How MiMo-7B Redefines Reasoning from Pretraining to Posttraining
- MiMo-7B is a new 7B-parameter language model series, designed from scratch for advanced reasoning, outperforming much larger models in both mathematics and code tasks.
- The project pioneers a dual focus: optimizing pretraining for reasoning and innovating posttraining with reinforcement learning (RL) techniques, including dense reward signals and efficient rollout strategies.
- MiMo-7B is fully open-sourced, offering checkpoints and insights that empower the community to build more powerful, efficient, and accessible reasoning LLMs.
In the rapidly evolving world of large language models (LLMs), the quest for models that can reason as well as they can generate text has become a central challenge. Traditionally, the most successful reinforcement learning (RL) approaches have relied on massive base models—often 32 billion parameters or more—especially when it comes to complex code reasoning. The prevailing wisdom has been that smaller models simply can’t keep up, particularly when it comes to excelling at both mathematics and code tasks simultaneously. But what if the secret to unlocking true reasoning power lies not just in the size of the model, but in how it’s trained from the very beginning?
Enter Xiaomi’s MiMo-7B, a groundbreaking series of models that challenge the status quo. Rather than scaling up endlessly, MiMo-7B focuses on maximizing the reasoning potential of a compact 7B-parameter architecture. The key innovation? A holistic approach that treats both pretraining and posttraining as critical levers for reasoning, rather than relying solely on RL fine-tuning after the fact.
Rethinking Pretraining: Building a Model Born for Reasoning
The MiMo-7B journey starts with a radical reimagining of the pretraining process. Instead of generic text corpora, the team optimized their data pipeline to extract and filter for reasoning-rich content. Enhanced text extraction tools and multi-dimensional data filtering were used to ensure that the pretraining data was dense with reasoning patterns. To further boost diversity and depth, the team generated massive amounts of synthetic reasoning data, ensuring the model was exposed to a wide array of logical challenges from the outset.
A three-stage data mixture strategy was employed, ultimately pretraining MiMo-7B-Base on an astonishing 25 trillion tokens. But the innovation didn’t stop there. The team incorporated Multiple-Token Prediction (MTP) as an additional training objective, which not only improved the model’s performance but also accelerated inference—a crucial advantage for real-world applications.
Smarter RL for Smarter Models
While pretraining laid the foundation, MiMo-7B’s posttraining phase pushed the boundaries of what’s possible with RL. The team curated a dataset of 130,000 mathematics and code problems, each carefully cleaned and assessed for difficulty. To ensure the integrity of the training process, only rule-based accuracy rewards were used, sidestepping the pitfalls of reward hacking.
One of the standout innovations was the introduction of a test difficulty-driven code reward. By assigning nuanced, fine-grained scores to test cases of varying difficulty, the model received a much denser and more informative reward signal. This approach proved especially effective for challenging code problems, where traditional sparse rewards often leave models floundering.
To further optimize training, a data re-sampling strategy was implemented for easier problems, enhancing rollout sampling efficiency and stabilizing policy updates—especially in the later stages of RL training.
The Seamless Rollout Engine
Behind the scenes, MiMo-7B’s RL infrastructure is a marvel of engineering. The Seamless Rollout Engine was developed to accelerate both training and validation, integrating continuous rollout, asynchronous reward computation, and early termination. This design minimized GPU idle time, resulting in training that was 2.29 times faster and validation that was 1.96 times faster than previous approaches.
Support for Multiple-Token Prediction in vLLM and enhanced inference engine robustness further solidified MiMo-7B’s position as a state-of-the-art reasoning model.
Results and Open Source Impact
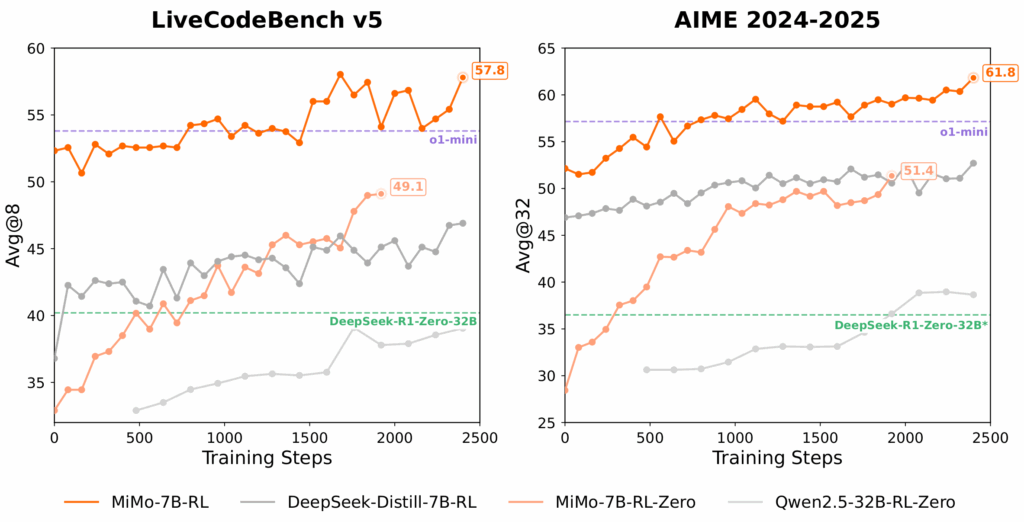
The results speak for themselves. MiMo-7B-Base demonstrated extraordinary reasoning potential, even surpassing much larger 32B models in both mathematics and code reasoning tasks. The RL-trained MiMo-7B-RL matched the performance of OpenAI’s o1-mini, a remarkable achievement for a model of its size.
Perhaps most importantly, Xiaomi has open-sourced the entire MiMo-7B series, including checkpoints for the base model, SFT model, RL model trained from the base, and RL model trained from the SFT. This commitment to transparency and community empowerment ensures that the insights and innovations behind MiMo-7B will benefit researchers and developers worldwide.
MiMo-7B is more than just a new model—it’s a blueprint for the future of reasoning in language models. By rethinking both pretraining and posttraining, and by sharing their work openly, the MiMo-7B team has set a new standard for what’s possible with compact, efficient, and powerful LLMs. As the community builds on these foundations, the dream of truly intelligent, reasoning-capable AI comes ever closer to reality.