Can ByteDance’s Breakthrough Outperform OpenAI’s Sora and Google’s Veo?
- OmniHuman-1 is a revolutionary AI model that transforms a single image into a lifelike video of a person speaking, singing, or performing, synchronized perfectly with audio or other motion signals.
- Trained on an unprecedented scale, OmniHuman-1 leverages a mixed-condition training strategy, enabling it to handle full-body animation, precise lip-sync, and natural gestures across diverse scenarios.
- A game-changer in AI video generation, OmniHuman-1 outperforms existing models in realism and flexibility, setting a new benchmark for human animation and challenging competitors like OpenAI’s Sora and Google’s Veo.

The world of AI-generated video is advancing at a breathtaking pace, and ByteDance’s OmniHuman-1 is at the forefront of this revolution. This groundbreaking model, developed by the creators of TikTok, is redefining what’s possible in human animation. By transforming a single image and an audio clip into a lifelike video of a person speaking, singing, or even interacting with objects, OmniHuman-1 is pushing the boundaries of realism and flexibility in AI-generated content. But how does it stack up against other leading models like OpenAI’s Sora and Google’s Veo? Let’s dive into the technology, capabilities, and implications of this remarkable innovation.
The Technology Behind OmniHuman-1
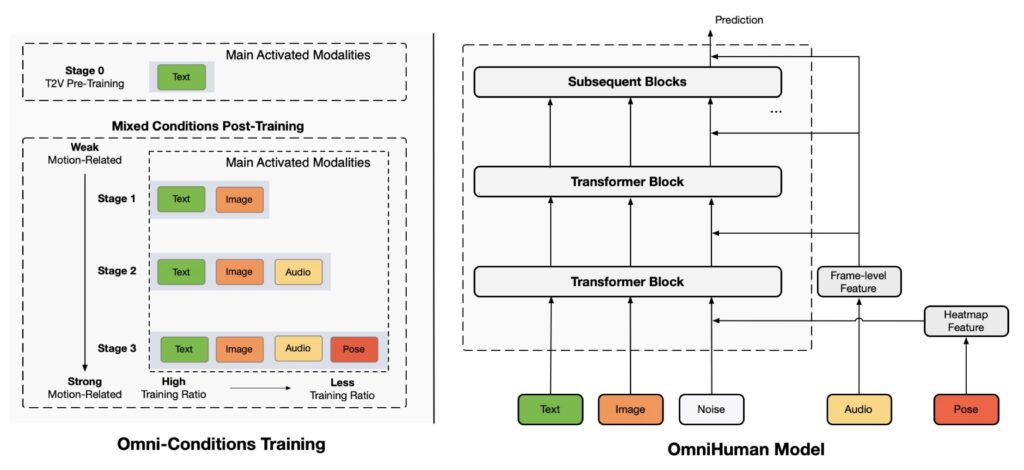
At its core, OmniHuman-1 is a diffusion transformer-based framework, combining the strengths of diffusion models (the driving force behind recent AI image and video advancements) with transformer architectures. What sets it apart is its unique training strategy. Unlike traditional models that rely on narrow datasets, OmniHuman-1 employs an “omni-conditions” mixed training approach. This means it learns from multiple types of inputs simultaneously—audio tracks, text descriptions, pose information, and reference images—enabling it to leverage a vast and diverse dataset.

ByteDance’s researchers trained the model on an astonishing 18,700 hours of human video data, equivalent to over two years of continuous footage. Crucially, they didn’t discard “imperfect” clips, such as videos with unclear lip movements. Instead, they used every available data point, allowing the model to learn from a wide range of scenarios. This approach not only scales up the training process but also ensures the model captures the nuances of natural human movement, from subtle facial expressions to complex hand gestures.
The result is a highly robust system capable of data-driven motion generation. OmniHuman-1 predicts and generates movements by analyzing sequences, much like how large language models predict text. This enables it to produce lifelike animations that are synchronized with audio, video, or even text inputs.
Key Capabilities of OmniHuman-1
OmniHuman-1 isn’t just another talking-head generator. It’s a versatile, multimodal system that excels in several areas:
- Full-Body Animation & Natural Gestures
Unlike earlier models that focused solely on facial movements, OmniHuman-1 generates realistic full-body animations. It can make a person gesture with their hands, shift their posture, and even interact with objects—all while staying perfectly synchronized with the audio. For instance, if the input is an upbeat song, the avatar might sway or dance subtly to the rhythm. This level of detail, especially in hand movements, sets OmniHuman-1 apart from its predecessors. - Precise Lip-Sync & Facial Expressions
The model’s ability to generate accurate lip-sync and facial expressions is unparalleled. It captures not just the phonemes of speech but also the corresponding emotions and muscle movements. Whether it’s a sad song or an enthusiastic speech, OmniHuman-1 ensures the avatar’s expressions align perfectly with the audio. - Versatile Inputs & Multimodal Control
OmniHuman-1 supports multiple driving modalities, including audio, video, and text. You can animate a person using just an audio clip, mimic the movements of a reference video, or even combine inputs for more complex animations. This flexibility makes it a powerful tool for creators, enabling them to generate everything from talking-head avatars to full-body performances. - High-Quality, Photorealistic Output
The model’s outputs are state-of-the-art in terms of realism. From natural blinking to consistent hair and clothing movements, OmniHuman-1 produces videos that are virtually indistinguishable from real footage. It also handles different camera views and aspect ratios, making it suitable for a wide range of applications, from smartphone apps to widescreen presentations.

How Does OmniHuman-1 Compare to Sora and Veo?
While OmniHuman-1 specializes in human animation, OpenAI’s Sora and Google’s Veo are more general-purpose video generation models. Sora, for instance, excels at creating scenes from text prompts, such as “a dog chasing a ball on a beach.” However, it struggles with fine human details, often producing less realistic facial expressions and gestures.
Veo 2, on the other hand, is Google’s answer to the generative video race. It supports high-resolution outputs (up to 4K) and can generate videos from text or image prompts. However, like Sora, it’s not specifically designed for human animation, which gives OmniHuman-1 an edge in this domain.
OmniHuman-1’s focus on realistic human videos, combined with its ability to handle precise lip-sync and natural gestures, makes it the go-to tool for animating human subjects. While Sora and Veo are better suited for creating fictional scenes or landscapes, OmniHuman-1 shines when it comes to bringing real (or fictional) people to life.

The Future of AI Video Generation
OmniHuman-1 is more than just a technological marvel—it’s a glimpse into the future of AI-generated content. Its success could inspire further research into multi-modal training strategies and larger datasets, pushing the boundaries of what’s possible in video generation.
Moreover, OmniHuman-1’s debut signals a shift in the global AI landscape. As a product of ByteDance, a Chinese tech giant, it challenges the dominance of Western companies like OpenAI and Google. This development underscores the rapid advancements being made by Chinese firms in the AI space, setting the stage for a new era of competition and innovation.
Looking ahead, we can expect OmniHuman-1 to evolve into even more sophisticated versions, potentially enabling real-time conversational avatars or applications in gaming and animation. One thing is clear: OmniHuman-1 is not just a step forward—it’s a giant leap for AI-generated video.

The Bottom Line
OmniHuman-1 represents a monumental achievement in AI-driven human animation. By combining cutting-edge technology with an innovative training strategy, it delivers lifelike, full-body animations that were once the stuff of science fiction. Whether it’s outperforming competitors like Sora and Veo or inspiring future advancements, OmniHuman-1 is a testament to the incredible pace of AI innovation. As ByteDance continues to push the boundaries, one thing is certain: the future of AI-generated video has never looked more exciting.
