Discover how this 270-million parameter powerhouse is making specialized AI accessible, energy-efficient, and ready for real-world deployment.
- Compact Powerhouse for Specialization: Gemma 3 270M is a lightweight model optimized for task-specific fine-tuning, boasting a large vocabulary and strong instruction-following capabilities, making it ideal for domains like text classification, data extraction, and creative applications.
- Unmatched Efficiency and Privacy: With extreme energy savings—using just 0.75% battery for 25 conversations on devices like the Pixel 9 Pro—and on-device deployment options, it slashes costs, speeds up responses, and ensures user data privacy without cloud reliance.
- Empowering Developers Worldwide: Building on the Gemma family’s success with over 200 million downloads, this model enables quick fine-tuning and deployment, fostering a “fleet” of specialized AI tools for high-volume tasks, from enterprise moderation to bedtime story generators.
In the fast-evolving world of artificial intelligence, where bigger often seems better, Google’s Gemma family is flipping the script by proving that efficiency and specialization can outperform raw scale. The last few months have been a whirlwind for open AI models, with the introduction of Gemma 3 and its quantized variant, Gemma 3 QAT, setting new benchmarks for performance on cloud and desktop accelerators. Hot on their heels came Gemma 3n, a mobile-first architecture that brings real-time multimodal AI straight to edge devices. This surge of innovation has fueled a vibrant “Gemmaverse”—a community of developers who’ve pushed downloads past 200 million, creating everything from practical tools to imaginative apps. Today, we’re thrilled to unveil the latest addition: Gemma 3 270M, a hyper-compact 270-million parameter model that’s engineered for precision, power efficiency, and seamless fine-tuning. It’s not just another model; it’s a testament to how targeted AI can transform industries, from mobile apps to enterprise solutions, all while keeping things lean and green.
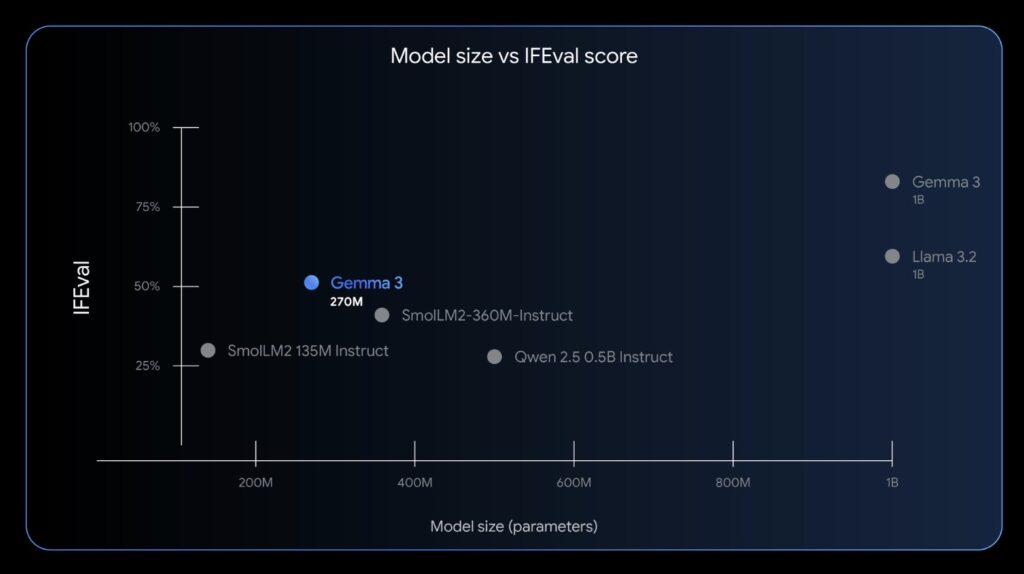
At its core, Gemma 3 270M is built for developers who need a “right tool for the job” approach, echoing the engineering principle that efficiency trumps brute force. Picture this: you wouldn’t grab a sledgehammer to hang a picture frame, right? Similarly, this model shuns unnecessary complexity in favor of a streamlined architecture with 170 million embedding parameters (thanks to a massive 256k-token vocabulary) and 100 million for its transformer blocks. This setup allows it to handle rare and specific tokens effortlessly, making it a stellar base for fine-tuning in niche domains or languages. But what truly sets it apart is its extreme energy efficiency—internal tests on a Pixel 9 Pro SoC revealed that the INT4-quantized version sips just 0.75% of the battery for 25 full conversations. That’s not just impressive; it’s a game-changer for battery-conscious devices, positioning Gemma 3 270M as the most power-efficient in the Gemma lineup.
Beyond its slim profile, the model comes ready-to-use with strong instruction-following baked in. We’re releasing both a pre-trained checkpoint and an instruction-tuned version, so it can tackle general tasks straight out of the box—think following prompts for text structuring or basic queries. While it’s not geared for intricate conversations, its production-ready quantization (via Quantization-Aware Training, or QAT) ensures it runs at INT4 precision with barely any performance hit. This makes deployment on resource-strapped hardware a breeze, whether you’re building for smartphones, IoT devices, or low-cost servers. In a broader sense, this reflects a shift in the AI landscape: as models grow larger and more energy-hungry, compact options like Gemma 3 270M are democratizing access, allowing smaller teams and indie developers to compete without massive budgets or infrastructure.
The real magic happens when you fine-tune Gemma 3 270M for specific tasks, unlocking accuracy, speed, and cost savings that rival—or surpass—much larger models. Take the inspiring case of Adaptive ML and SK Telecom: tasked with nuanced, multilingual content moderation, they fine-tuned a Gemma 3 4B model (a sibling in the family) and achieved results that outshone proprietary giants. Gemma 3 270M takes this specialization even further, enabling developers to craft a “fleet” of tiny experts—each honed for jobs like sentiment analysis, entity extraction, query routing, or turning unstructured text into structured data. It’s not limited to corporate use either; imagine creative gems like a Bedtime Story Generator web app, where the model spins personalized tales on the fly. From a wider perspective, this approach aligns with global trends in sustainable AI, reducing the environmental footprint of inference while boosting innovation in areas like compliance checks and creative writing.
So, when should you reach for Gemma 3 270M? It’s the go-to choice for high-volume, well-defined tasks where every millisecond and micro-cent matters. If you’re dealing with sentiment analysis, extracting entities from text, routing queries efficiently, processing unstructured data into structured formats, generating creative content, or running compliance checks, this model shines. Its small size means you can iterate and deploy in hours, not days, slashing inference costs dramatically—sometimes eliminating them entirely by running on lightweight infrastructure or directly on-device. Privacy is another huge win: with full on-device capabilities, sensitive data never leaves the user’s hardware, addressing growing concerns in an era of data breaches and regulations. Ultimately, it’s perfect for building that fleet of specialized models without draining your resources, embodying the Gemma ethos that innovation thrives in all sizes.
Getting started couldn’t be simpler, thanks to the model’s compatibility with the broader Gemma 3 ecosystem. Dive into our comprehensive guide on full fine-tuning in the Gemma docs, which includes recipes and tools tailored for this compact powerhouse. Download the pre-trained or instruction-tuned versions from platforms like Hugging Face, Ollama, Kaggle, LM Studio, or Docker. Test it out on Vertex AI or with inference engines such as llama.cpp, Gemma.cpp, LiteRT, Keras, and MLX. For fine-tuning, leverage favorites like Hugging Face, UnSloth, or JAX to customize it swiftly. Once ready, deploy anywhere—from your local setup to Google Cloud Run—ensuring your AI solution is fast, efficient, and scalable.
As the Gemmaverse continues to expand, Gemma 3 270M stands as a beacon for smarter, more sustainable AI development. It’s empowering creators to build lean systems that deliver outsized impact, proving that in the world of AI, sometimes the smallest tools pack the biggest punch. We can’t wait to see the specialized wonders you’ll create—whether it’s moderating global content, crafting bedtime stories, or solving tomorrow’s challenges with hyper-efficient intelligence. Join the movement and let’s make AI work for everyone, one fine-tuned model at a time.