A Novel Framework Enhances the Cohesion of Audio-Visual Experiences
The convergence of visual content and music generation has long posed challenges for creators aiming to produce immersive multimedia experiences. The introduction of MuVi—a groundbreaking framework designed to generate music that aligns seamlessly with video content—addresses these complexities.
- Deep Semantic and Rhythmic Alignment: MuVi analyzes video content to extract relevant features, enabling the generation of music that matches not only the mood and theme of the visuals but also their rhythm and pacing.
- Contrastive Pre-Training Scheme: The framework employs a novel contrastive music-visual pre-training scheme to enhance synchronization, taking into account the periodic nature of music phrases for greater cohesion between audio and visual elements.
- Adaptive Music Generation: MuVi’s flow-matching-based music generator demonstrates in-context learning abilities, allowing for control over the style and genre of the generated music to suit varying visual narratives.

As multimedia social platforms proliferate, the demand for high-quality, engaging video content has skyrocketed. Music plays a pivotal role in enhancing video experiences, yet generating music that harmonizes with the visual narrative remains a formidable task. Traditional video-to-music (V2M) methods have focused primarily on aligning music with the global features of entire video clips, such as theme, emotion, and style. However, these approaches often fail to adapt when the video shifts between different themes or emotions, resulting in a disjointed audio-visual experience.
MuVi addresses these shortcomings by focusing on two critical aspects of V2M generation: semantic alignment and rhythmic synchronization. Semantic alignment ensures that the music captures the emotional and thematic essence of the video, while rhythmic synchronization guarantees that the music’s tempo and rhythm resonate with the visual dynamics. Achieving both is essential for creating a cohesive and engaging audio-visual experience.
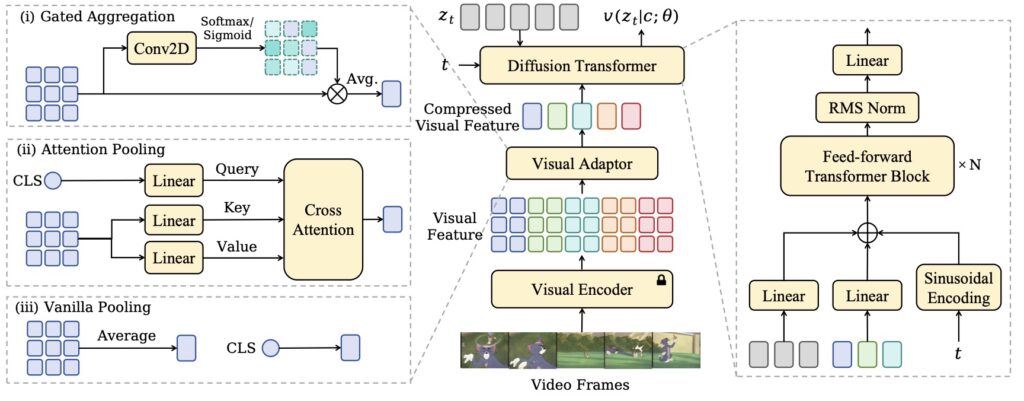
Introducing the MuVi Framework
MuVi employs a sophisticated visual adaptor that extracts contextually and temporally relevant features from video content. This information is crucial for generating music that not only matches the video’s mood but also synchronizes rhythmically. The framework utilizes a non-autoregressive ordinary differential equation (ODE)-based music generator, streamlining the music creation process while maintaining high quality.
One of the standout features of MuVi is its innovative contrastive music-visual pre-training scheme. This approach emphasizes temporal synchronization by addressing the periodic nature of musical beats, ensuring that the generated music aligns perfectly with the visual cues present in the video. Through this method, MuVi enhances the overall coherence of the audio-visual content, making it more immersive and engaging for viewers.
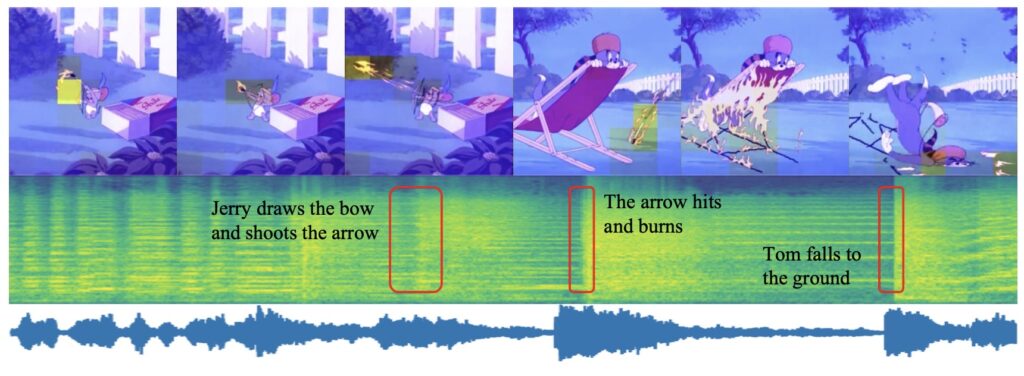
Experimentation and Results
Extensive experiments conducted with MuVi demonstrate its superior performance in both audio quality and temporal synchronization compared to existing V2M methods. By analyzing various datasets, researchers have confirmed that MuVi effectively generates intricate soundtracks that are semantically aligned and rhythmically synchronized with the visual content.
The results indicate that MuVi not only outperforms traditional image-to-music models but also excels in adapting to dynamic changes within the video content. This adaptability is particularly crucial in scenarios where videos shift themes or moods, ensuring a seamless transition in the accompanying music.
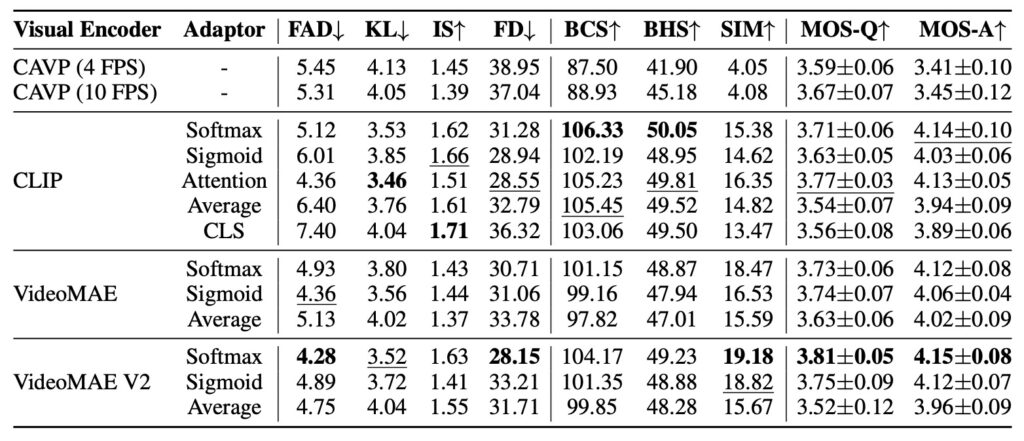
Future Directions: Expanding the Scope of V2M
Looking ahead, the creators of MuVi are exploring further enhancements, such as the integration of controllable V2M methods driven by textual prompts. This development would enable users to generate music that aligns not only with the visual content but also with specific styles or emotions described in textual format. Such advancements promise to broaden the creative possibilities for content creators and enhance the user experience in multimedia production.
By continuously refining the technology and exploring new avenues for control and adaptation, MuVi aims to set a new standard in the field of video-to-music generation. As the demand for cohesive audio-visual content continues to grow, frameworks like MuVi will play an integral role in shaping the future of multimedia storytelling.
A New Era in Audio-Visual Harmony
MuVi represents a significant leap forward in the quest to generate music that harmonizes with video content. By effectively addressing the challenges of semantic alignment and rhythmic synchronization, this innovative framework enhances the immersive quality of audio-visual experiences. As research and development in this area progress, MuVi is poised to redefine how we approach music generation in multimedia, opening up exciting possibilities for creators across various industries. The future of video content creation is bright, and with tools like MuVi, we can expect a new era of artistic expression that fully embraces the synergy between sound and vision.