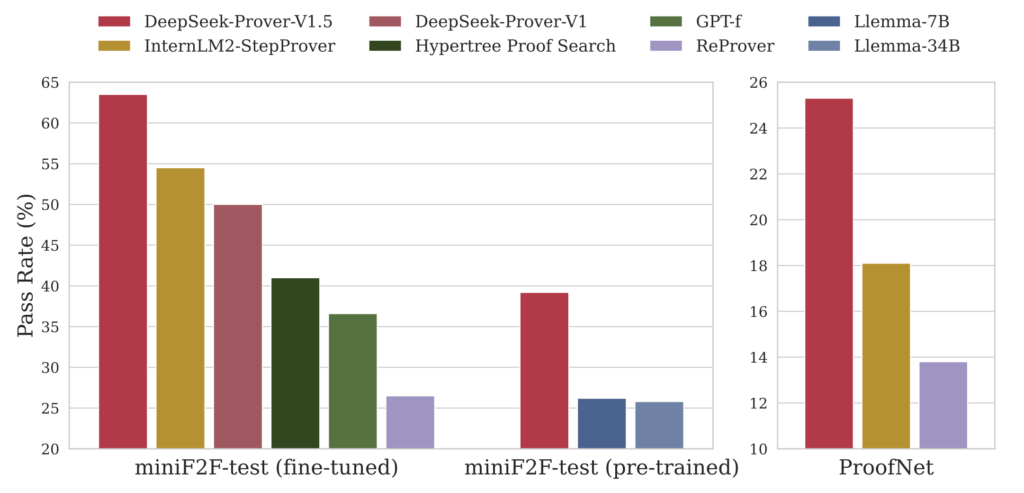
New advancements in AI-powered proof assistants bring a 63.5% success rate in formal theorem proving benchmarks
- Reinforcement Learning Feedback Boosts Performance: DeepSeek-Prover V1.5 leverages reinforcement learning from proof assistant feedback (RLPAF) to enhance theorem proving capabilities.
- Monte-Carlo Tree Search Innovation: A new variant, RMaxTS, introduces an exploration-driven strategy for diverse proof generation, improving problem-solving accuracy.
- Significant Benchmark Achievements: The model achieves state-of-the-art results on high school and undergraduate-level formal theorem proving benchmarks, outperforming previous iterations.
The latest advancements in artificial intelligence have extended beyond natural language processing and into complex domains like formal theorem proving, a critical area for mathematical reasoning. One of the leading efforts in this space is the introduction of DeepSeek-Prover V1.5, a cutting-edge AI designed to improve the accuracy and efficiency of formal proofs in the Lean 4 theorem proving system.
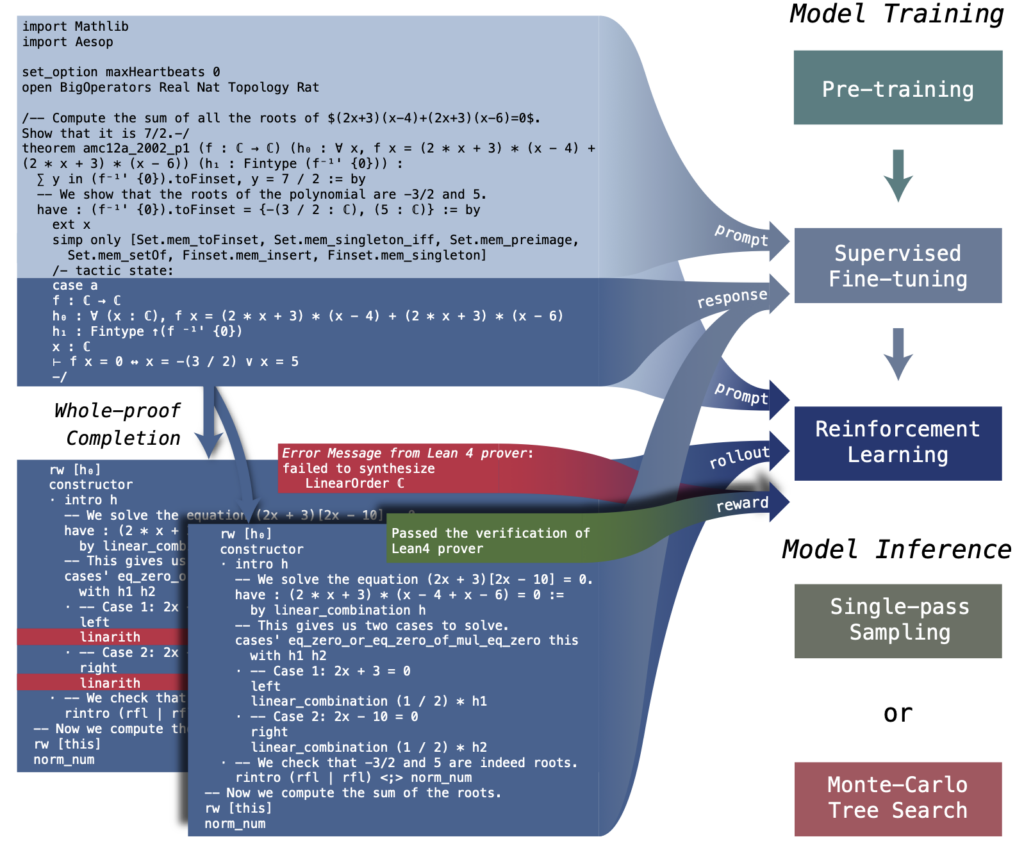
DeepSeek-Prover V1.5 builds on its predecessor, DeepSeek-Prover V1, by implementing reinforcement learning from proof assistant feedback (RLPAF). This innovation represents a new step forward in AI-assisted theorem proving, enabling the model to process proof steps with higher precision, thereby reducing the compounding errors typically encountered during long proof generation.
Advancements in Theorem Proving Techniques
Formal theorem proving is a complex task where AI must not only understand the logic and rules of mathematics but also align abstract reasoning with formal verification processes. Large language models like GPT-4 have made significant strides in fields like text generation and coding, yet even these advanced models struggle with formal proofs due to the meticulous nature of the task. In theorem proving, every step in the proof must be validated, making errors costly and difficult to correct.
DeepSeek-Prover V1.5 addresses these challenges with a hybrid approach that incorporates whole-proof generation and proof-step generation, the two dominant strategies in formal proving. Whole-proof generation allows for efficient processing, generating entire proof codes based on the theorem statement without repeated feedback between the model and verifier. Proof-step generation, on the other hand, works incrementally, verifying each tactic as it is applied. This latter approach ensures higher accuracy by catching errors early on but is often more computationally expensive.
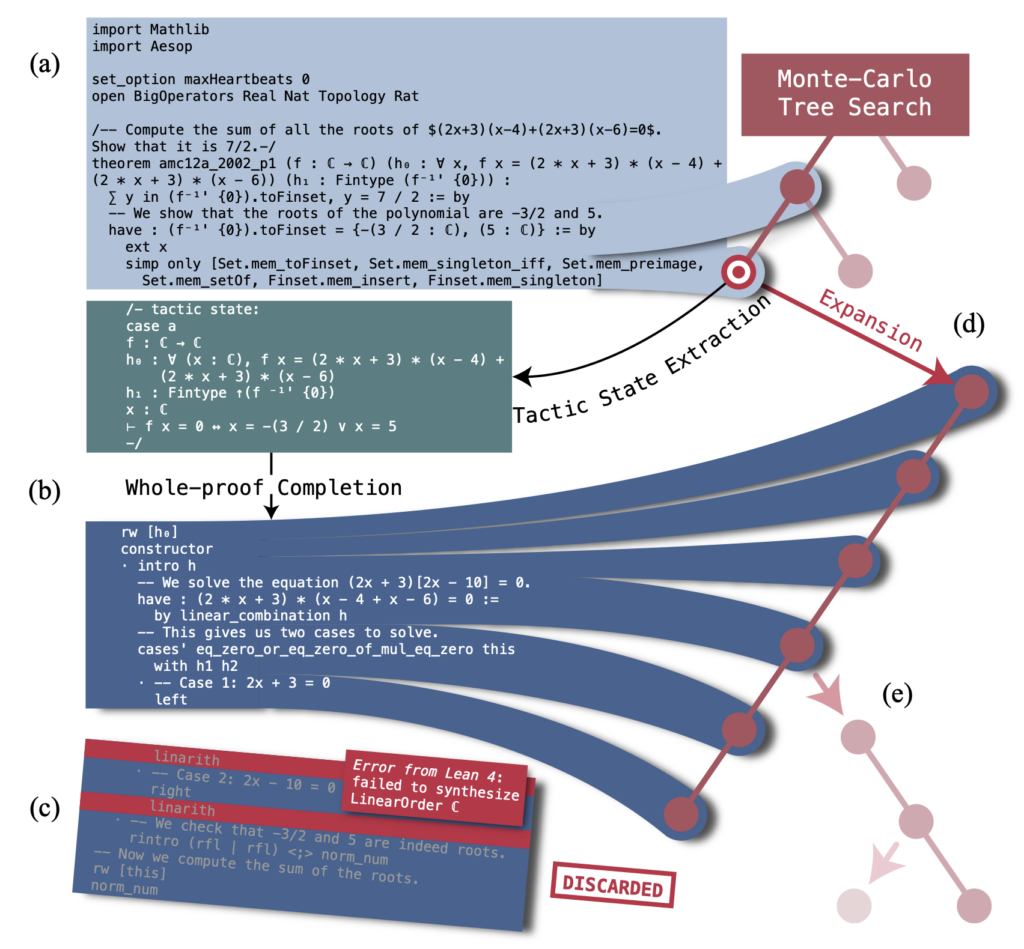
Introducing Reinforcement Learning and Monte-Carlo Tree Search
The major breakthrough with DeepSeek-Prover V1.5 lies in the introduction of reinforcement learning. By refining the proof generation process with feedback from a proof assistant, the model learns from both successful and unsuccessful proof paths. This approach drastically improves its generalization capabilities, allowing it to handle complex, multi-step reasoning problems that other models struggle to solve.
In addition, the new RMaxTS variant of Monte-Carlo Tree Search (MCTS) enhances the model’s ability to explore multiple proof paths. Unlike previous iterations, which tended to follow rigid proof strategies, RMaxTS allows DeepSeek-Prover V1.5 to explore diverse proof directions, guided by intrinsic rewards. This results in a richer set of proofs and a more robust problem-solving capability.
State-of-the-Art Performance on Key Benchmarks
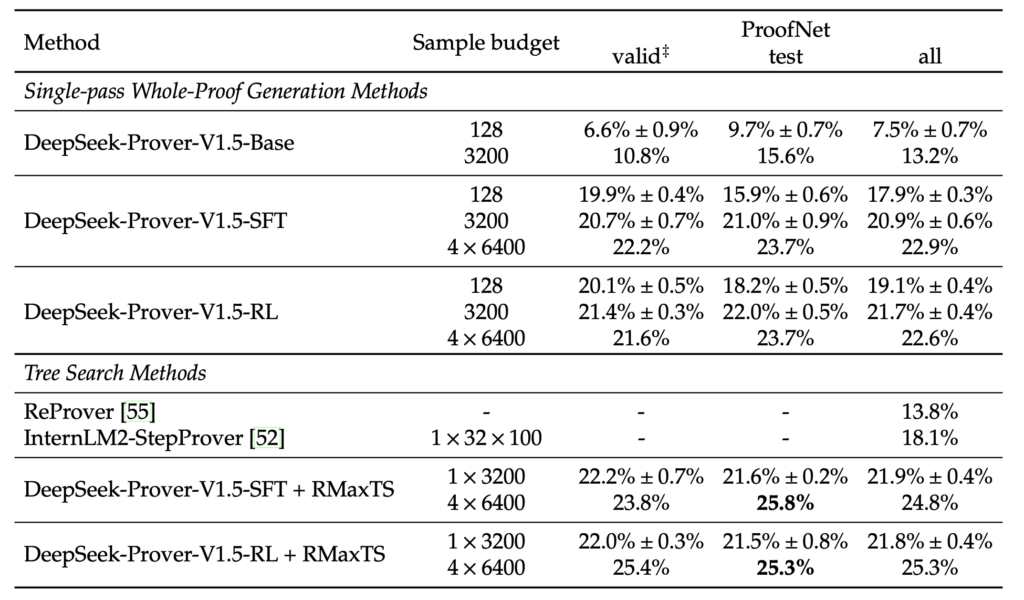
These advancements culminate in significant achievements for DeepSeek-Prover V1.5. On the miniF2F benchmark, which assesses formal theorem proving at the high school level, the model achieved a 63.5% success rate, setting a new state-of-the-art performance level. For the more advanced ProofNet benchmark, which evaluates undergraduate-level problems, DeepSeek-Prover V1.5 recorded a success rate of 25.3%. These results highlight the model’s capability to handle increasingly complex mathematical challenges.
The model’s ability to perform well on these benchmarks represents a major step forward in AI-driven mathematical reasoning, showcasing its ability to generalize solutions across a wide range of mathematical domains.
Future Potential for Theorem Proving AI
The introduction of reinforcement learning and advanced tree search techniques is not just a leap forward for DeepSeek-Prover V1.5; it signals the broader potential of AI in theorem proving. As AI models continue to evolve, the potential for applying them in real-world mathematical and scientific research grows exponentially.
Looking ahead, the DeepSeek-Prover team plans to continue refining their approach. Potential areas for exploration include expanding the model’s capabilities with larger datasets, improving fine-tuning methods, and further optimizing MCTS strategies to enhance problem-solving efficiency. These improvements could open the door to new applications of AI in academia, research, and even industry.
DeepSeek-Prover V1.5 represents a significant leap in the world of formal theorem proving, combining reinforcement learning, Monte-Carlo Tree Search, and large-scale language models to tackle complex mathematical problems. The model’s success on key benchmarks suggests that AI could soon become an indispensable tool for mathematicians and researchers, helping to solve challenging problems with greater speed and precision than ever before.
As the AI landscape continues to evolve, tools like DeepSeek-Prover V1.5 will likely pave the way for even more sophisticated applications, pushing the boundaries of what machines can achieve in mathematical reasoning and beyond.