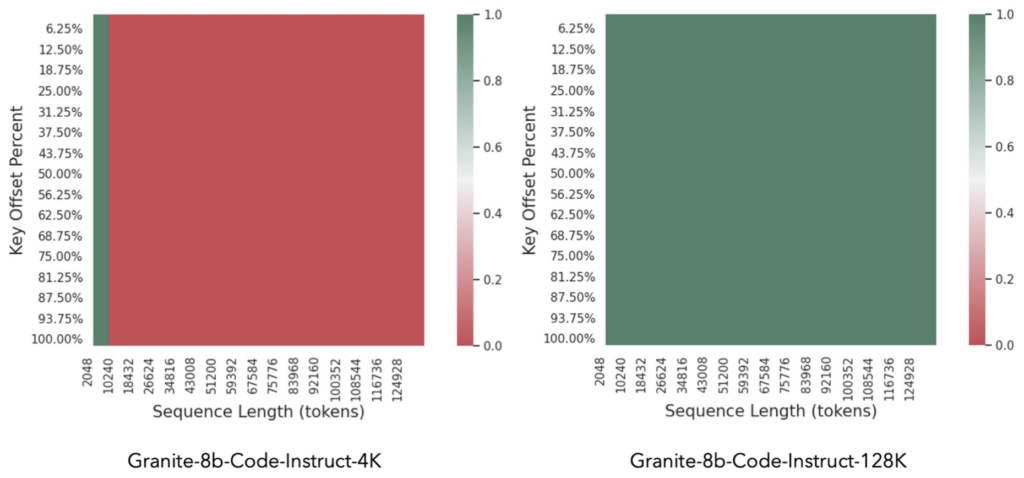
Extending Context Lengths
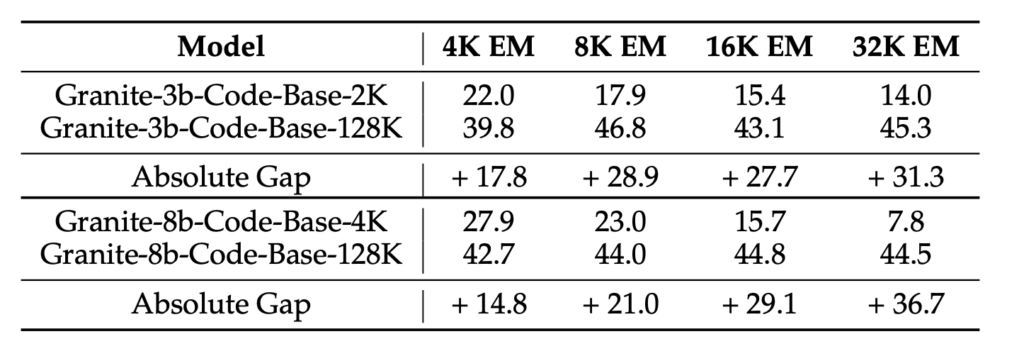
The Granite code models, with configurations of 3 billion and 8 billion parameters, have been scaled from traditional 2K/4K token limits to an impressive 128K tokens. This enhancement is achieved through a novel method of lightweight continual pretraining. The process involves gradually increasing the Rotary Positional Encoding (RoPE) base frequency while packing repository-level files and upsampling long-context data. This approach allows the models to effectively manage extended contexts, crucial for modern software development tasks.
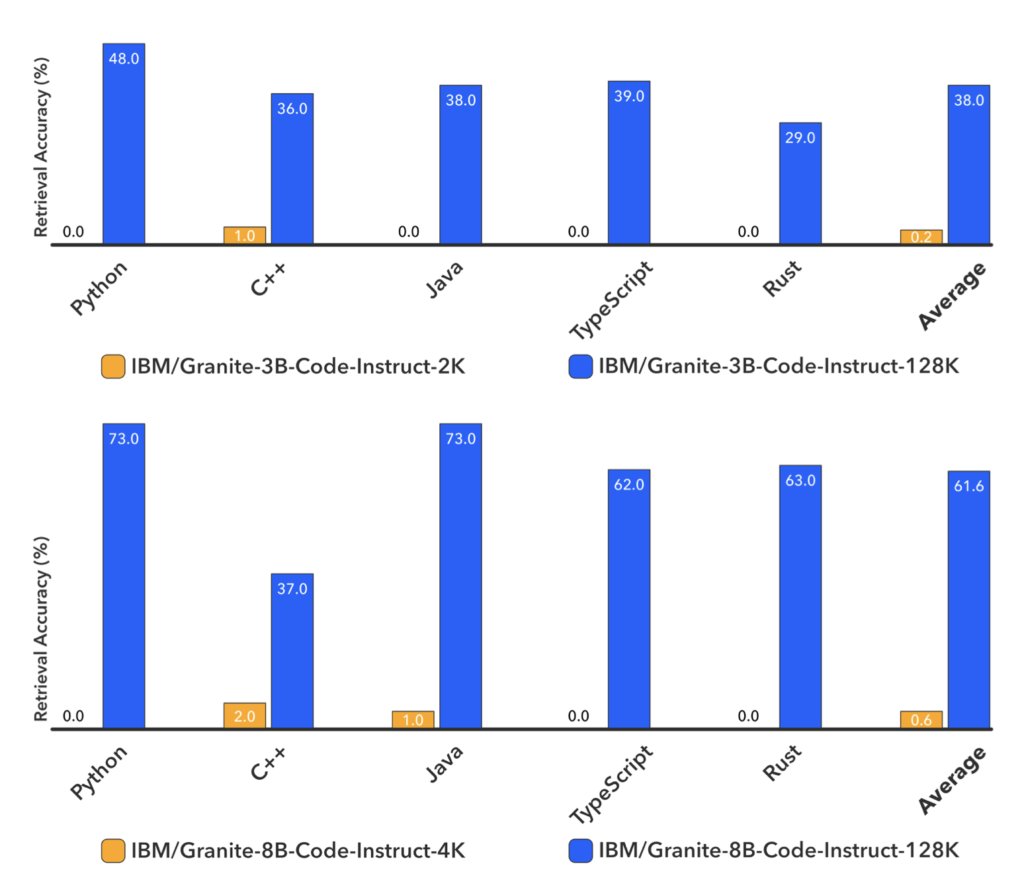
Instruction Tuning for Enhanced Performance
Following the pretraining, the models undergo further finetuning with a mix of short and long-context instruction-response pairs. This instruction tuning ensures that the long-context models not only excel in extended context tasks but also maintain their performance in standard code completion benchmarks, such as HumanEval. This dual-focus training regimen addresses the challenge of lacking long-context instruction data by generating multi-turn instruction data from repository-level documents.
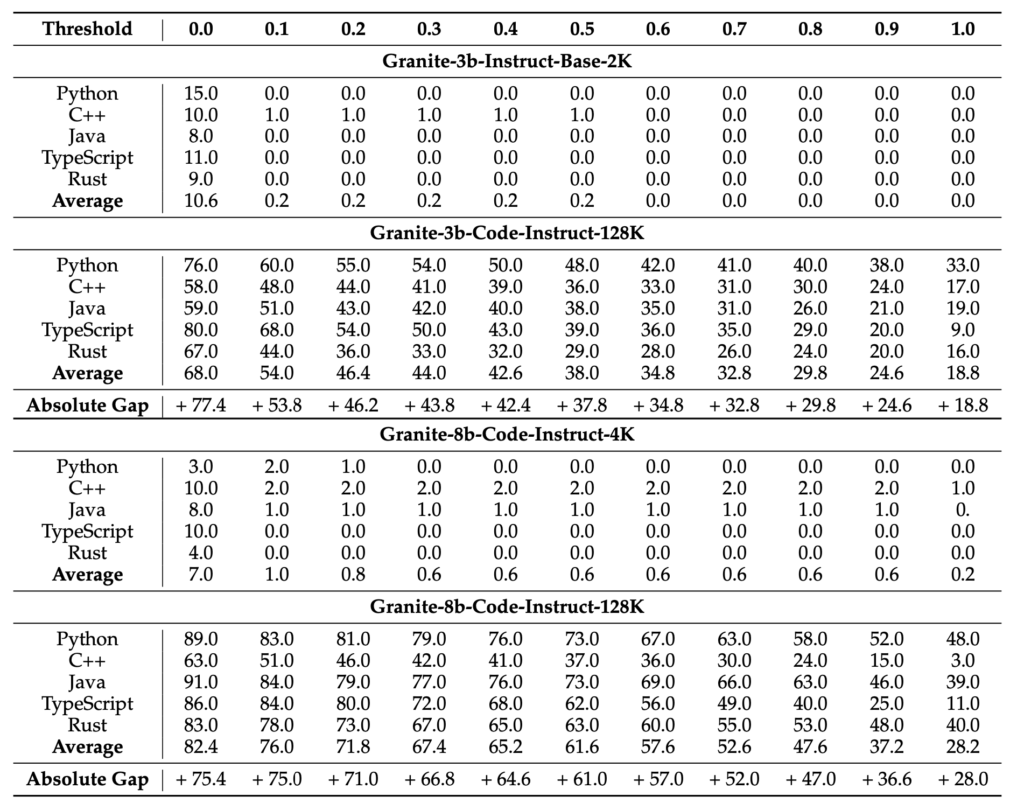
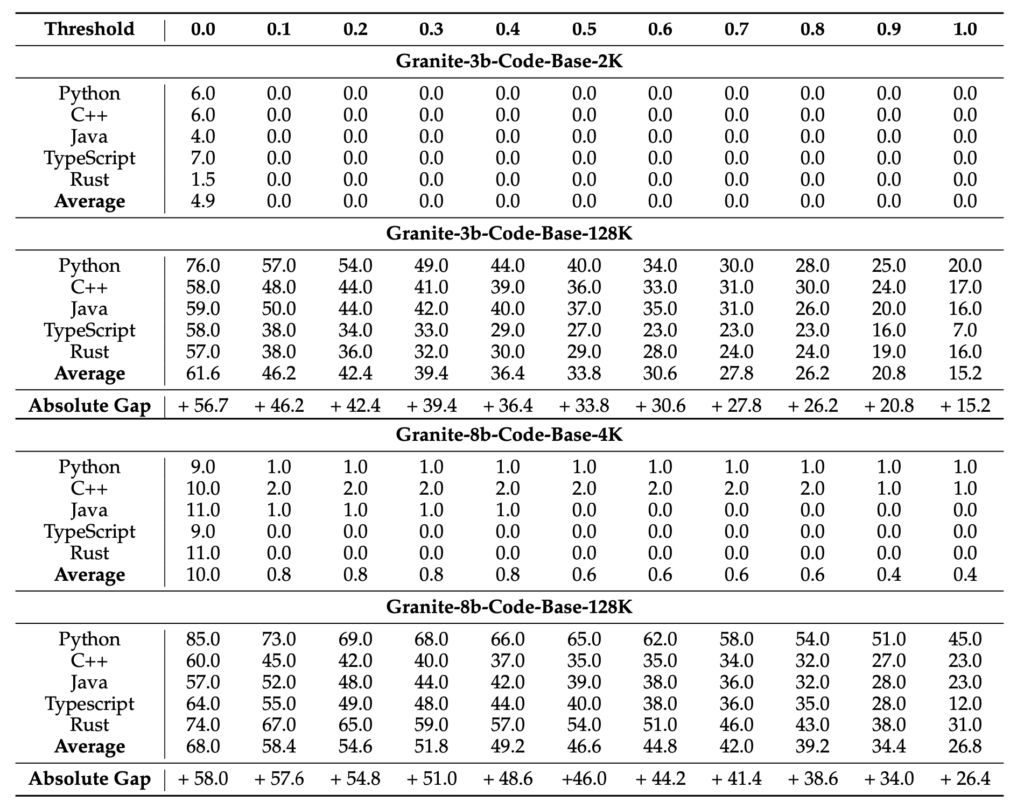
Evaluation and Open Source Availability
Extensive experiments conducted on a variety of tasks, including HumanEvalPack, Long Code Completion, RepoBench-P, RepoQA, and Key Retrieval, demonstrate significant improvements in long-context performance. Importantly, these enhancements do not come at the cost of short-context capabilities, showcasing the robustness of the new models.
In a strategic move to foster innovation and collaboration, IBM has open-sourced all Granite code models under the Apache 2.0 license. This decision not only provides researchers and developers with access to cutting-edge technology but also addresses the limitations of proprietary models like GPT-4, Gemini, and Claude, which have dominated the landscape with their extensive context windows.
Implications and Future Directions
The introduction of long-context Granite code models represents a pivotal step in advancing open-source code language models. By bridging the gap in long-context capabilities, these models enhance the practicality and efficiency of open-source solutions in real-world software development.
IBM’s approach highlights the importance of continual pretraining and instruction tuning in scaling context lengths without compromising performance. As the field evolves, further methods to extend context lengths and address the computational complexity of attention mechanisms are anticipated. IBM’s commitment to continuous updates and improvements signals a promising future for the Granite Family of models.
IBM’s long-context Granite code models mark a significant milestone in the development of open-source code language models, offering robust solutions for both short and long-context tasks and setting the stage for future innovations in the field.