ByteDance introduces a state-of-the-art solution for consistent, high-quality depth estimation in extended videos.
- Long-Video Capability: Video Depth Anything tackles the challenge of estimating depth for videos lasting several minutes without compromising quality or efficiency.
- Temporal Consistency: A new temporal gradient matching loss eliminates inconsistencies between frames, ensuring smooth depth transitions across video sequences.
- Real-Time Performance: Scalable models offer performance at up to 30 FPS, making them suitable for a range of applications from real-time processing to high-quality rendering.
ByteDance has unveiled Video Depth Anything, a groundbreaking solution for depth estimation in super-long videos, addressing temporal inconsistencies that have plagued previous models. While traditional methods struggle with videos longer than 10 seconds, this innovation supports high-quality, consistent depth estimation for extended durations—pushing the boundaries of video depth technology.
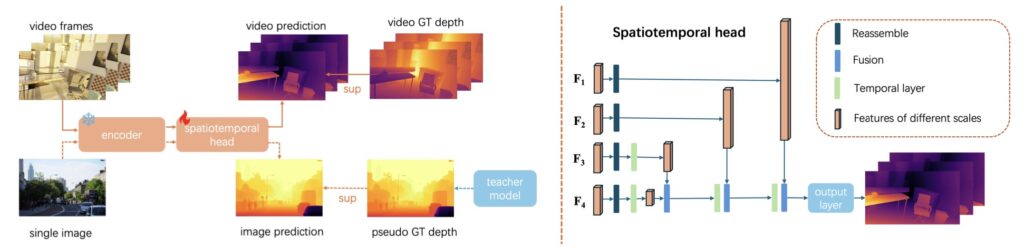
Building on the success of Depth Anything V2, ByteDance replaces the previous head with an efficient spatial-temporal head. This design integrates temporal self-attention into feature maps, ensuring seamless transitions across video frames while maintaining computational efficiency.
Breaking Barriers with New Strategies
The core innovations of Video Depth Anything include:
- Spatial-Temporal Head: Introduces temporal interactions through self-attention, ensuring smooth depth transitions across frames.
- Temporal Gradient Matching Loss: Enforces temporal consistency without needing geometric priors like optical flow or camera poses.
- Keyframe-Based Inference: A novel strategy for segment-wise processing, allowing depth stitching for long video sequences while maintaining accuracy.

Unparalleled Performance
Extensive evaluations show that Video Depth Anything achieves state-of-the-art results in three critical areas: spatial accuracy, temporal consistency, and computational efficiency. The model is trained on a joint dataset of video depth and unlabeled images, enhancing its generalization ability across various scenarios. The smallest model even supports real-time performance at 30 FPS, making it ideal for resource-constrained environments.
Transforming Video Applications
ByteDance’s innovation paves the way for applications in video editing, augmented reality, autonomous vehicles, and more. By eliminating the need for trade-offs between quality and efficiency, Video Depth Anything sets a new benchmark for zero-shot video depth estimation.
As video content grows increasingly complex, this technology ensures depth consistency over minutes, not seconds, revolutionizing how we perceive and utilize depth in long-form videos.