How a groundbreaking diffusion model and massive dataset are transforming 3D environments for design, gaming, and robotics
- Bridging the Gap in 3D Scene Generation: SpatialGen introduces a multi-view multi-modal diffusion model that creates realistic, semantically consistent 3D indoor scenes from user-provided layouts and text prompts, overcoming longstanding challenges in visual quality, diversity, and control.
- Empowering Innovation with Open Data: Backed by a vast synthetic dataset of 12,328 annotated scenes, 57,440 rooms, and 4.7 million photorealistic renderings, this framework is being open-sourced to accelerate advancements in virtual reality, interior design, and robotic simulations.
- Balancing Realism and Creativity: By addressing trade-offs between procedural methods’ precision and generative AI’s diversity, SpatialGen paves the way for immersive applications while acknowledging limitations like computational demands, setting the stage for future enhancements.
In an age where virtual reality headsets transport us to fantastical realms and robots navigate our homes with increasing autonomy, the ability to generate lifelike 3D indoor environments has never been more crucial. Imagine designing your dream kitchen without lifting a hammer, or training a robot to avoid furniture in a simulated living room that feels eerily real. Yet, for years, creating these high-fidelity 3D models has been a painstaking manual process—time-consuming, labor-intensive, and often out of reach for many. Enter SpatialGen, a pioneering framework that’s flipping the script on indoor scene generation. Developed during an internship at Manycore Tech Inc., this layout-guided 3D indoor scene generation tool leverages cutting-edge generative AI to produce spatially coherent and photorealistic environments, all while giving users unprecedented control.
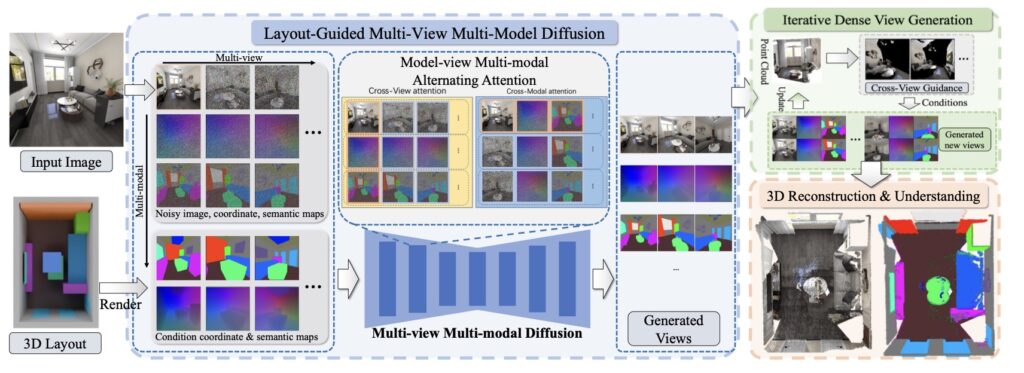
At its heart, SpatialGen tackles a fundamental challenge in computer vision: synthesizing 3D scenes that are not only visually stunning but also semantically consistent across multiple views. Traditional methods, like procedural modeling, rely on hand-crafted rules and geometric constraints within graphics engines to ensure physical plausibility—think perfectly aligned walls and gravity-defying furniture avoidance.
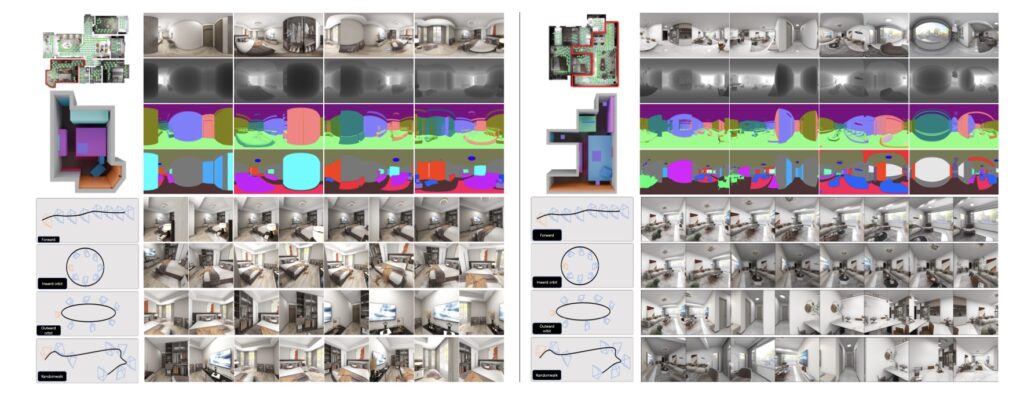
What sets SpatialGen apart is its innovative multi-view multi-modal diffusion model, which generates appearance (color images), geometry (scene coordinate maps), and semantics (semantic segmentation maps) from arbitrary viewpoints. Starting with a 3D layout and a reference image derived from a simple text prompt, the model ensures everything aligns spatially across modalities—meaning the red couch in one view doesn’t mysteriously turn blue in another. This preserves multi-view semantic consistency, a hurdle that even advanced video generation methods struggle with when venturing beyond initial inputs. The result? Scenes that feel alive and immersive, perfect for applications in immersive films, games, interior design, augmented/virtual reality (AR/VR), and even robotic simulations where diverse, physically realistic environments are key for training navigation and interaction skills.
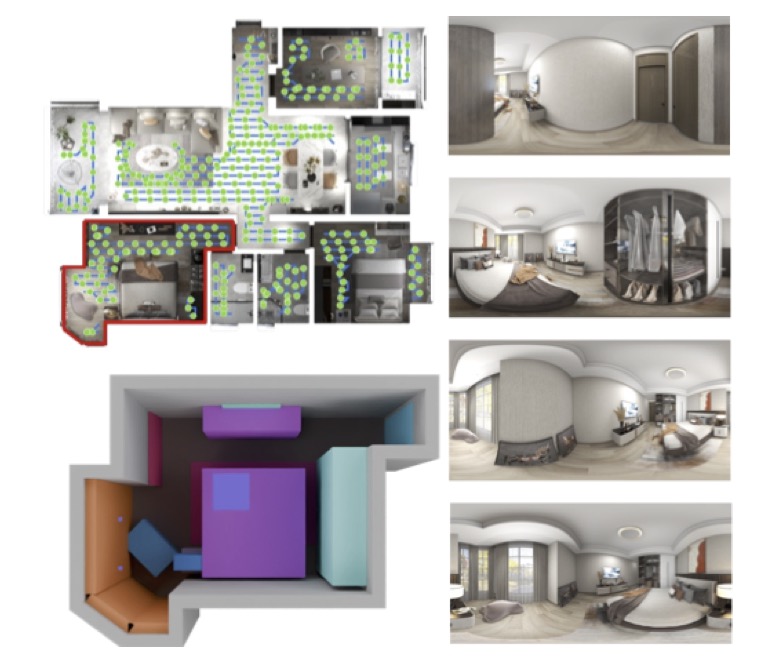
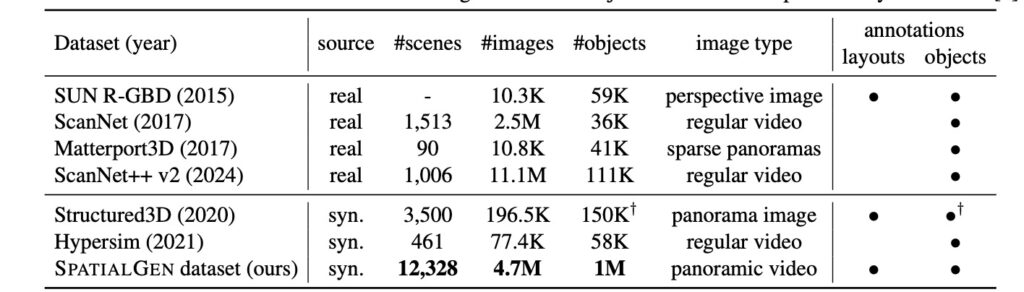
Fueling this powerhouse is the SpatialGen Dataset, a game-changing resource addressing the critical bottleneck of data scarcity. This large-scale synthetic dataset boasts 12,328 structured annotated scenes encompassing 57,440 rooms, paired with an astonishing 4.7 million photorealistic 2D renderings. To create it, researchers engineered physically plausible camera trajectories that weave smoothly through each scene, dodging obstacles and sampling viewpoints at 0.5-meter intervals for comprehensive coverage. For every viewpoint, an industry-leading rendering engine captures not just color images but also depth, normal, semantic, and instance segmentation data—providing a rich, multi-faceted foundation for training. This isn’t just data; it’s a treasure trove that enables models like SpatialGen to learn the nuances of real-world indoor spaces, from cozy bedrooms to sprawling offices.
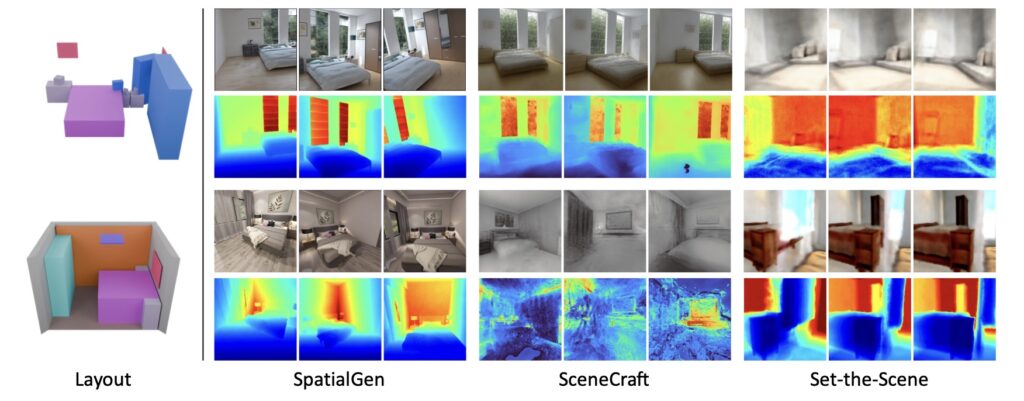
The broader implications of SpatialGen extend far beyond tech labs. In interior design, professionals can iterate on layouts in virtual spaces, experimenting with colors and arrangements without physical prototypes. For the gaming industry, it means crafting endless, diverse worlds that keep players engaged. In robotics, simulated environments generated by SpatialGen could train AI systems to handle unpredictable real-world scenarios, like a cluttered kitchen or a dimly lit hallway, enhancing safety and efficiency. Even in AR/VR, where immersion is everything, the model’s ability to balance realism with creative diversity opens doors to more personalized and interactive experiences. Experiments show SpatialGen outperforming previous methods in visual quality and consistency, proving its edge in a field hungry for innovation.
Of course, no breakthrough is without its hurdles. SpatialGen’s cross-view and cross-modal attention mechanisms, while essential for consistency, add computational overhead, limiting the model to generating a smaller number of images at once. Additionally, the camera sampling strategy can influence output quality, potentially leading to inconsistencies if not optimized. The team behind SpatialGen acknowledges these limitations and plans to refine them in future iterations, perhaps by streamlining computations or improving trajectory algorithms. By open-sourcing both the dataset and models, they’re inviting the global community to collaborate, iterate, and push the boundaries of indoor scene understanding and generation.

SpatialGen isn’t just a tool—it’s a catalyst for a future where creating virtual worlds is as intuitive as describing them. As generative AI continues to evolve, frameworks like this remind us that the line between imagination and reality is blurring, one pixel-perfect room at a time. Whether you’re a designer dreaming up spaces, a developer building the next big game, or a researcher advancing embodied AI, SpatialGen offers the keys to unlock endless possibilities.