How a 24-Hour Sprint Birthed a Powerful, Open Alternative to OpenAI’s Deep Research
- OpenAI’s Deep Research is impressive but closed-source – a team of developers took on the challenge to replicate and open-source its capabilities in just 24 hours.
- Open-Deep-Research – an open-source AI agent that can navigate the web, manipulate files, and perform complex calculations, achieving 55% accuracy on the GAIA benchmark.
When OpenAI unveiled Deep Research, the AI community was awestruck. This system, capable of autonomously browsing the web, summarizing content, and answering complex questions, marked a significant leap in AI capabilities. However, as with many of OpenAI’s innovations, it remained a closed system, leaving developers and researchers yearning for an open alternative.
Enter Open-Deep-Research, a project born out of a 24-hour sprint by a team of passionate developers. Their mission? To replicate OpenAI’s Deep Research and open-source it for the world. The result is a powerful AI agent that not only matches many of Deep Research’s capabilities but also sets the stage for a new era of collaborative AI development.
Why Agent Frameworks Matter
At the heart of systems like Deep Research and Open-Deep-Research lies the concept of agent frameworks. These frameworks act as a layer on top of large language models (LLMs), enabling them to perform actions like web browsing, file manipulation, and multi-step reasoning.
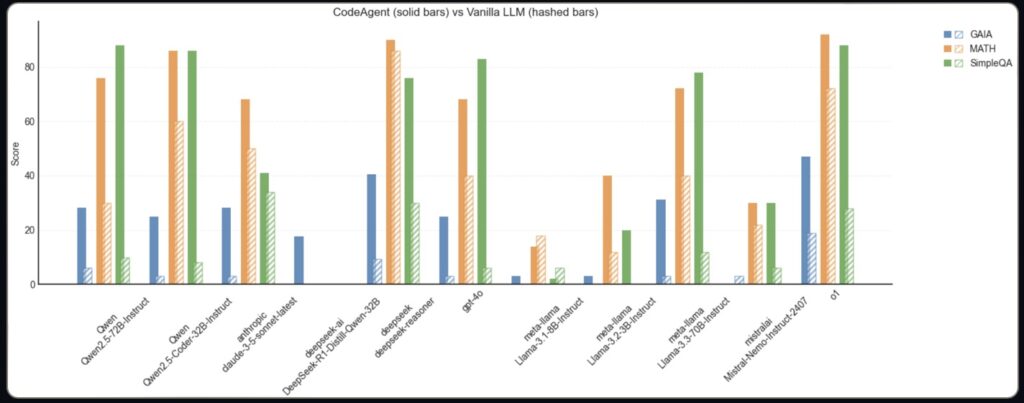
While standalone LLMs are impressive, integrating them into agentic systems unlocks their true potential. For instance, OpenAI’s Deep Research demonstrated a 67% accuracy on the GAIA benchmark, a significant improvement over standalone LLMs. Similarly, Open-Deep-Research achieved 55% accuracy on the same benchmark, making it the best open-source solution available.
Agent frameworks are not just about performance; they’re about empowering LLMs to interact with the world. Whether it’s extracting data from a PDF, searching the web for real-time information, or running complex calculations, these frameworks turn LLMs into versatile problem-solving tools.
The GAIA Benchmark: A Litmus Test for AI Agents
The GAIA benchmark is one of the most rigorous tests for AI agents. It challenges systems with multi-step reasoning, multimodal capabilities, and complex problem-solving. For example, one question asks:
“Which of the fruits shown in the 2008 painting ‘Embroidery from Uzbekistan’ were served as part of the October 1949 breakfast menu for the ocean liner that was later used as a floating prop for the film ‘The Last Voyage’?”
This question requires the AI to:
- Identify fruits from an image.
- Trace the history of an ocean liner.
- Retrieve a specific breakfast menu.
- Chain these steps together in a logical sequence.
OpenAI’s Deep Research achieved 67% accuracy on GAIA, while Open-Deep-Research reached 55% – a remarkable feat for an open-source project developed in just 24 hours.
Building Open-Deep-Research: A 24-Hour Sprint
The team behind Open-Deep-Research focused on two key innovations to replicate Deep Research’s capabilities:
1. Code Agents: A Game-Changer
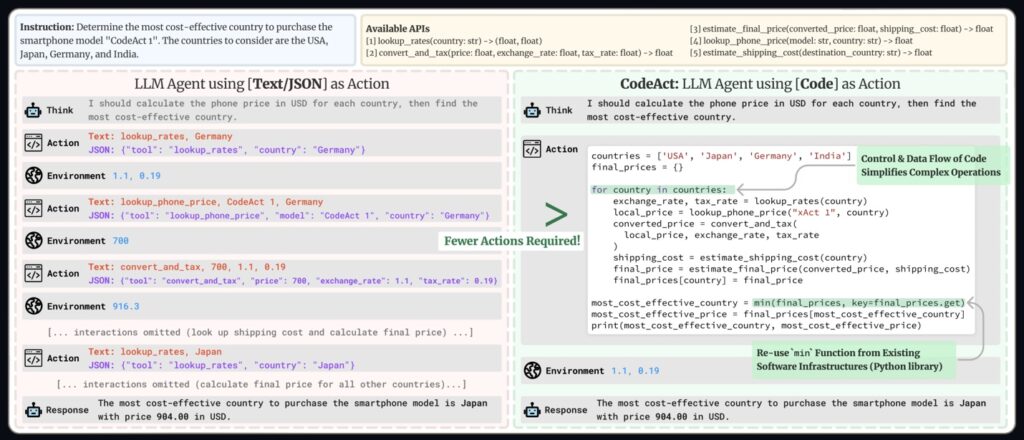
Traditional agent frameworks often rely on JSON to define actions, which can be cumbersome and inefficient. Open-Deep-Research leverages code agents, allowing the AI to express actions in code. This approach offers several advantages:
- Conciseness: Code is more compact than JSON, reducing the number of steps and tokens required.
- Reusability: Common libraries and tools can be easily integrated.
- Performance: Code agents have shown a 30% improvement in benchmarks compared to JSON-based systems.
2. The Right Tools for the Job
To enable the agent’s capabilities, the team equipped it with essential tools:
- A text-based web browser for navigating and extracting information.
- A text inspector for reading and manipulating files.
While these tools are simple, they provide a solid foundation for future improvements, such as vision-based browsing and support for more file formats.
Results and the Road Ahead
In just 24 hours, Open-Deep-Research achieved 55% accuracy on the GAIA benchmark, surpassing previous open-source solutions like Magentic-One (46%). This performance is a testament to the power of code agents and the potential of open-source collaboration.
However, this is just the beginning. The team has outlined a roadmap for future improvements, including:
- Expanding file format support.
- Enhancing web browsing capabilities.
- Integrating vision-based tools for richer interactions.