How Attention-Based Mask Modeling and a New Dataset Are Redefining the Future of Motion Synthesis
- Motion Anything introduces an Attention-Based Mask Modeling approach, enabling fine-grained control over key frames and body parts in motion generation, outperforming existing methods.
- The framework integrates multiple modalities, such as text and music, to enhance coherence and controllability in generated motion sequences.
- A new Text-Music-Dance (TMD) dataset is introduced, doubling the size of existing benchmarks and providing a critical resource for future research in multimodal motion generation.

Motion generation has long been a cornerstone of computer vision, with applications spanning film production, video gaming, augmented and virtual reality (AR/VR), and human-robot interaction. Despite significant advancements, the field has struggled with two persistent challenges: prioritizing dynamic frames and body parts in autoregressive models and effectively integrating multiple conditioning modalities like text and music. Enter Motion Anything, a groundbreaking framework that addresses these limitations head-on, offering a new paradigm for motion generation that is both adaptive and controllable.

The Challenges in Motion Generation
Recent years have seen remarkable progress in conditional motion generation, particularly in text-to-motion and music-to-dance models. These advancements have demonstrated the potential to create realistic 3D motion sequences directly from textual descriptions or background music. However, existing methods often fall short in two critical areas. First, while masked autoregressive models have shown promise, they lack mechanisms to prioritize dynamic frames and body parts based on given conditions. This limitation results in less precise and less natural motion sequences. Second, integrating multiple modalities—such as text, music, and dance—remains a significant hurdle. Current approaches often fail to align these modalities effectively, leading to incoherent and less controllable outputs.
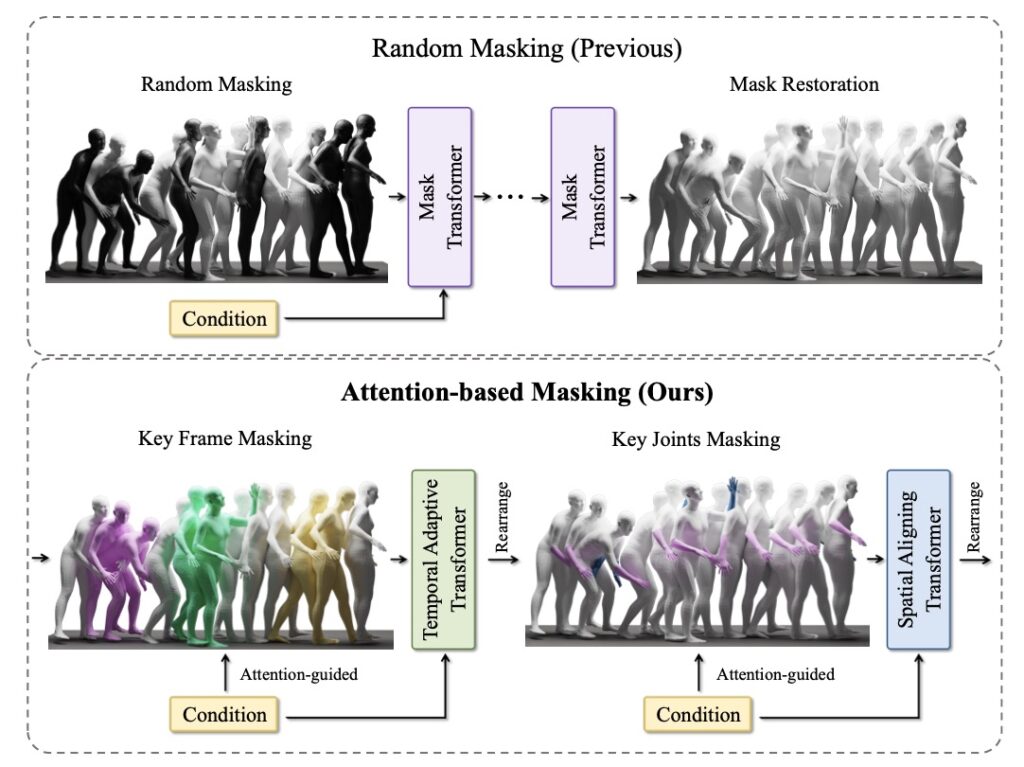
A Multimodal Solution
Motion Anything tackles these challenges with a novel Attention-Based Mask Modeling approach. This technique allows the model to focus on key frames and actions, ensuring that dynamic elements are prioritized during motion generation. By adaptively encoding multimodal conditions, such as text and music, the framework achieves unprecedented levels of control and coherence. For instance, a textual description like “a dancer performing a spin” can be seamlessly combined with a specific musical beat to generate a synchronized and realistic dance sequence.

One of the standout features of Motion Anything is its ability to integrate multiple modalities both temporally and spatially. This capability bridges the gap between different input types, enabling the model to produce motion sequences that are not only visually accurate but also contextually aligned with the given conditions. Whether it’s generating a dance routine that matches the rhythm of a song or creating a character animation that follows a detailed script, Motion Anything sets a new standard for precision and versatility.
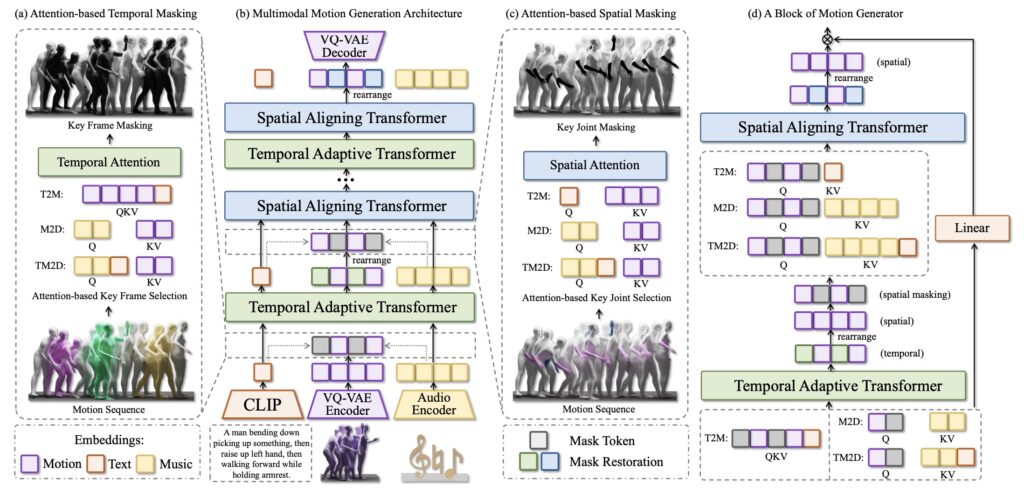
Introducing the Text-Music-Dance (TMD) Dataset
To support its innovative framework, the team behind Motion Anything has introduced the Text-Music-Dance (TMD) dataset, a pioneering resource for the research community. With 2,153 pairs of text, music, and dance, TMD is twice the size of the widely used AIST++ dataset. This new benchmark fills a critical gap in the field, providing researchers with a comprehensive dataset to train and evaluate multimodal motion generation models. The TMD dataset not only enhances the capabilities of Motion Anything but also serves as a valuable tool for future advancements in the field.
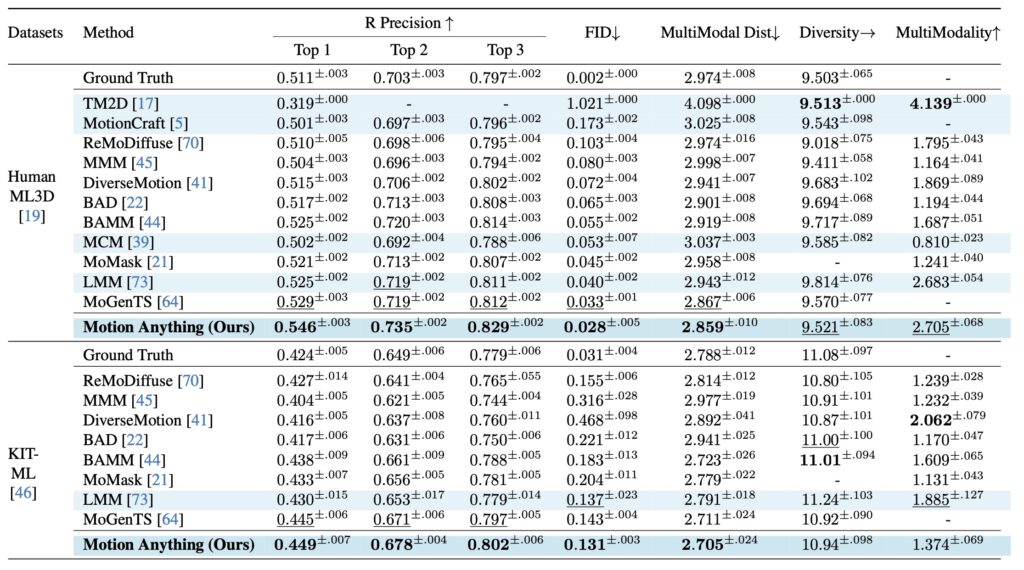
Performance and Impact
Extensive experiments demonstrate that Motion Anything outperforms state-of-the-art methods across multiple benchmarks. The framework achieves a 15% improvement in Fréchet Inception Distance (FID) on the HumanML3D dataset, a metric used to evaluate the quality of generated motion sequences. Additionally, it shows consistent performance gains on both AIST++ and the newly introduced TMD dataset. These results underscore the effectiveness of Motion Anything in generating high-quality, controllable motion sequences.

A New Paradigm for Motion Generation
Motion Anything represents a significant leap forward in motion generation. By addressing the limitations of existing methods, it offers a more versatile and precise framework for creating motion sequences. Its Attention-Based Mask Modeling approach ensures that dynamic frames and body parts are prioritized, while its ability to integrate multiple modalities enhances coherence and control. The introduction of the TMD dataset further solidifies its impact, providing a critical resource for future research.

As the demand for realistic and controllable motion generation continues to grow—driven by applications in entertainment, robotics, and beyond—Motion Anything stands out as a transformative solution. By redefining how we approach motion synthesis, it paves the way for a future where generated motion is not only realistic but also deeply aligned with the conditions that guide it.

Motion Anything is more than just a technological advancement; it’s a glimpse into the future of how we create and interact with motion in digital environments. Whether you’re a filmmaker, game developer, or AI researcher, this framework offers the tools to bring your vision to life with unprecedented precision and creativity.